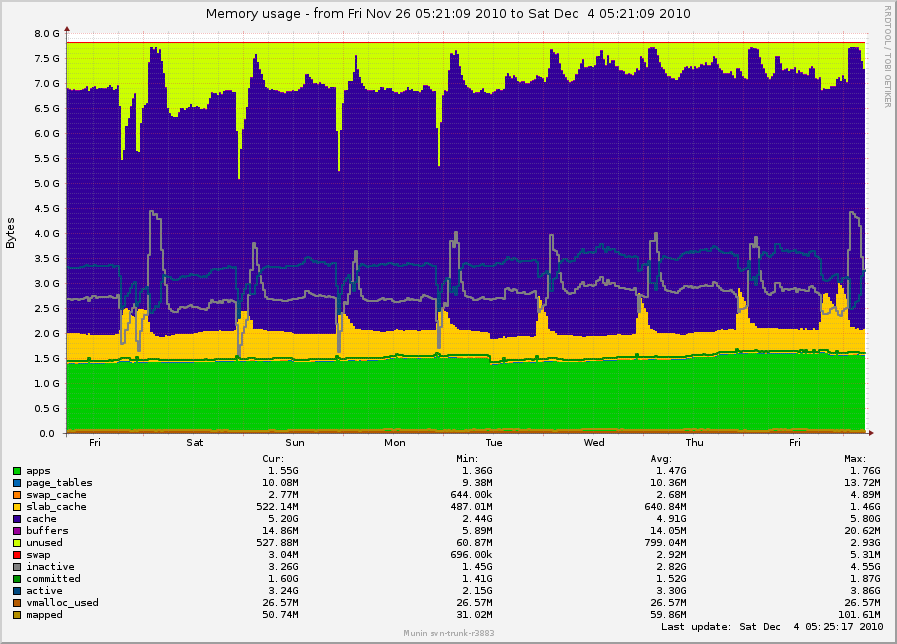
On Fri, Dec 10, 2010 at 11:32:45AM +0000, Mel Gorman wrote: > On Thu, Dec 09, 2010 at 03:44:52PM -0800, Simon Kirby wrote: > > On Mon, Dec 06, 2010 at 12:03:42PM +0000, Mel Gorman wrote: > > > > > But there is still potentially two problems here. The first was kswapd > > > throwing out everything in zone normal. Even when fixed, there is > > > potentially still too many pages being thrown out. The situation might > > > be improved but not repaired. > > > > Yes. > > > > > > Let me clarify: On _another_ box, with 2.6.36 but without your patches > > > > and without as much load or SSD devices, I forced slub to use order-0 > > > > except where order-1 was absolutely necessary (objects > 4096 bytes), > > > > just to see what impact this had on free memory. There was a change, > > > > but still lots of memory left free. I was trying to avoid confusion by > > > > posting graphs from different machines, but here is that one just as a > > > > reference: http://0x.ca/sim/ref/2.6.36/memory_stor25r_week.png > > > > (I made the slub order adjustment on Tuesday, November 30th.) > > > > The spikes are actually from mail nightly expunge/purge runs. It seems > > > > that minimizing the slub orders did remove the large free spike that > > > > was happening during mailbox compaction runs (nightly), and overall there > > > > was a bit more memory used on average, but it definitely didn't "fix" it. > > > > > > Ok, but it's still evidence that lumpy reclaim is still the problem here. This > > > should be "fixed" by reclaim/compaction which has less impact and frees > > > fewer pages than lumpy reclaim. If necessary, I can backport this to 2.6.36 > > > for you to verify. There is little chance the series would be accepted into > > > -stable but you'd at least know that 2.6.37 or 2.6.38 would behave as expected. > > > > Isn't lumpy reclaim supposed to _improve_ this situation by trying to > > free contiguous stuff rather than shooting aimlessly until contiguous > > pages appear? > > For lower orders like order-1 and order-2, it reclaims randomly before > using lumpy reclaim as the assumption is that these lower pages free > naturally. Hmm.. We were looking were looking at some other servers' munin graphs, and I seem to notice a correlation between high allocation rates (eg, heavily loaded servers) and more memory being free. I am wondering if the problem isn't the choice of how to reclaim, but more an issue from concurrent allocation calls. Because (direct) reclaim isn't protected from other allocations, it can fight with allocations that split back up the orders, which might be increasing fragmentation. The fragmentation and reaching watermarks does seem to be what is causing a larger amount to stay free, once it _gets_ fragmented... I was thinking of ways that it could hold pages while reclaiming, and then free them all and allocate the request under a lock to avoid colliding with other allocations. I see shrink_active_list() almost seems to have something like this with l_hold, but nothing cares about watermarks down at that level. The inactive list goes through a separate routine, and only inactive uses lumpy reclaim. > > Or is there some other point to it? If this is the case, > > maybe the issue is that lumpy reclaim isn't happening soon enough, so it > > shoots around too much before it tries to look for lumpy stuff. > > It used to happen sooner but it ran into latency problems. Latency from writeback or something? I wonder if it would be worth trying a cheap patch to try lumpy mode immediately, just to see how things change. > > In > > 2.6.3[67], set_lumpy_reclaim_mode() only sets lumpy mode if sc->order > > > PAGE_ALLOC_COSTLY_ORDER (>= 4), or if priority < DEF_PRIORITY - 2. > > > > Also, try_to_compact_pages() bails without doing anything when order <= > > PAGE_ALLOC_COSTLY_ORDER, which is the order I'm seeing problems at. So, > > without further chanegs, I don't see how CONFIG_COMPACTION or 2.6.37 will > > make any difference, unless I'm missing some related 2.6.37 changes. > > There is increasing pressure to use compaction for the lower orders as > well. This problem is going to be added to the list of justifications :/ I figured perhaps this was skipped due to being expensive, or else why wouldn't it just always happen for non-zero orders. I do see a lot of servers with 200,000 free order-0 pages and almost no order-1 or anything bigger, so maybe this could help. I could try to modify the test in try_to_compact_pages() to if (!order || !may_enter_fs || !may_perform_io). Simon- -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxxx For more info on Linux MM, see: http://www.linux-mm.org/ . Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/ Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}