Peter J. Holzer <hjp-pgsql@xxxxxx> (2023. nov. 26., V, 12:30):
> nov 24 10:20:19 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:19.691 CET [35] > LOG: checkpoints are occurring too frequently (23 seconds apart)
> nov 24 10:20:42 docker02 33d8b96b9062[1200]: 2023-11-24 10:20:42.938 CET [35] > LOG: checkpoints are occurring too frequently (23 seconds apart)
Interesting. If the database writes 1.5 GB/s of WALs and max_wal_size is
the default of 1GB, shouldn't there be a checkpoint about every 0.7
seconds instead of just every 22 seconds?
That log is from the beginning of the problem, 10:20. It started slowly, then ramped up.
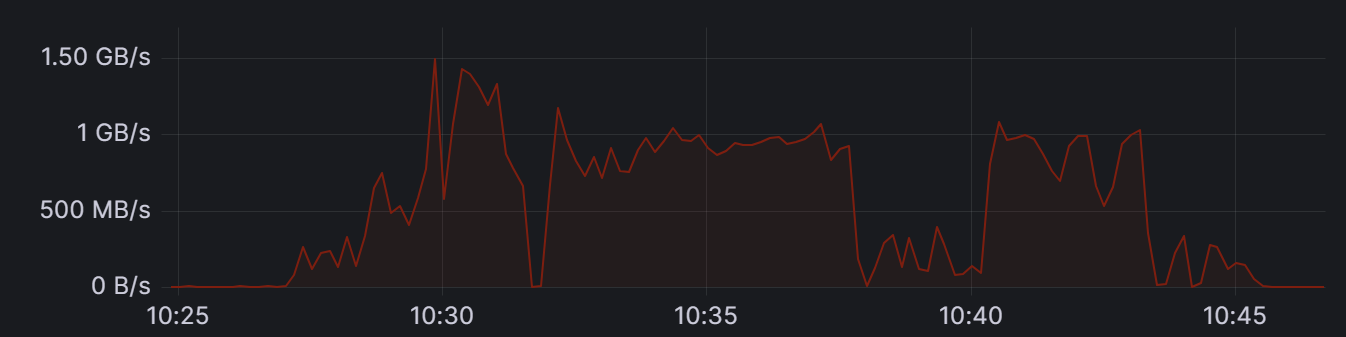
I'm not sure what happened at 10:32. At 10:38 there was the first server restart + shut down all clients. After recovery at 10:40, writing again. At 10:44 we dropped the slot and it went down to 5MB/sec within one minute.
On the second occasion it was writing at 3GB/sec for some time, but then we acted very quickly:
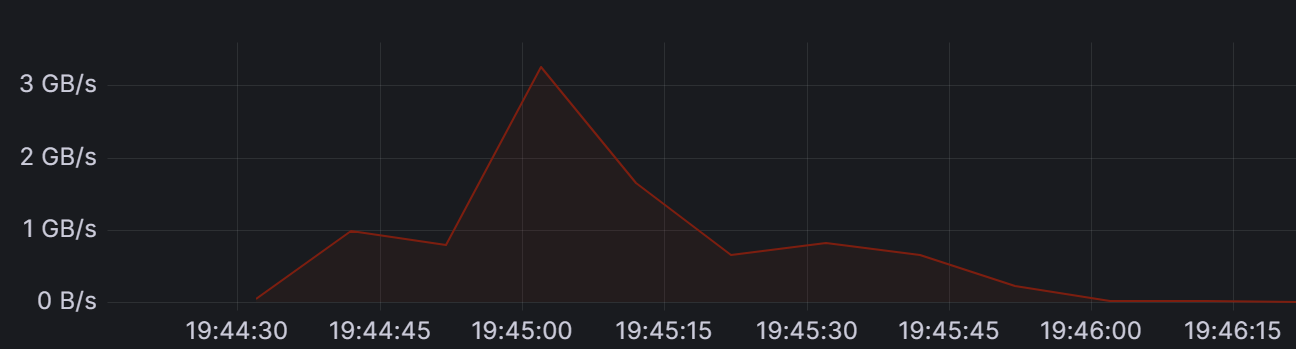
Network I/O was always about half of the disk I/O, very consistently (One half of the data was going to one standby, the other half could not be sent because of the slow network).
After dropping the slot, writing always went down within about one minute. It was also very consistent, stopped exactly after dropping the slot.
After separating DEV and PROD networks completely, yesterday we have created a new standby again (third try). No problems so far. I hope it will remain that way. Still investigating the applications (pg clients), looking for bugs.
Thank you for your help!
Laszlo
