Lo! As mentioned a few times recently I'm staring to build a bot for
semi-automatic Linux kernel regressions tracking. Find below a rough
description of how I imagine it's going to work. That way I want to give
everyone a chance to influence things before I'm starting to code for
real. Early feedback will help to build something that's acceptable for
the Linux kernel developer community and used in practice in the long
run, and that's what I aim for.
I know, I know, "Talk is cheap. Show me the code.". But I had to think
things through and write some of it down anyway, so no harm done in
posting it as RFC. I CCed ksummit, as many maintainers hang out there
and because this is a follow up to my former regression tracking work we
discussed on both kernel and maintainers summit 2017; it fact it
hopefully might be something for this year as well, we'll see, too early
to tell.
So how will the "regzbot" work? The ideal case is simple:
Someone reports a regression to the recently created regressions mailing
list(regressions@xxxxxxxxxxxxxxx). There the user includes a tag like this:
> #regzb introduced: 94a632d91ad1 ("usc: xhbi-foo: check bar_params earlier")
That will make regzbot add the report to its list of regressions it
tracks, which among other will make it store the mail's message-id
(let's assume it's `xt6uzpqtaqru6pmh@earth.solsystem`). Ideally some
developer within a few days will fix the regression with a patch. When
doing so, they already often include a tag linking to the report:
> Link: https://lore.kernel.org/r/xt6uzpqtaqru6pmh@earth.solsystem
Regzbot will notice this tag refers to the regression it tracks and
automatically close the entry for it.
That's it already. The regression was tracked with:
* minimal overhead for the reporter
* no additional overhead for the developers – only something they ought
to do already became more important
Invisible ideally
-----------------
In the ideal case regzbot thus seems to be of no use. But obviously
things will be anything else than ideal quite often – for example when
nobody fixes the reported regression.
The webpages that Regzbot will generate (see below) will show this. They
among others are meant for Linus or Greg to check how things stand, so
they can simply fix a regression by reverting the causing commit if they
want to; in other situations they might decide to delay a release to get
crucial regressions solved.
And that's what regression tracking is about: providing a view into the
state of things with regards to regressions, as that's the important
thing missing in Linux kernel development right now.
That can't be all
-----------------
Of course the world is more complicated than the simple example scenario
above, as the devil is always in the details. The three most obvious
problems the initial ideal scenario left aside:
* The reporter doesn't specify the #regzb tag at all. Regzbot can't do
anything about it, it sadly won't have visionary power and a AI engine
any time soon. Some human (for a while that often will be me) thus needs
to reply with the tag with a proper reply-to to the report to make
regboz track it.
* The commit causing the regression is unknown to the reporter. In that
case the tag should mention the span when the regression was introduced:
> #regzb introduced: v5.7..v5.8-rc1
* The developer who fixes the issue forgets to place the "Link:" tag,
which can't be added once committed. In that case some human needs to
reply to the thread with the initial report with a tag like this:
> #regzb Fixed-by: c39667ddcfd5
How will it look
----------------
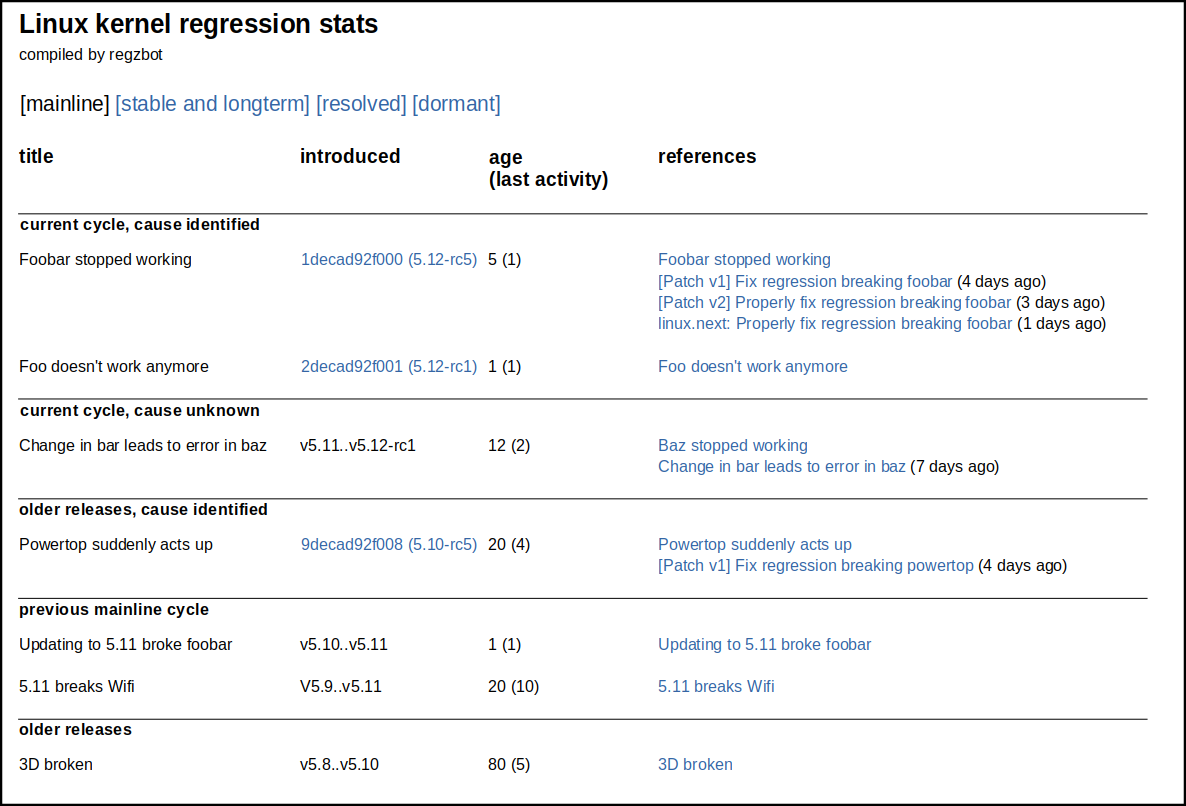
Here is a mockup on the website for the regzbotproject:
https://linux-regtracking.leemhuis.info/images/regzbot-mockup.png
You'll notice a few things:
* regressions for mainline kernel will be shown on a different page
than those in stable and longterm kernels, as they are handled by
different people.
* regressions where the culprit is known get the top spot, as the
change causing them can sometimes simply be reverted to fix the regression.
* the second spot is for regressions in the current cycle, as contrary
to those in previous release there is still time to fix those before the
next release.
* Regzbot will try to monitor the process between reporting and fixing
and provide links to lookup details. Regzbot will thus watch the thread
where the regression was reported and show when it noticed the last
activity; it will also look out for `#regszb Link:` and `Link:` tags in
patch submissions and linux-next. That way release managers can
immediately see if things stalled after the regression was reported; it
also allows them to see if developers are working on a fix and how far
it got in the machinery. If the causing commit is known, the webview
obviously will link to it as well.
* regressions where nothing happened for a while will be moved to the
"dormant" page, to prevent the status page from getting filled by
reports that obviously nobody cares about anymore. Reporters will be
told about this by mail to give them a chance to provide a fresh status
update to get things rolling again.
Even more problems in the details
---------------------------------
Regzbot on purpose will lack many features found in traditional bug
trackers: it's meant to be a simple tool acting in the background
without much overhead, as it doesn't want to become yet another bug
tracker. Nevertheless, it will need a few features they typically offer.
Those will be usable via tags that need to be dropped into mails send in
direct or indirect reply to the mail with the report:
* Mark a report as a duplicate of another or revert such a marking:
> #regzb dup: https://lore.kernel.org/r/yt6uzpqtaqru6pmh@mars.solsystem
> #regzb undup
* Mark a report as invalid.
> #regzb invalid: Turned out it never worked
* generate a new title
> #regzb new-title: Insert better description of the regression
* the initially mentioned tag can be used in replies to the report to
specify the commit causing the regression:
> #regzb introduced: v5.7..v5.8-rc1
* Tell regzbot that a discussion is related to a tracked regression:
> #regszb Link: https://lore.kernel.org/r/yt6uzpqtaqru6pmh@mars.solsystem
In the long run this is supposed to work in both directions, so you
can use it in a thread started by a regression report to link to some
other discussion or vice versa.
Implications and hidden aspects
-------------------------------
There are a few things of note:
* The plan for now is to not have a tag like `#regzb unfix`: in case it
turns out a commit did not fix a regression it's likely better to start
with a fresh report anyway. That forces someone to explain the current
state of things including the history clearly and straight forward; that
makes things a lot easier to follow for others in these situations and
thus is a good thing.
* regzbot works without a public unique-id, as it uses the URL of the
report instead and keeps any eye on is using the mail's message-id (say
20210406135151.xt6uzpqtaqru6pmh@earth.solsystem).
* regzbot won't be able to handle regressions reported to a mailing
list thread that is already tracked by regzbot, as it will assume all
mails in a thread are related to the earlier report. In that case the
reporter must be asked to start a new mailing list thread for the second
regression. But that's quite normal, as a similar approach is needed
when somebody reports an issue deep in a bug tracker ticket that was
crated for a totally different issue.
* Initially it won't be possible to track reports that are filed in bug
trackers; but this use-case will be kept in mind during the design to
make sure such a functionality can be added later easily.
* developer when fixing a regression with a bisected "#regzb
introduced:" tag can simply do `s/#regzb introduced:/Fixes:/` to get a
tag they are supposed to add.
* regression in stable and longterm kernels sometimes affect multiple
versions, for example if a patch that works fine in mainline was
backported to the longterm kernel 5.10 and 5.4 – but causes problems in
both, as something required by the patch is missing in those lines. How
this will be solved exactly remains to be seen, maybe like this:
> #regzb Introduced: c39667ddcfd6 e39667ddcfd1 ("usc: xhbi-foo: check bar_params a little later again")
Then regzbot can look those commits up and from that determine the
affected versions. Obviously the reporter will likely not be aware of
it, hence it's likely that the stable maintainer or the developer need
to send a mail to make regzbot aware that this regression affects
multiple versions.
* Regzbot will need to be able to work with mails where mailers placed
a linebreak into the text that follows the #regzb tag. This will be
tricky, but is doable.
* to keep things simple there are neither authentication nor
restrictions for now, so anyone could mess things up by sending mails to
an open list and using those tags. If that against expectations turns
out to become a problem some restrictions will need to be put in place,
for example to allow changes only from email addresses that (1) are on
an allow list, (2) participated in the discussion or (3) have commits in
the kernel. People could still forge complete mails including "From",
but that's quite some work for not much to gain (except for messing
regression tracking up).
Implementation
--------------
The rough initial idea had been to reuse parts of the syzbot golang
source code, which already has an email interface similar to the one
regzbot needs. But the closer I looked, the more I came to the
conclusion that writing something in python is easier and better (even
if that means I need to bring my really rusty python skills up to
speed). That also has the benefit that python afaics is preferred by the
kernel.org admins, which would make it more attractive for them to host
the bot later.
The focus will be to properly establishing regression tracking with
regszbot first. All features not strictly needed will thus be left out
first to focus on what's most important. I'll also provide documentation
and will use the bot myself to track regressions as I did a few years
ago. Just like any other tracking solution it will always need some
hand-holding...
= EOF =
That's it. FWIW, this mail is slightly modified version of a text I
posted on the website for the regzbot project:
https://linux-regtracking.leemhuis.info/post/regzbot-approach/
Side note: that project and my work is funded by NGI pointer for one
year (see the website's about page for details). Follow-up funding won't
be possible from there, but hopefully by then I can find some other way
to keep things running and me in a position to look after regression
tracking.
Ciao, Thorsten
{kind=link}
