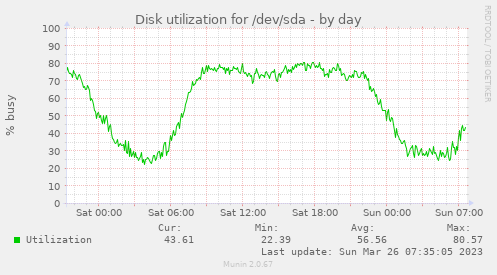
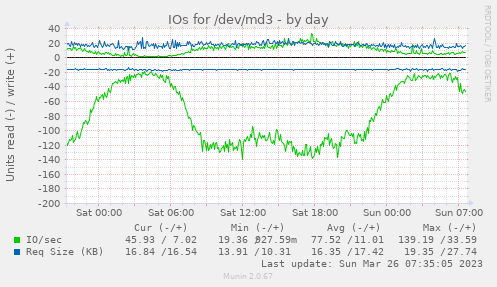
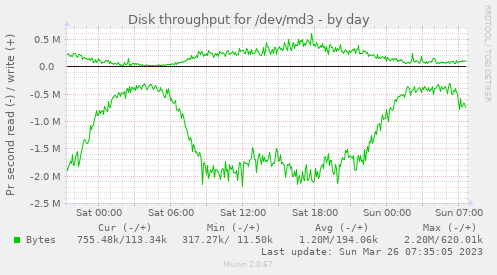
Hi, sry if i hijack this, but maybe it's helpful for other gluster users... > pure NVME-based volume will be waste of money. Gluster excells when you have more servers and clients to consume that data. > I would choose LVM cache (NVMEs) + HW RAID10 of SAS 15K disks to cope with the load. At least if you decide to go with more disks for the raids, use several (not the built-in ones) controllers. Well, we have to take what our provider (hetzner) offers - SATA hdds or sata|nvme ssds. Volume Name: workdata Type: Distributed-Replicate Number of Bricks: 5 x 3 = 15 Bricks: Brick1: gls1:/gluster/md3/workdata Brick2: gls2:/gluster/md3/workdata Brick3: gls3:/gluster/md3/workdata Brick4: gls1:/gluster/md4/workdata Brick5: gls2:/gluster/md4/workdata Brick6: gls3:/gluster/md4/workdata etc. Below are the volume settings. Each brick is a sw raid1 (made out of 10TB hdds). file access to the backends is pretty slow, even with low system load (which reaches >100 on the servers on high traffic days); even a simple 'ls' on a directory with ~1000 sub-directories will take a couple of seconds. Some images: https://abload.de/img/gls-diskutilfti5d.png https://abload.de/img/gls-io6cfgp.png https://abload.de/img/gls-throughput3oicf.png As you mentioned it: is a raid10 better than x*raid1? Anything misconfigured? Thx a lot & best regards, Hubert Options Reconfigured: performance.client-io-threads: off nfs.disable: on transport.address-family: inet performance.cache-invalidation: on performance.stat-prefetch: on features.cache-invalidation-timeout: 600 features.cache-invalidation: on performance.read-ahead: off performance.io-cache: off performance.quick-read: on cluster.self-heal-window-size: 16 cluster.heal-wait-queue-length: 10000 cluster.data-self-heal-algorithm: full cluster.background-self-heal-count: 256 network.inode-lru-limit: 200000 cluster.shd-max-threads: 8 server.outstanding-rpc-limit: 128 transport.listen-backlog: 100 performance.least-prio-threads: 8 performance.cache-size: 6GB cluster.min-free-disk: 1% performance.io-thread-count: 32 performance.write-behind-window-size: 16MB performance.cache-max-file-size: 128MB client.event-threads: 8 server.event-threads: 8 performance.parallel-readdir: on performance.cache-refresh-timeout: 4 cluster.readdir-optimize: off performance.md-cache-timeout: 600 performance.nl-cache: off cluster.lookup-unhashed: on cluster.shd-wait-qlength: 10000 performance.readdir-ahead: on storage.build-pgfid: off ________ Community Meeting Calendar: Schedule - Every 2nd and 4th Tuesday at 14:30 IST / 09:00 UTC Bridge: https://meet.google.com/cpu-eiue-hvk Gluster-users mailing list Gluster-users@xxxxxxxxxxx https://lists.gluster.org/mailman/listinfo/gluster-users
{kind=link}
{kind=link}
{kind=link}
