(Adding linux-raid - I hope that's OK Keld?)
On Wednesday July 2, keld@xxxxxxxx wrote:
>
> When 'offset' replicas are chosen, the multiple copies of a given chunk
> are laid out on consecutive drives and at consecutive offsets. Effec-
> tively each stripe is duplicated and the copies are offset by one
> device. This should give similar read characteristics to 'far' if a
> suitably large chunk size is used, but without as much seeking for
> writes.
>
> A number of benchmarks have shown that 'offset' layout does not have
> similar read characteristics as the 'far' layout. Also a number of benchmarks have
> shown that seeking is similar in 'far' and 'offset' layouts. So I suggest to
> remove the last sentence.
If I have done any such benchmarks, it was too long ago to remember,
so I decided to do some simple tests and graph them. I like graphs
and I like this one so I've decided to share it.
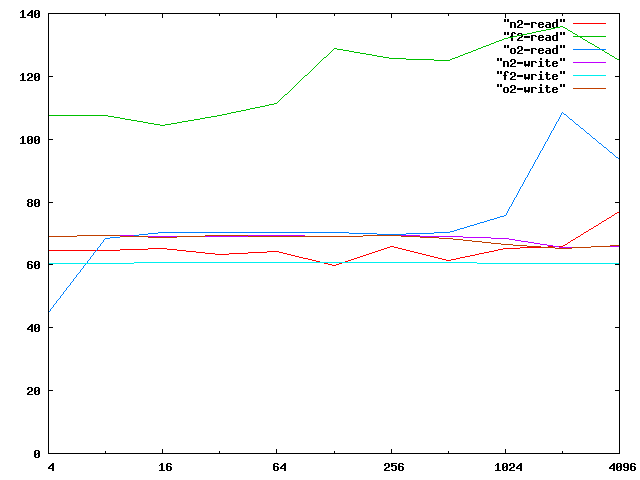
The X axis is chunk size, ranging from 4k to 4096k - it is
logarithmic.
The Y axis is throughput in MB/s measured by 'dd' to the raw device -
average of 5 runs.
This was with a 2-drive raid with each of the possible layout: n2, f2,
o2.
f2-read is strikingly faster than anything else. It is clearly
reading from both drives as once, as you would expect it to.
f2-write is slower then anything else (except at 4K chunk size, which is
an extreme case).
o2-read is fairly steady for most of the chunk sizes, but peaks up at
2M and only drops a little at 4M. This seems to suggest that it is
around 2M that the time to seek over a chunk drops well below the time
to read one chunk. Possibly at smaller chunk sizes, it just reads to
skip N sectors. Maybe the cylinder size is about 2Meg - there no real
gain from the offset layout until you can seek over whole cylinders.
So the sentence:
This should give similar read characteristics to 'far' if a
suitably large chunk size is used
seems somewhat justified if the chunksize used is 2M.
It might be interesting to implement non-power-of-2 chunksizes and try
a range of sizes between 1M and 4M to see what the graph looks like...
maybe we could find the actual cylinder size.
o2-write is very close to n2-write and is measurably (8%-14%) higher
than f2-write. This seems to support the sentence
but without as much seeking for writes.
It is not that there are fewer seeks, but that the seeks are shorter.
So while I don't want to just remove that last sentence, I agree that
it could be improved, possibly by giving a ball-park figure for what a
"suitably large chunk size" is. Also the second half could be
"but without the long seeks being required for sequential writes".
It would probably be good to do some measurements with random IO as
well to see how they compare.
Anyone else have some measurements they would like to share?
Thanks for your suggestions.
NeilBrown