|
>Mark, to illustrate:
>create table node (node_id integer primary key, fld1 varchar); >create table node_1 (node_id integer primary key, node_1_fld boolean) >inherits ( node); >NOTICE: merging column "node_id" with inherited definition >insert into node values (1, 'dog'); >insert into node_1 values (1, 'cat', 'f'); >select * from node; > node_id | fld1 >---------+------ > 1 | dog > 1 | cat
That would make sense except that I never explicitly use the inherits option in the
node_1 (my dataset) table. Postgres seems to be assuming that.
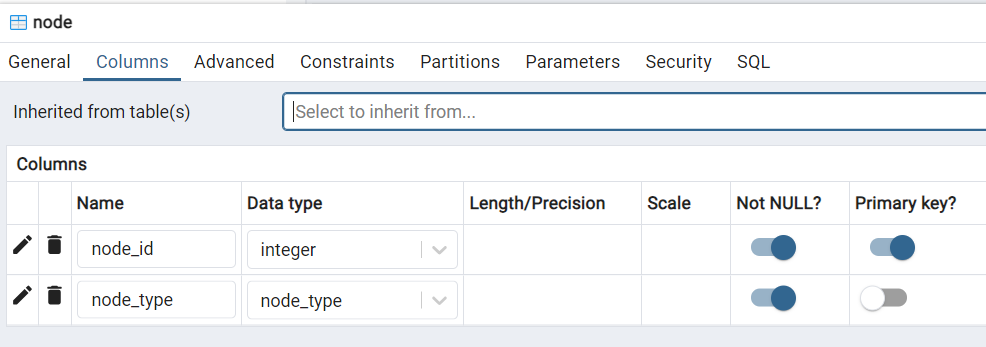
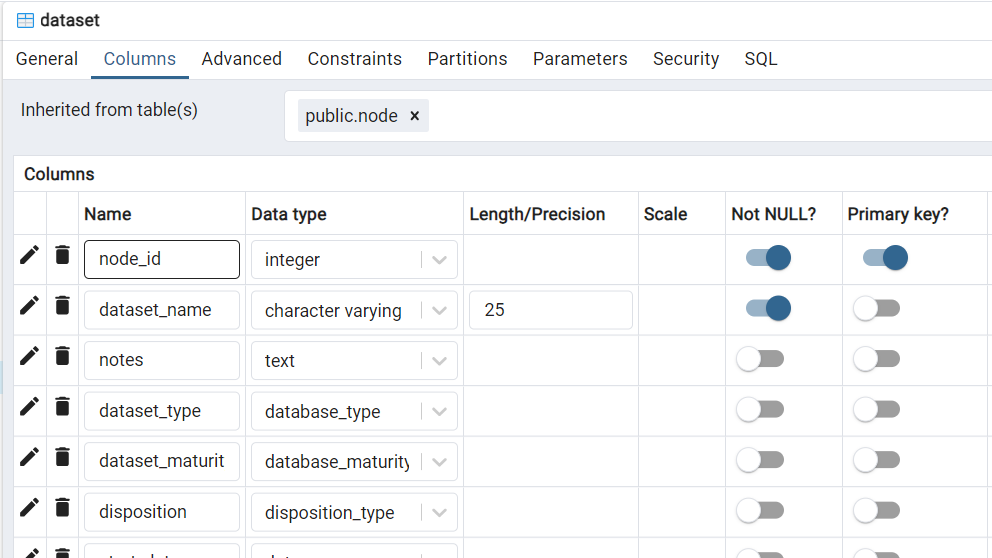
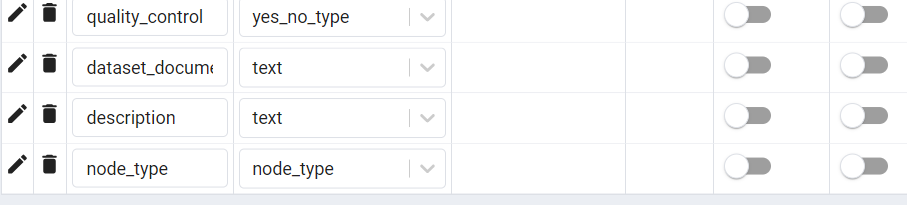
Also, the second column in node and in dataset are two different columns. However, Postgres insists on the
node_type attribute being included (last column) in table dataset and won't let me delete it. This is redundant because every dataset is a dataset type of node.
...
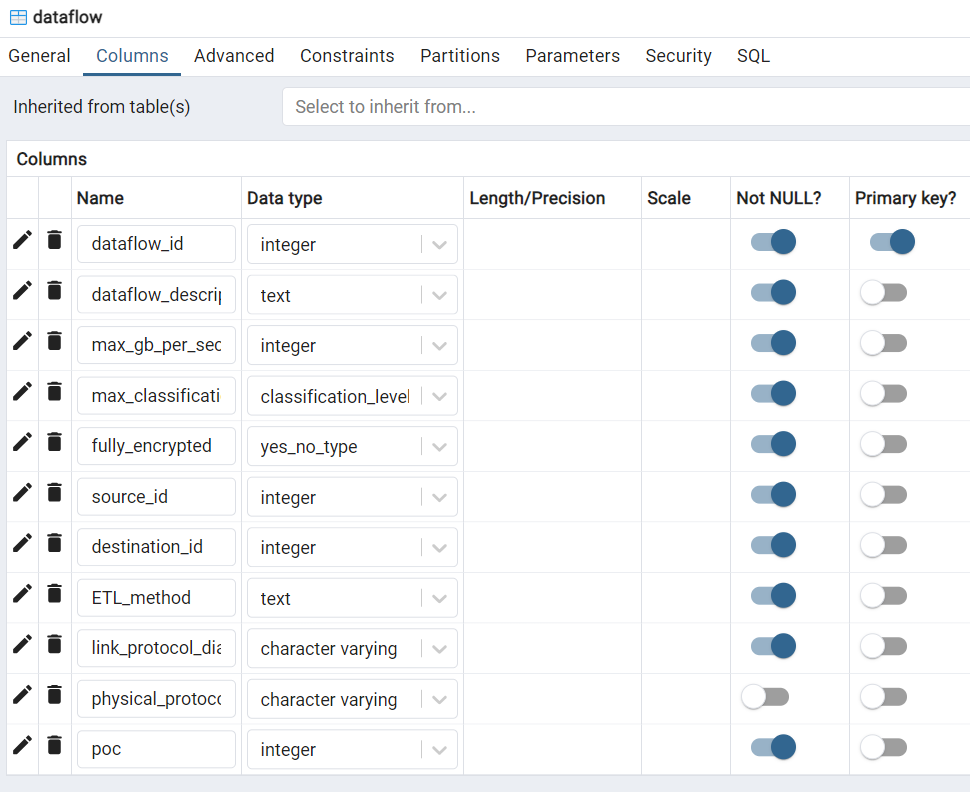
The reason for the current design is that I also have a dataflow table as shown below.
A dataflow record describes the flow of data between two nodes. Now, if there are 3 types of node: dataset, processing, and user, then there are 9 types of dataflow. Hence, 9 tables are needed to represent the dataflows instead of 1. In the below,
source_id and destination_id are both node_ids. If I want to know if a node is a dataset, processing node, or a user, I just look that up in the nodes table.
So, I think the crux of the problem is that Postgres assumes that inheritance is declared when it is not.
More answers to your questions coming.
From: Adrian Klaver <adrian.klaver@xxxxxxxxxxx>
Sent: Wednesday, March 12, 2025 12:01 PM To: mark bradley <markbradyju@xxxxxxxxxxx> Cc: pgsql-general <pgsql-general@xxxxxxxxxxxxxx> Subject: Re: Duplicate Key Values On 3/12/25 08:46, Adrian Klaver wrote:
> On 3/11/25 13:24, Adrian Klaver wrote: >> On 3/11/25 12:55, mark bradley wrote: >>> It happened again. Now there are no sequences (although there once >>> was). >> >> Read my previous post and provide the information requested. >> > > Mark sent me the below, which answers some of the questions, namely > there is inheritance going on: Mark, to illustrate: create table node (node_id integer primary key, fld1 varchar); create table node_1 (node_id integer primary key, node_1_fld boolean) inherits ( node); NOTICE: merging column "node_id" with inherited definition insert into node values (1, 'dog'); insert into node_1 values (1, 'cat', 'f'); select * from node; node_id | fld1 ---------+------ 1 | dog 1 | cat This is explained here: https://www.postgresql.org/docs/current/sql-createtable.html INHERITS ( parent_table [, ... ] ) "... , and by default the data of the child table is included in scans of the parent(s)." This explains why you see duplicates of node_id. Though if you try to enter a duplicate value in to a particular table you get: insert into node_1 values (1, 'test', 't'); ERROR: duplicate key value violates unique constraint "node_1_pkey" DETAIL: Key (node_id)=(1) already exists. This still does not explain why REINDEX TABLE node; caused data to disappear? > > Did you ever run VALIDATE CONSTRAINT against them? > Here is the run As error notes VALIDATE CONSTRAINT only works on FK and check constraints. You would need to run against the FK constraints that where marked NOT VALID e.g "dataset" on the dataset table. Honestly, I think you need rework your data model. Not sure what the inheritance is getting you. Seems simpler to just have the node table not be inherited and just use FK relationships back to it. > > Universal Metadata Schema=# ALTER TABLE node VALID > ATE CONSTRAINT node_id; > ERROR: constraint "node_id" of relation "node" is > not a foreign key or check constraint > Universal Metadata Schema=# > > Universal Metadata Schema=# ALTER TABLE dataset VA > LIDATE CONSTRAINT node_id; > ALTER TABLE > Universal Metadata Schema=# > > > > > -- Adrian Klaver adrian.klaver@xxxxxxxxxxx |
