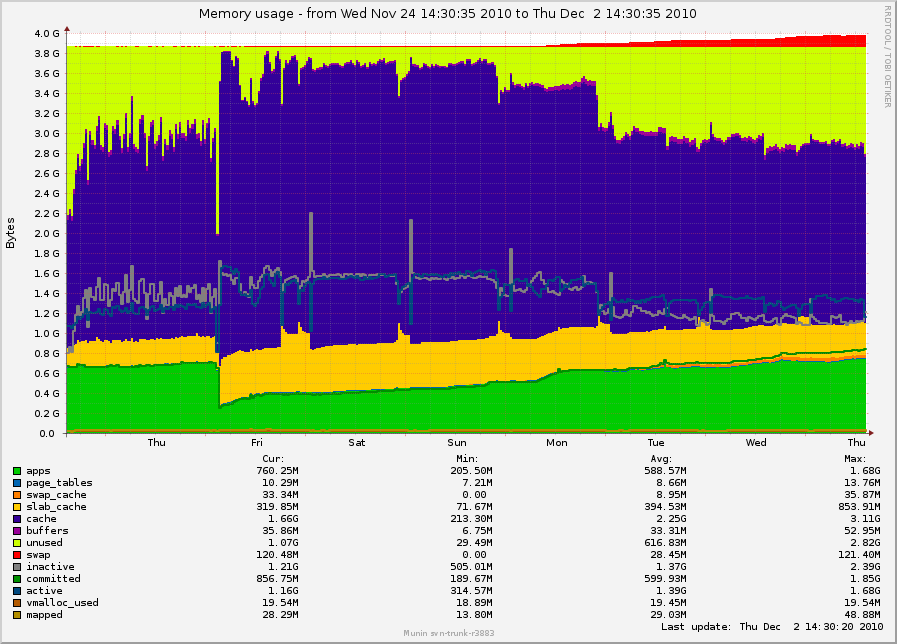
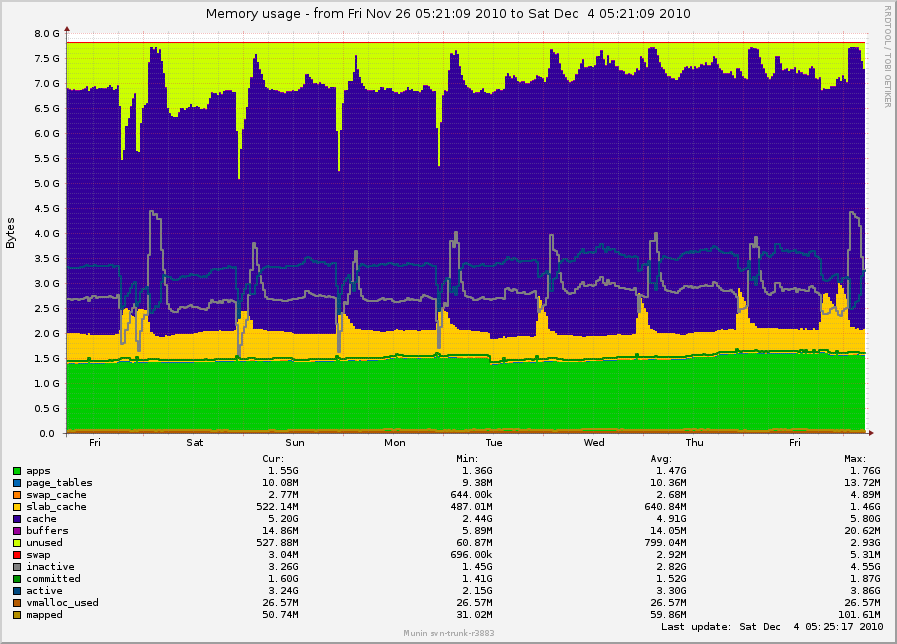
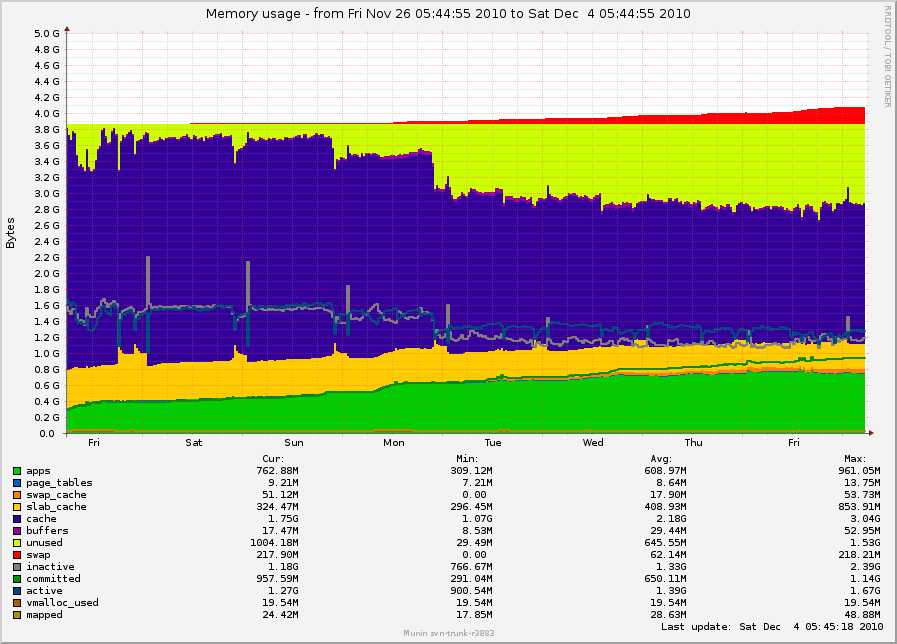
On Fri, Dec 03, 2010 at 12:00:54PM +0000, Mel Gorman wrote: > On Thu, Dec 02, 2010 at 12:53:42PM -0800, Simon Kirby wrote: > > On Thu, Dec 02, 2010 at 03:42:35PM +0000, Mel Gorman wrote: > > > > > On Fri, Dec 03, 2010 at 12:35:26AM +0900, Minchan Kim wrote: > > > > > > Only point was to comment "I think this part of the patch is fine". > > > > > > > Do you want me to send this patch alone > > > > regardless of your series for Simon's problem? > > > > > > Yes, because I do not believe the problems are directly related. When/if > > > I get something working with Simon, I'll backport your patch on top of it > > > for testing by him just in case but I don't think it'll affect him. > > > > We could test this and your patch together, no? > > Your patch definitely > > fixed the case for us where kswapd would just run all day long, throwing > > out everything while trying to reach the order-3 watermark in zone Normal > > while order-0 page cache allocations were splitting it back out again. > > > > Ideally they would ultimately be tested together, but I'd really like to > hear if the 5 patch series I posted still prevents kswapd going crazy > and if the "too much free memory" problem is affected. Minimally, fixing > kswapd being awake is worthwhile. Ok, we will try this version of your patches and see if anything changes. The previous version did stop kswapd from running continuously during daytime load, and made our SSD server useful, so I definitely like it. :) > > However, the subject of my original post was to do with too much free > > memory and swap, which is still occurring: > > > > http://0x.ca/sim/ref/2.6.36/memory_mel_patch_week.png > > Ok, we had been working on the assumption that kswapd staying awake was > responsible for too much memory being free. If after the series is applied and > working there is still too much free memory, we know there is an additional > part to the problem. This was part of the problem. kswapd was throwing so much out while trying to meet the watermark in zone Normal that the daemons had to keep being read back in from /dev/sda (non-ssd), and this ended up causing degraded performance. > > But this is still occurring even if I tell slub to use only order-0 and > > order-1, and disable jumbo frames (which I did on another box, not this > > one). It may not be quite as bad, but I think the increase in free > > memory is just based on fragmentation that builds up over time. > > Before you said SLUB was using only order-0 and order-1, I would have > suspected lumpy reclaim. Without high-order allocations, fragmentation > is not a problem and shouldn't be triggering a mass freeing of memory. > can you confirm with perf that there is no other constant source of > high-order allocations? Let me clarify: On _another_ box, with 2.6.36 but without your patches and without as much load or SSD devices, I forced slub to use order-0 except where order-1 was absolutely necessary (objects > 4096 bytes), just to see what impact this had on free memory. There was a change, but still lots of memory left free. I was trying to avoid confusion by posting graphs from different machines, but here is that one just as a reference: http://0x.ca/sim/ref/2.6.36/memory_stor25r_week.png (I made the slub order adjustment on Tuesday, November 30th.) The spikes are actually from mail nightly expunge/purge runs. It seems that minimizing the slub orders did remove the large free spike that was happening during mailbox compaction runs (nightly), and overall there was a bit more memory used on average, but it definitely didn't "fix" it. The original server I was posting graphs for has had no other vm tweaks, and so slub is still doing order-3 GFP_ATOMIC allocations from skb allocations. By the way, I noticed slub seems to choose different maximum orders based on the memory size. You may be able to get your test box to issue the same GFP_ATOMIC order-3 allocations from skb allocations by making your sysfs files match these values: [/sys/kernel/slab]# grep . kmalloc-??{,?,??}/order kmalloc-16/order:0 kmalloc-32/order:0 kmalloc-64/order:0 kmalloc-96/order:0 kmalloc-128/order:0 kmalloc-192/order:0 kmalloc-256/order:1 kmalloc-512/order:2 kmalloc-1024/order:3 kmalloc-2048/order:3 kmalloc-4096/order:3 kmalloc-8192/order:3 I suspect your kmalloc-1024 and kmalloc-2048 orders are less than 3 now? > > I don't > > have any long-running graphs of this yet, but I can see that pretty much > > all of the free memory always is order-0, and even a "while true; do > > sleep .01; done" is enough to make it throw out more order-0 while trying > > to make room for order-1 task_struct allocations. > > > > It would be semi-normal to throw out a few pages for order-1 task_struct > allocations. Is your server fork-heavy? I would have guessed "no" as you > are forcing a large number of forks with the while loop. No, the only things that cause forks on these servers usually are monitoring processes. According to munin, it averages under 3 forks per second. > > Maybe some pattern in the way that pages are reclaimed while they are > > being allocated is resulting in increasing fragmentation? All the boxes > > I see this on start out fine, but after a day or week they end up in swap > > and with lots of free memory. > > Is there something like a big weekly backup task running that would be > responsible for pushing a large amount of memory to swap that is never > faulted back in again because it's unused? There are definitely pages that are leaking from dovecot or similar which can be swapped out and not swapped in again (you can see "apps" growing), but there are no tasks I can think of that would ever cause the system to be starved. The calls to pageout() seem to happen if sc.may_writepage is set, which seems to happen when it thinks it has scanned enough without making enough progress. Could this happen just from too much fragmentation? The swapping seems to be at a slow but constant rate, so maybe it's happening just due to the way the types of allocations are biasing to Normal instead of DMA32, or vice-versa. Check out the latest memory graphs for the server running your original patch: http://0x.ca/sim/ref/2.6.36/memory_mel_patch_dec4.png http://0x.ca/sim/ref/2.6.36/zoneinfo_mel_patch_dec4 http://0x.ca/sim/ref/2.6.36/pagetypeinfo_mel_patch_dec4 Hmm, pagetypeinfo shows none or only a few of the pages in Normal are considered reclaimable... Simon- -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxxx For more info on Linux MM, see: http://www.linux-mm.org/ . Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/ Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}
{kind=link}
{kind=link}