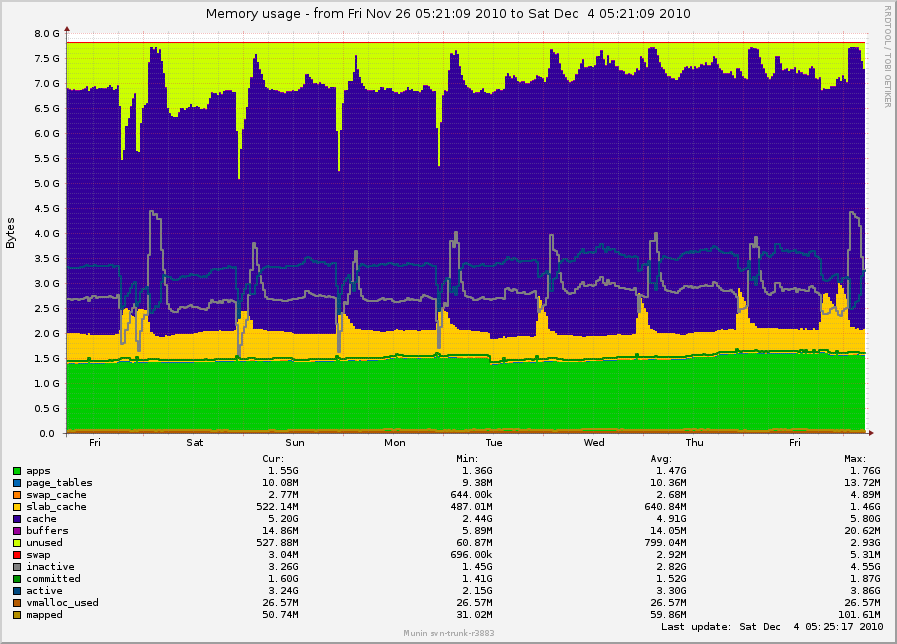
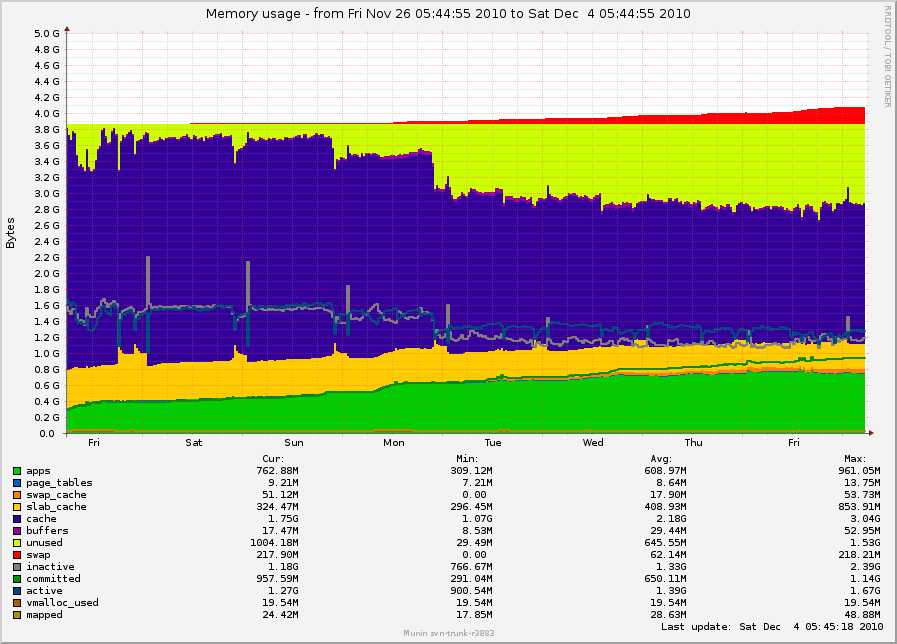
On Thu, Dec 09, 2010 at 03:44:52PM -0800, Simon Kirby wrote: > On Mon, Dec 06, 2010 at 12:03:42PM +0000, Mel Gorman wrote: > > > > This was part of the problem. kswapd was throwing so much out while > > > trying to meet the watermark in zone Normal that the daemons had to keep > > > being read back in from /dev/sda (non-ssd), and this ended up causing > > > degraded performance. > > > > But there is still potentially two problems here. The first was kswapd > > throwing out everything in zone normal. Even when fixed, there is > > potentially still too many pages being thrown out. The situation might > > be improved but not repaired. > > Yes. > > > > > Before you said SLUB was using only order-0 and order-1, I would have > > > > suspected lumpy reclaim. Without high-order allocations, fragmentation > > > > is not a problem and shouldn't be triggering a mass freeing of memory. > > > > can you confirm with perf that there is no other constant source of > > > > high-order allocations? > > > > > > Let me clarify: On _another_ box, with 2.6.36 but without your patches > > > and without as much load or SSD devices, I forced slub to use order-0 > > > except where order-1 was absolutely necessary (objects > 4096 bytes), > > > just to see what impact this had on free memory. There was a change, > > > but still lots of memory left free. I was trying to avoid confusion by > > > posting graphs from different machines, but here is that one just as a > > > reference: http://0x.ca/sim/ref/2.6.36/memory_stor25r_week.png > > > (I made the slub order adjustment on Tuesday, November 30th.) > > > The spikes are actually from mail nightly expunge/purge runs. It seems > > > that minimizing the slub orders did remove the large free spike that > > > was happening during mailbox compaction runs (nightly), and overall there > > > was a bit more memory used on average, but it definitely didn't "fix" it. > > > > Ok, but it's still evidence that lumpy reclaim is still the problem here. This > > should be "fixed" by reclaim/compaction which has less impact and frees > > fewer pages than lumpy reclaim. If necessary, I can backport this to 2.6.36 > > for you to verify. There is little chance the series would be accepted into > > -stable but you'd at least know that 2.6.37 or 2.6.38 would behave as expected. > > Isn't lumpy reclaim supposed to _improve_ this situation by trying to > free contiguous stuff rather than shooting aimlessly until contiguous > pages appear? For lower orders like order-1 and order-2, it reclaims randomly before using lumpy reclaim as the assumption is that these lower pages free naturally. > Or is there some other point to it? If this is the case, > maybe the issue is that lumpy reclaim isn't happening soon enough, so it > shoots around too much before it tries to look for lumpy stuff. It used to happen sooner but it ran into latency problems. > In > 2.6.3[67], set_lumpy_reclaim_mode() only sets lumpy mode if sc->order > > PAGE_ALLOC_COSTLY_ORDER (>= 4), or if priority < DEF_PRIORITY - 2. > > Also, try_to_compact_pages() bails without doing anything when order <= > PAGE_ALLOC_COSTLY_ORDER, which is the order I'm seeing problems at. So, > without further chanegs, I don't see how CONFIG_COMPACTION or 2.6.37 will > make any difference, unless I'm missing some related 2.6.37 changes. > There is increasing pressure to use compaction for the lower orders as well. This problem is going to be added to the list of justifications :/ > > > There are definitely pages that are leaking from dovecot or similar which > > > can be swapped out and not swapped in again (you can see "apps" growing), > > > but there are no tasks I can think of that would ever cause the system to > > > be starved. > > > > So dovecot has a memory leak? As you say, this shouldn't starve the system > > but it's inevitable that swap usage will grow over time. > > Yeah, we just squashed what seemed to be the biggest leak in dovecot, so > this should stop happening once we rebuild and restart everything. > Ok. > > > The calls to pageout() seem to happen if sc.may_writepage is > > > set, which seems to happen when it thinks it has scanned enough without > > > making enough progress. Could this happen just from too much > > > fragmentation? > > > > > > > Not on its own but if too many pages have to be scanned due to > > fragmentation, it can get set. > > > > > The swapping seems to be at a slow but constant rate, so maybe it's > > > > I assume you mean swap usage is growing at a slow but constant rate? > > Yes. > > > > happening just due to the way the types of allocations are biasing to > > > Normal instead of DMA32, or vice-versa. > > > Check out the latest memory > > > graphs for the server running your original patch: > > > > > > http://0x.ca/sim/ref/2.6.36/memory_mel_patch_dec4.png > > > > Do you think the growth in swap usage is due to dovecot leaking? > > I guess we'll find out shortly, with dovecot being fixed. :) > Great. > > > http://0x.ca/sim/ref/2.6.36/zoneinfo_mel_patch_dec4 > > > http://0x.ca/sim/ref/2.6.36/pagetypeinfo_mel_patch_dec4 > > > > > > Hmm, pagetypeinfo shows none or only a few of the pages in Normal are > > > considered reclaimable... > > > > > > > Reclaimable in the context of pagetypeinfo means slab-reclaimable. The > > results imply that very few slab allocations are being satisified from > > the Normal zone or at least very few have been released recently. > > Hmm, ok. > > Simon- > -- Mel Gorman Part-time Phd Student Linux Technology Center University of Limerick IBM Dublin Software Lab -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxxx For more info on Linux MM, see: http://www.linux-mm.org/ . Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/ Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}
{kind=link}