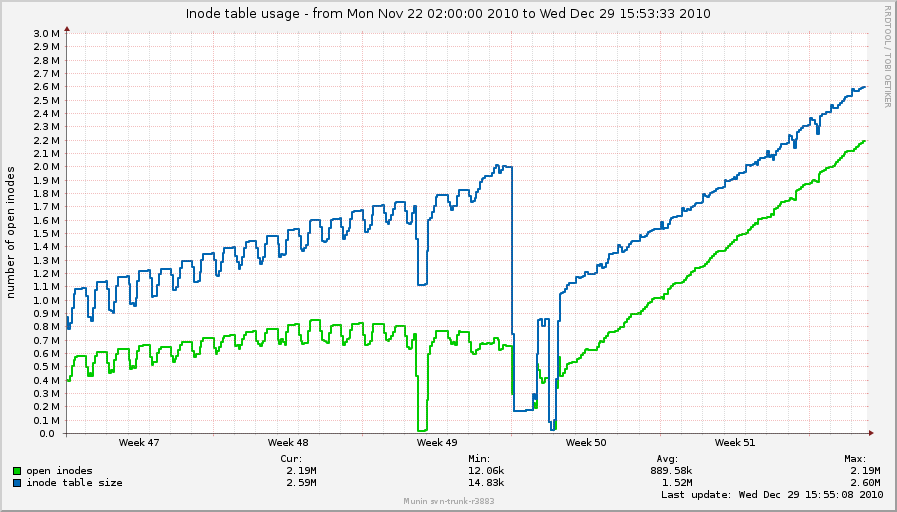
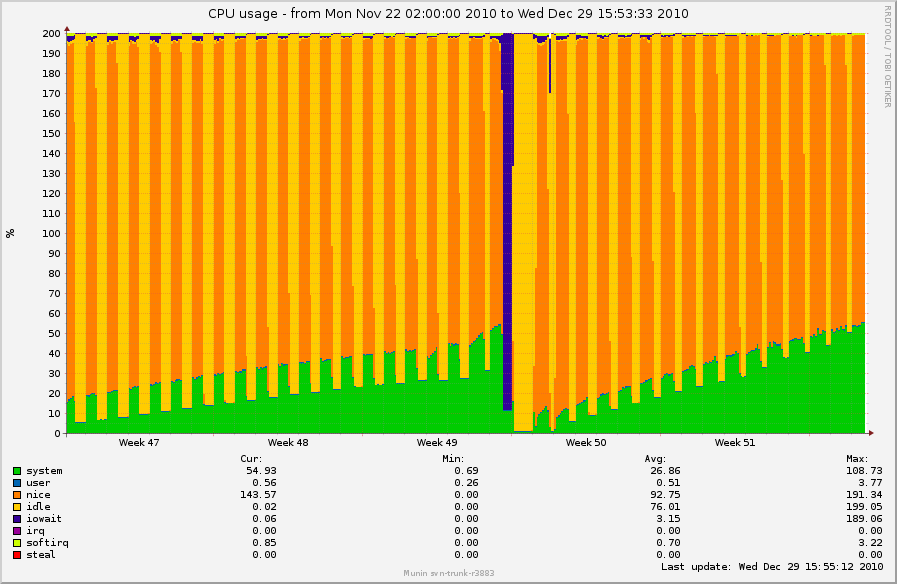
On Tue, Jan 4, 2011 at 1:40 PM, Simon Kirby <sim@xxxxxxxxxx> wrote: > On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote: > >> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <sim@xxxxxxxxxx> wrote: >> >> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37: >> > >> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME >> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache >> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16 >> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry >> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node >> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64 >> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head >> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32 >> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128 >> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8 >> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache >> > >> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png >> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png >> > >> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to >> > try to track this down without having to wait too long, unless somebody >> > can see what is happening here. >> >> I'll get started bisecting too, since this is something of a >> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time >> now have to be powercycled every couple of days (which is about how >> long it takes for this behavior to show up). This is across-the-board >> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2. >> >> Simon: It's probably irrelevant since these are kernel threads, but >> I'm curious what distro your boxes are running. Ours are Debian Lenny, >> i386, Dell Poweredge 850s. Just trying to figure out any >> commonalities. I'll get my boxes back on 2.6.36.2 and start watching >> nfs_inode_cache as well. > > Same distro, x86_64, similar servers. > > I'm not sure if the two cases I am seeing are exactly the same problem, > but on the log crunching boxes, system time seems proportional to > nfs_inode_cache and nfs_inode_cache just keeps growing forever; however, > if I stop the load and unmount the NFS mount points, all of the > nfs_inode_cache objects do actually go away (after umount finishes). > > It seems the shrinker callback might not be working as intended here. > > On the shared server case, the crazy spinlock contention from all of the > flusher processes happens suddenly and overloads the boxes for 10-15 > minutes, and then everything recovers. Over 21 of these boxes, they > each have about 500k-700k nfs_inode_cache objects. The log cruncher hit > 3.3 million nfs_inode_cache objects before I unmounted. > > Are your boxes repeating this behaviour at any predictable interval? Simon: My boxes definitely fall into the latter category, with spinlock regularly sitting at 60-80% CPU (according to 'perf top'). As far as predictability, not strictly, but it's typically after an uptime of 2-3 days. They take so long to get into this state that I've never seen the actual transition in person, just the after-effects of flush-0:xx gone crazy. These boxes have a number of other NFS mounts, but it's on the flush-0:xx's for the heavily written-to NFS mounts that are spinning wildly, which you'd expect to be the case. The infrequently written-to NFS servers' flush-0:xx isn't to be found in 'top' output. I'd booted into older kernels after my initial reply, so I'm 14 hrs into booting a box back into 2.6.36.2 and another box into a double-bisected 2.6.35-2.6.36 kernel (my first bisect hit compile errors). Both are running normally but that fits with the pattern so far. NFS Guys: Anything else we can be digging up to help debug this? This is a pretty ugly issue. -- To unsubscribe from this list: send the line "unsubscribe linux-nfs" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
{kind=link}
