On Fri, Jan 07, 2011 at 10:05:39AM -0800, Mark Moseley wrote:
> NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
> about in case there's something you'd like me to look at.
>
> Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
> bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
> first time doing bisect, so I'll preemptively apologize for doing
That's a merge commit, so that doesn't sound right (it doesn't contain
changes by itself). How were you running the bisect? Were you
definitely seeing a good case since v2.6.35? Could you post your
"git bisect log" so I can see if I can follow it?
> anything silly) both went berserk within 15 mins of each other, after
> an uptime of around 63 hours for 2.6.36.2 and 65 hours for the
> bisected box. The 2.6.36.2 one is still running with all the various
> flush-0:xx threads spinning wildly. The bisected box just keeled over
> and died, but is back up now. The only kernel messages logged are just
> of the "task kworker/4:1:359 blocked for more than 120 seconds"
> variety, all with _raw_spin_lock_irq at the top of the stack trace.
>
> Looking at slabinfo, specifically, this: stats=$(grep nfs_inode_cache
> /proc/slabinfo | awk '{ print $2, $3 }')
> the active_objs and num_objs both increase to over a million (these
> boxes are delivering mail to NFS-mounted mailboxes, so that's
> perfectly reasonable). On both boxes, looking at sar, things start to
> go awry around 10am today EST. At that time on the 2.6.36.2 box, the
> NFS numbers look like this:
>
> Fri Jan 7 09:58:00 2011: 1079433 1079650
> Fri Jan 7 09:59:00 2011: 1079632 1080300
> Fri Jan 7 10:00:00 2011: 1080196 1080300
> Fri Jan 7 10:01:01 2011: 1080599 1080716
> Fri Jan 7 10:02:01 2011: 1081074 1081288
>
> on the bisected, like this:
>
> Fri Jan 7 09:59:34 2011: 1162786 1165320
> Fri Jan 7 10:00:34 2011: 1163301 1165320
> Fri Jan 7 10:01:34 2011: 1164369 1165450
> Fri Jan 7 10:02:35 2011: 1164179 1165450
> Fri Jan 7 10:03:35 2011: 1165795 1166958
>
> When the bisected box finally died, the last numbers were:
>
> Fri Jan 7 10:40:33 2011: 1177156 1177202
> Fri Jan 7 10:42:21 2011: 1177157 1177306
> Fri Jan 7 10:44:55 2011: 1177201 1177324
> Fri Jan 7 10:45:55 2011: 1177746 1177826
Yeah, I was seeing load proportional to these, but I don't think their
growth is anything wrong. It just seems to be something that is taking
up CPU from flush proceses as they grow, and something which is causing a
thundering herd of reclaim with lots of spinlock contention.
Hmmm.. I tried to see if drop_caches would clear nfs_inode_cache and thus
the CPU usage. The top of slabtop before doing anything:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1256343 1221799 97% 0.95K 38071 33 1218272K nfs_inode_cache
# echo 2 > /proc/sys/vm/drop_caches
this took about 40 seconds to execute, and perf top showed this for
pretty much the whole time:
samples pcnt function DSO
_______ _____ ________________________ ___________
1188.00 45.1% _raw_spin_lock [kernel]
797.00 30.2% rpcauth_cache_shrinker [kernel]
132.00 5.0% shrink_slab [kernel]
60.00 2.3% queue_io [kernel]
59.00 2.2% _cond_resched [kernel]
44.00 1.7% nfs_writepages [kernel]
35.00 1.3% writeback_single_inode [kernel]
34.00 1.3% writeback_sb_inodes [kernel]
23.00 0.9% do_writepages [kernel]
20.00 0.8% bit_waitqueue [kernel]
15.00 0.6% redirty_tail [kernel]
11.00 0.4% __iget [kernel]
11.00 0.4% __GI_strstr libc-2.7.so
slabtop then showed:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1256211 531720 42% 0.95K 38067 33 1218144K nfs_inode_cache
and this doesn't change further with drop_caches=3 or 1. It's strange
that most of them were freed, but not all... We do actually have
RPC_CREDCACHE_DEFAULT_HASHBITS set to 10 at build time, which might
explain a bigger credcache and time to free that. Did you change your
auth_hashtable_size at all? Anyway, even with all of that, system CPU
doesn't change.
Ok, weird, Running "sync" actually caused "vmstat 1" to go from 25% CPU
spikes every 5 seconds with nfs_writepages in the "perf top" every 5
seconds to being idle! /proc/vmstat showed only nr_dirty 8 and
nr_writeback 0 before I ran "sync". Either that, or it was just good
timing.
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 6767892 9696 41088 0 0 5 180 15 70 62 7 29 1
0 0 0 6767892 9696 41088 0 0 0 0 1124 1978 0 0 100 0
0 0 0 6767892 9696 41088 0 0 0 0 1105 1967 0 0 100 0
0 0 0 6767892 9696 41088 0 0 0 0 1180 1984 0 2 98 0
2 0 0 6767892 9696 41088 0 0 0 0 2102 1968 0 22 78 0
0 0 0 6767768 9704 41084 0 0 0 52 1504 2022 0 8 91 1
0 0 0 6767768 9704 41084 0 0 0 0 1059 1965 0 0 100 0
0 0 0 6767768 9704 41088 0 0 0 0 1077 1982 0 0 100 0
0 0 0 6767768 9704 41088 0 0 0 0 1166 1972 1 2 97 0
0 0 0 6767768 9704 41088 0 0 0 0 1353 1990 0 6 94 0
0 0 0 6767644 9704 41100 0 0 0 0 2531 2050 0 27 72 0
0 0 0 6767644 9704 41100 0 0 0 0 1065 1974 0 0 100 0
1 0 0 6767644 9704 41100 0 0 0 0 1090 1967 0 0 100 0
0 0 0 6767644 9704 41100 0 0 0 0 1175 1971 0 2 98 0
0 0 0 6767644 9704 41100 0 0 0 0 1321 1967 0 6 94 0
1 0 0 6767644 9712 41100 0 0 0 52 1995 1995 0 18 81 1
0 0 0 6767644 9712 41100 0 0 0 0 1342 1964 0 6 94 0
0 0 0 6767644 9712 41100 0 0 0 0 1064 1974 0 0 100 0
0 0 0 6767644 9712 41100 0 0 0 0 1163 1968 0 2 98 0
0 0 0 6767644 9712 41100 0 0 0 0 1390 1976 1 6 94 0
0 0 0 6767768 9712 41112 0 0 0 0 1282 2018 0 1 99 0
0 0 0 6767768 9712 41112 0 0 0 0 2166 1972 0 24 76 0
0 0 0 6786260 9712 41112 0 0 0 0 1092 1989 0 0 100 0
0 0 0 6786260 9712 41112 0 0 0 0 1039 2003 0 2 98 0
0 0 0 6774588 9712 41112 0 0 0 0 1524 2015 3 9 89 0
0 1 0 6770124 9716 41112 0 0 0 48 1315 1990 3 0 87 11
1 0 0 6769628 9720 41112 0 0 0 4 2196 1966 0 20 79 0
0 0 0 6768364 9724 41108 0 0 36 0 1403 2031 1 5 94 1
0 0 0 6768388 9724 41144 0 0 0 0 1185 1969 0 2 98 0
0 0 0 6768388 9724 41144 0 0 0 0 1351 1975 0 6 94 0
0 0 0 6768140 9724 41156 0 0 0 0 1261 2020 0 1 99 0
0 0 0 6768140 9724 41156 0 0 0 0 1053 1973 0 0 100 0
1 0 0 6768140 9724 41156 0 0 0 0 2194 1971 1 26 73 0
0 0 0 6768140 9732 41148 0 0 0 52 1283 2088 0 4 96 0
2 0 0 6768140 9732 41156 0 0 0 0 1184 1965 0 2 98 0
0 0 0 6786368 9732 41156 0 0 0 0 1297 2000 0 4 97 0
0 0 0 6786384 9732 41156 0 0 0 0 998 1949 0 0 100 0
(stop vmstat 1, run sync, restart vmstat 1)
1 0 0 6765304 9868 41736 0 0 0 0 1239 1967 0 0 100 0
0 0 0 6765304 9868 41736 0 0 0 0 1174 2035 0 0 100 0
0 0 0 6765304 9868 41736 0 0 0 0 1084 1976 0 0 100 0
1 0 0 6765172 9868 41736 0 0 0 0 1100 1975 0 0 100 0
0 0 0 6765304 9868 41760 0 0 0 0 1501 1997 1 1 98 0
0 0 0 6765304 9868 41760 0 0 0 0 1092 1964 0 0 100 0
1 0 0 6765304 9868 41760 0 0 0 0 1096 1963 0 0 100 0
0 0 0 6765304 9868 41760 0 0 0 0 1083 1967 0 0 100 0
0 0 0 6765304 9876 41752 0 0 0 76 1101 1980 0 0 99 1
0 0 0 6765304 9876 41760 0 0 0 4 1199 2097 0 2 98 0
0 0 0 6765304 9876 41760 0 0 0 0 1055 1964 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1064 1977 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1073 1968 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1080 1976 0 0 100 0
0 0 0 6765156 9884 41772 0 0 0 20 1329 2034 1 1 98 1
0 0 0 6765180 9884 41780 0 0 0 0 1097 1971 0 1 99 0
0 0 0 6765180 9884 41780 0 0 0 0 1073 1960 0 0 100 0
0 0 0 6765180 9884 41780 0 0 0 0 1079 1976 0 0 100 0
0 0 0 6765172 9884 41780 0 0 0 0 1120 1980 0 0 100 0
0 0 0 6765180 9892 41772 0 0 0 60 1097 1982 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1067 1969 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1063 1973 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1064 1969 0 1 100 0
Hmmm. I'll watch it and see if it climbs back up again. That would mean
that for now, echo 2 > /proc/sys/vm/drop_caches ; sync is a workaround
for the problem we're seeing with system CPU slowly creeping up since
2.6.36. I have no idea if this affects the sudden flush process spinlock
contention and attempted writeback without much progress during normal
load, but it certainly changes things here.
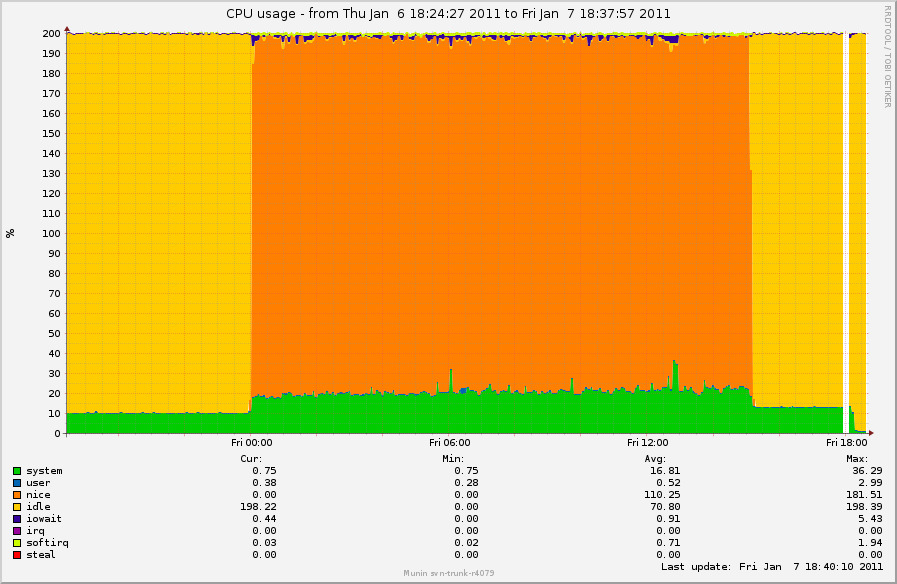
http://0x.ca/sim/ref/2.6.37/cpu_after_drop_caches_2_and_sync.png
Simon-
--
To unsubscribe from this list: send the line "unsubscribe linux-nfs" in
the body of a message to majordomo@xxxxxxxxxxxxxxx
More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
