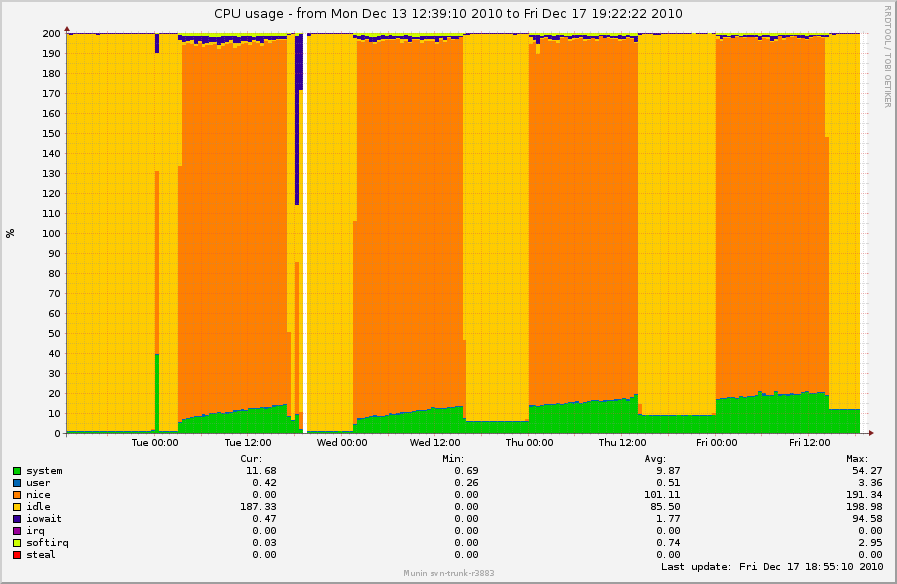
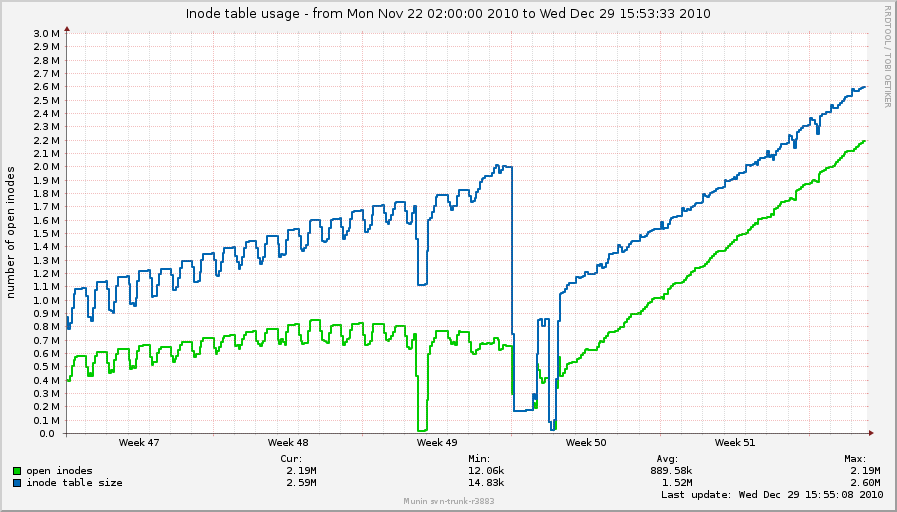
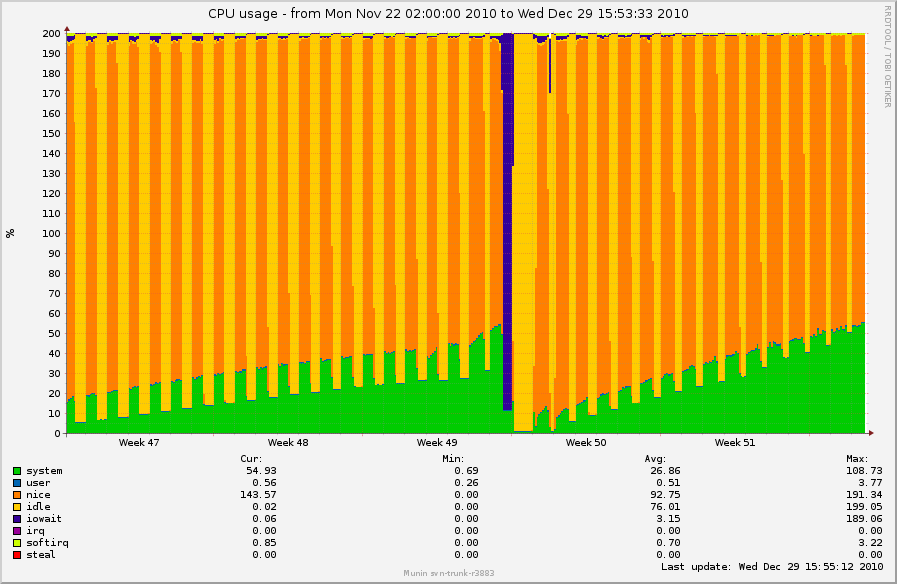
On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <sim@xxxxxxxxxx> wrote: > On Fri, Dec 17, 2010 at 05:08:01PM -0800, Simon Kirby wrote: > >> On Wed, Dec 08, 2010 at 01:25:05PM -0800, Simon Kirby wrote: >> >> > Possibly related to the flush-processes-taking-CPU issues I saw >> > previously, I thought this was interesting. I found a log-crunching box >> > that does all of its work via NFS and spends most of the day sleeping. >> > It has been using a linearly-increasing amount of system time during the >> > time where is sleeping. munin graph: >> > >> > http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png >> >... >> > Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the >> > munin graphs. I'll try 2.6.37-rc an see if it changes. >> >> So, back on this topic, >> >> It seems that system CPU from "flush" processes is still increasing >> during and after periods of NFS activity, even with 2.6.37-rc5-git4: >> >> http://0x.ca/sim/ref/2.6.37/cpu_nfs.png >> >> Something is definitely going on while NFS is active, and then keeps >> happening in the idle periods. top and perf top look the same as in >> 2.6.36. No userland activity at all, but the kernel keeps doing stuff. >> >> I could bisect this, but I have to wait a day for each build, unless I >> can come up with a way to reproduce it more quickly. The mount points >> for which the flush processes are active are the two mount points where >> the logs are read from, rotated, compressed, and unlinked, and where the >> reports are written, running in parallel under an xargs -P 15. >> >> I'm pretty sure the only syscalls that are reproducing this are read(), >> readdir(), lstat(), write(), rename(), unlink(), and close(). There's >> nothing special happening here... > > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37: > > OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME > 2562514 2541520 99% 0.95K 78739 33 2519648K nfs_inode_cache > 467200 285110 61% 0.02K 1825 256 7300K kmalloc-16 > 299397 242350 80% 0.19K 14257 21 57028K dentry > 217434 131978 60% 0.55K 7767 28 124272K radix_tree_node > 215232 81522 37% 0.06K 3363 64 13452K kmalloc-64 > 183027 136802 74% 0.10K 4693 39 18772K buffer_head > 101120 71184 70% 0.03K 790 128 3160K kmalloc-32 > 79616 59713 75% 0.12K 2488 32 9952K kmalloc-128 > 66560 41257 61% 0.01K 130 512 520K kmalloc-8 > 42126 26650 63% 0.75K 2006 21 32096K ext3_inode_cache > > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png > > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to > try to track this down without having to wait too long, unless somebody > can see what is happening here. I'll get started bisecting too, since this is something of a show-stopper. Boxes that pre-2.6.36 would stay up for months at a time now have to be powercycled every couple of days (which is about how long it takes for this behavior to show up). This is across-the-board for about 50 boxes, ranging from 2.6.36 to 2.6.36.2. Simon: It's probably irrelevant since these are kernel threads, but I'm curious what distro your boxes are running. Ours are Debian Lenny, i386, Dell Poweredge 850s. Just trying to figure out any commonalities. I'll get my boxes back on 2.6.36.2 and start watching nfs_inode_cache as well. -- To unsubscribe from this list: send the line "unsubscribe linux-nfs" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
