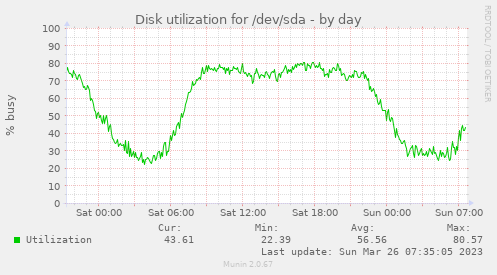
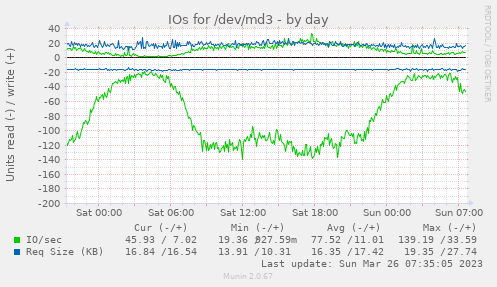
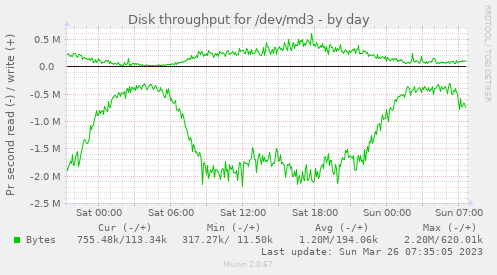
Hello there, as Strahil suggested a separate thread might be better. current state: - servers with 10TB hdds - 2 hdds build up a sw raid1 - each raid1 is a brick - so 5 bricks per server - Volume info (complete below): Volume Name: workdata Type: Distributed-Replicate Number of Bricks: 5 x 3 = 15 Bricks: Brick1: gls1:/gluster/md3/workdata Brick2: gls2:/gluster/md3/workdata Brick3: gls3:/gluster/md3/workdata Brick4: gls1:/gluster/md4/workdata Brick5: gls2:/gluster/md4/workdata Brick6: gls3:/gluster/md4/workdata etc. - workload: the (un)famous "lots of small files" setting - currently 70% of the of the volume is used: ~32TB - file size: few KB up to 1MB - so there are hundreds of millions of files (and millions of directories) - each image has an ID - under the base dir the IDs are split into 3 digits - dir structure: /basedir/(000-999)/(000-999)/ID/[lotsoffileshere] - example for ID 123456789: /basedir/123/456/123456789/default.jpg - maybe this structure isn't good and e.g. this would be better: /basedir/IDs/[here the files] - so millions of ID-dirs directly under /basedir/ - frequent access to the files by webservers (nginx, tomcat): lookup if file exists, read/write images etc. - Strahil mentioned: "Keep in mind that negative searches (searches of non-existing/deleted objects) has highest penalty." <--- that happens very often... - server load on high traffic days: > 100 (mostly iowait) - bad are server reboots (read filesystem info etc.) - really bad is a sw raid rebuild/resync Some images: https://abload.de/img/gls-diskutilfti5d.png https://abload.de/img/gls-io6cfgp.png https://abload.de/img/gls-throughput3oicf.png Our conclusion: the hardware is too slow, the disks are too big. For a future setup we need to improve the performance (or switch to a different solution). HW-Raid-controller might be an option, but SAS disks are not available. Options: - scale broader: more servers with smaller disks - faster disks: nvme Both are costly. Any suggestions, recommendations, ideas? Just an observation: is there a performance difference between a sw raid10 (10 disks -> one brick) or 5x raid1 (each raid1 a brick) with the same disks (10TB hdd)? The heal processes on the 5xraid1-scenario seems faster. Just out of curiosity... whoa, lofs of text - thx for reading if you reached ths point :-) Best regards Hubert Volume Name: workdata Type: Distributed-Replicate Volume ID: 7d1e23e5-0308-4443-a832-d36f85ff7959 Status: Started Snapshot Count: 0 Number of Bricks: 5 x 3 = 15 Transport-type: tcp Bricks: Brick1: glusterpub1:/gluster/md3/workdata Brick2: glusterpub2:/gluster/md3/workdata Brick3: glusterpub3:/gluster/md3/workdata Brick4: glusterpub1:/gluster/md4/workdata Brick5: glusterpub2:/gluster/md4/workdata Brick6: glusterpub3:/gluster/md4/workdata Brick7: glusterpub1:/gluster/md5/workdata Brick8: glusterpub2:/gluster/md5/workdata Brick9: glusterpub3:/gluster/md5/workdata Brick10: glusterpub1:/gluster/md6/workdata Brick11: glusterpub2:/gluster/md6/workdata Brick12: glusterpub3:/gluster/md6/workdata Brick13: glusterpub1:/gluster/md7/workdata Brick14: glusterpub2:/gluster/md7/workdata Brick15: glusterpub3:/gluster/md7/workdata Options Reconfigured: performance.client-io-threads: off nfs.disable: on transport.address-family: inet performance.cache-invalidation: on performance.stat-prefetch: on features.cache-invalidation-timeout: 600 features.cache-invalidation: on performance.read-ahead: off performance.io-cache: off performance.quick-read: on cluster.self-heal-window-size: 16 cluster.heal-wait-queue-length: 10000 cluster.data-self-heal-algorithm: full cluster.background-self-heal-count: 256 network.inode-lru-limit: 200000 cluster.shd-max-threads: 8 server.outstanding-rpc-limit: 128 transport.listen-backlog: 100 performance.least-prio-threads: 8 performance.cache-size: 6GB cluster.min-free-disk: 1% performance.io-thread-count: 32 performance.write-behind-window-size: 16MB performance.cache-max-file-size: 128MB client.event-threads: 8 server.event-threads: 8 performance.parallel-readdir: on performance.cache-refresh-timeout: 4 cluster.readdir-optimize: off performance.md-cache-timeout: 600 performance.nl-cache: off cluster.lookup-unhashed: on cluster.shd-wait-qlength: 10000 performance.readdir-ahead: on storage.build-pgfid: off ________ Community Meeting Calendar: Schedule - Every 2nd and 4th Tuesday at 14:30 IST / 09:00 UTC Bridge: https://meet.google.com/cpu-eiue-hvk Gluster-users mailing list Gluster-users@xxxxxxxxxxx https://lists.gluster.org/mailman/listinfo/gluster-users
{kind=link}
{kind=link}
{kind=link}
