On Thu, Dec 02, 2010 at 12:53:42PM -0800, Simon Kirby wrote:
> On Thu, Dec 02, 2010 at 03:42:35PM +0000, Mel Gorman wrote:
>
> > On Fri, Dec 03, 2010 at 12:35:26AM +0900, Minchan Kim wrote:
> > > > > @@ -2550,8 +2558,13 @@ static int kswapd(void *p)
> > > > > */
> > > > > order = new_order;
> > > > > } else {
> > > > > - kswapd_try_to_sleep(pgdat, order);
> > > > > - order = pgdat->kswapd_max_order;
> > > > > + /*
> > > > > + * If we wake up after enough sleeping, let's
> > > > > + * start new order. Otherwise, it was a premature
> > > > > + * sleep so we keep going on.
> > > > > + */
> > > > > + if (kswapd_try_to_sleep(pgdat, order))
> > > > > + order = pgdat->kswapd_max_order;
> > > >
> > > > Ok, we lose the old order if we slept enough. That is fine because if we
> > > > slept enough it implies that reclaiming at that order was no longer
> > > > necessary.
> > > >
> > > > This needs a repost with a full changelog explaining why order has to be
> > > > preserved if kswapd fails to go to sleep. There will be merge difficulties
> > > > with the series aimed at fixing Simon's problem but it's unavoidable.
> > > > Rebasing on top of my series isn't an option as I'm still patching
> > > > against mainline until that issue is resolved.
> > >
> > > So what's your point?
> >
> > Only point was to comment "I think this part of the patch is fine".
> >
> > > Do you want me to send this patch alone
> > > regardless of your series for Simon's problem?
> > >
> >
> > Yes, because I do not believe the problems are directly related. When/if
> > I get something working with Simon, I'll backport your patch on top of it
> > for testing by him just in case but I don't think it'll affect him.
>
> We could test this and your patch together, no?
> Your patch definitely
> fixed the case for us where kswapd would just run all day long, throwing
> out everything while trying to reach the order-3 watermark in zone Normal
> while order-0 page cache allocations were splitting it back out again.
>
Ideally they would ultimately be tested together, but I'd really like to
hear if the 5 patch series I posted still prevents kswapd going crazy
and if the "too much free memory" problem is affected. Minimally, fixing
kswapd being awake is worthwhile.
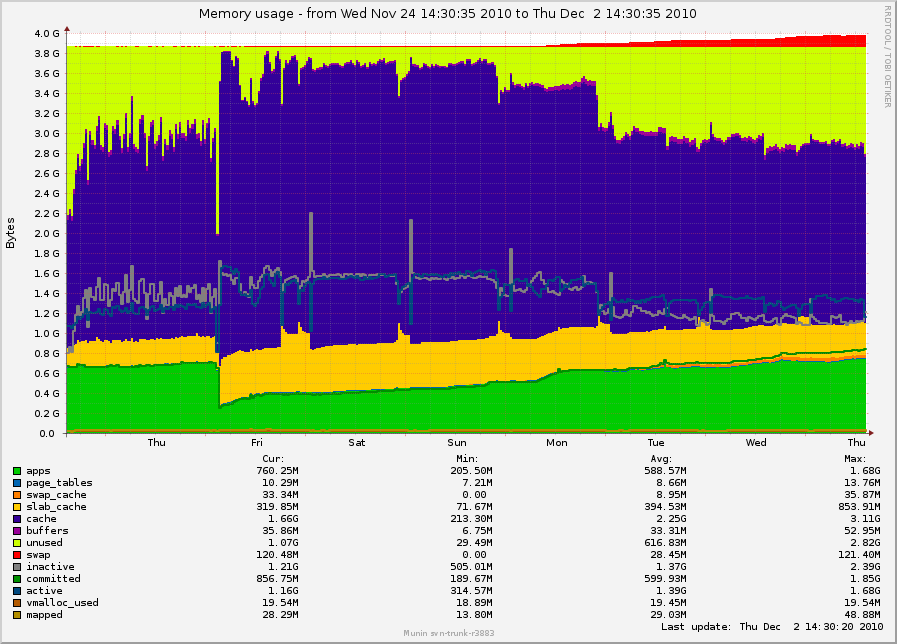
> However, the subject of my original post was to do with too much free
> memory and swap, which is still occurring:
>
> http://0x.ca/sim/ref/2.6.36/memory_mel_patch_week.png
>
Ok, we had been working on the assumption that kswapd staying awake was
responsible for too much memory being free. If after the series is applied and
working there is still too much free memory, we know there is an additional
part to the problem.
> But this is still occurring even if I tell slub to use only order-0 and
> order-1, and disable jumbo frames (which I did on another box, not this
> one). It may not be quite as bad, but I think the increase in free
> memory is just based on fragmentation that builds up over time.
Before you said SLUB was using only order-0 and order-1, I would have
suspected lumpy reclaim. Without high-order allocations, fragmentation
is not a problem and shouldn't be triggering a mass freeing of memory.
can you confirm with perf that there is no other constant source of
high-order allocations?
> I don't
> have any long-running graphs of this yet, but I can see that pretty much
> all of the free memory always is order-0, and even a "while true; do
> sleep .01; done" is enough to make it throw out more order-0 while trying
> to make room for order-1 task_struct allocations.
>
It would be semi-normal to throw out a few pages for order-1 task_struct
allocations. Is your server fork-heavy? I would have guessed "no" as you
are forcing a large number of forks with the while loop.
> Maybe some pattern in the way that pages are reclaimed while they are
> being allocated is resulting in increasing fragmentation? All the boxes
> I see this on start out fine, but after a day or week they end up in swap
> and with lots of free memory.
>
Is there something like a big weekly backup task running that would be
responsible for pushing a large amount of memory to swap that is never
faulted back in again because it's unused?
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
--
To unsubscribe, send a message with 'unsubscribe linux-mm' in
the body to majordomo@xxxxxxxxxx For more info on Linux MM,
see: http://www.linux-mm.org/ .
Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/
Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}