Hi Karl,
Thanks for the quick reply! Answers inline.
My starting point, having executed exactly the preparation query in my email, was that the sample EXPLAIN (ANALYZE, BUFFERS) SELECT query ran in 15.3 seconds (best of 5), and did two nested loops.
On 24 June 2017 at 03:01, Karl Czajkowski <karlcz@xxxxxxx> wrote:
Also, did you include an ANALYZE step between your table creation
statements and your query benchmarks? Since you are dropping and
recreating test data, you have no stats on anything.
I tried this suggestion first, as it's the hardest to undo, and could also be done automatically by a background ANALYZE while I wasn't looking. It did result in a switch to using hash joins (instead of nested loops), and to starting with the metric_value table (the fact table), which are both changes that I thought would help, and the EXPLAIN ... SELECT speeded up to 13.2 seconds (2 seconds faster; best of 5 again).
Did you only omit a CREATE INDEX statement on asset_pos (id, pos) from
your problem statement or also from your actual tests? Without any
index, you are forcing the query planner to do that join the hard way.
I omitted it from my previous tests and the preparation script because I didn't expect it to make much difference. There was already a primary key on ID, so this would only enable an index scan to be changed into an index-only scan, but the query plan wasn't doing an index scan.
It didn't appear to change the query plan or performance.
Have you tried adding a foreign key constraint on the id_asset and
id_metric columns? I wonder if you'd get a better query plan if the
DB knew that the inner join would not change the number of result
rows. I think it's doing the join inside the filter step because
it assumes that the inner join may drop rows.
This didn't appear to change the query plan or performance either.
> This is an example of the kind of query we would like to speed up:
>
>
> SELECT metric_pos.pos AS pos_metric, asset_pos.pos AS pos_asset,
> date, value
> FROM metric_value
> INNER JOIN asset_pos ON asset_pos.id = metric_value.id_asset
> INNER JOIN metric_pos ON metric_pos.id = metric_value.id_metric
> WHERE
> date >= '2016-01-01' and date < '2016-06-01'
> AND timerange_transaction @> current_timestamp
> ORDER BY metric_value.id_metric, metric_value.id_asset, date
>
How sparse is the typical result set selected by these date and
timerange predicates? If it is sparse, I'd think you want your
compound index to start with those two columns.
I'm not sure what "sparse" means? The date is a significant fraction (25%) of the total table contents in this test example, although we're flexible about date ranges (if it improves performance per day) since we'll end up processing a big chunk of the entire table anyway, batched by date. Almost no rows will be removed by the timerange_transaction filter (none in our test example). We expect to have rows in this table for most metric and asset combinations (in the test example we populate metric_value using the cartesian product of these tables to simulate this).
I created the index starting with date and it did make a big difference: down to 10.3 seconds using a bitmap index scan and bitmap heap scan (and then two hash joins as before).
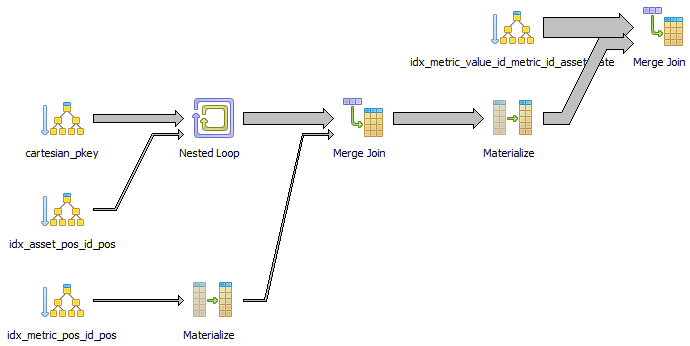
I was also able to shave another 1.1 seconds off (down to 9.2 seconds) by materialising the cartesian product of id_asset and id_metric, and joining to metric_value, but I don't really understand why this helps. It's unfortunate that this requires materialisation (using a subquery isn't enough) and takes more time than it saves from the query (6 seconds) although it might be partially reusable in our case.
CREATE TABLE cartesian ASSELECT DISTINCT id_metric, id_asset FROM metric_value;SELECT metric_pos.pos AS pos_metric, asset_pos.pos AS pos_asset, date, valueFROM cartesianINNER JOIN metric_value ON metric_value.id_metric = cartesian.id_metric AND metric_value.id_asset = cartesian.id_assetINNER JOIN asset_pos ON asset_pos.id = metric_value.id_assetINNER JOIN metric_pos ON metric_pos.id = metric_value.id_metricWHEREdate >= '2016-01-01' and date < '2016-06-01'AND timerange_transaction @> current_timestampORDER BY metric_value.id_metric, metric_value.id_asset, date;
And I was able to shave another 3.7 seconds off (down to 5.6 seconds) by making the only two columns of the cartesian table into its primary key, although again I don't understand why:
alter table cartesian add primary key (id_metric, id_asset);
This uses merge joins instead, which supports the hypothesis that merge joins could be faster than hash joins if only we can persuade Postgres to use them. It also contains two materialize steps that I don't understand.
Finally, your subject line said you were joining hundreds of rows to
millions. In queries where we used a similarly small dimension table
in the WHERE clause, we saw massive speedup by pre-evaluating that
dimension query to produce an array of keys, the in-lining the actual
key constants in the where clause of a main fact table query that
no longer had the join in it.
In your case, the equivalent hack would be to compile the small
dimension tables into big CASE statements I suppose...
Nice idea! I tried this but unfortunately it made the query 16 seconds slower (up to 22 seconds) instead of faster. I'm not sure why, perhaps the CASE _expression_ is just very slow to evaluate?
SELECTcase metric_value.id_metric when 1 then 565 when 2 then 422 when 3 then 798 when 4 then 161 when 5 then 853 when 6 then 994 when 7 then 869 when 8 then 909 when 9 then 226 when 10 then 32 when 11then 592 when 12 then 247 when 13 then 350 when 14 then 964 when 15 then 692 when 16 then 759 when 17 then 744 when 18 then 192 when 19 then 390 when 20 then 804 when 21 then 892 when 22 then 219 when 23 then 48 when 24 then 272 when 25 then 256 when 26 then 955 when 27 then 258 when 28 then 858 when 29 then 298 when 30 then 200 when 31 then 681 when 32 then 862when 33 then 621 when 34 then 478 when 35 then 23 when 36 then 474 when 37 then 472 when 38 then 892 when 39 then 383 when 40 then 699 when 41 then 924 when 42 then 976 when 43 then946 when 44 then 275 when 45 then 940 when 46 then 637 when 47 then 34 when 48 then 684 when 49 then 829 when 50 then 423 when 51 then 487 when 52 then 721 when 53 then 642 when 54then 535 when 55 then 992 when 56 then 898 when 57 then 490 when 58 then 251 when 59 then 756 when 60 then 788 when 61 then 451 when 62 then 437 when 63 then 650 when 64 then 72 when65 then 915 when 66 then 673 when 67 then 546 when 68 then 387 when 69 then 565 when 70 then 929 when 71 then 86 when 72 then 490 when 73 then 905 when 74 then 32 when 75 then 764 when 76 then 845 when 77 then 669 when 78 then 798 when 79 then 529 when 80 then 498 when 81 then 221 when 82 then 16 when 83 then 219 when 84 then 864 when 85 then 551 when 86 then 211 when 87 then 762 when 88 then 42 when 89 then 462 when 90 then 518 when 91 then 830 when 92 then 912 when 93 then 954 when 94 then 480 when 95 then 984 when 96 then 869 when 97 then 153 when 98 then 530 when 99 then 257 when 100 then 718 end AS pos_metric,case metric_value.id_asset when 1 then 460 when 2 then 342 when 3 then 208 when 4 then 365 when 5 then 374 when 6 then 972 when 7 then 210 when 8 then 43 when 9 then 770 when 10 then 738 when 11then 540 when 12 then 991 when 13 then 754 when 14 then 759 when 15 then 855 when 16 then 305 when 17 then 970 when 18 then 617 when 19 then 347 when 20 then 431 when 21 then 134 when 22 then 176 when 23 then 343 when 24 then 88 when 25 then 656 when 26 then 328 when 27 then 958 when 28 then 809 when 29 then 858 when 30 then 214 when 31 then 527 when 32 then 318when 33 then 557 when 34 then 735 when 35 then 683 when 36 then 930 when 37 then 707 when 38 then 892 when 39 then 973 when 40 then 477 when 41 then 631 when 42 then 513 when 43 then469 when 44 then 385 when 45 then 272 when 46 then 324 when 47 then 690 when 48 then 242 when 49 then 940 when 50 then 36 when 51 then 674 when 52 then 74 when 53 then 212 when 54 then 17 when 55 then 163 when 56 then 868 when 57 then 345 when 58 then 120 when 59 then 677 when 60 then 202 when 61 then 335 when 62 then 204 when 63 then 520 when 64 then 891 when65 then 938 when 66 then 203 when 67 then 822 when 68 then 645 when 69 then 95 when 70 then 795 when 71 then 123 when 72 then 726 when 73 then 308 when 74 then 591 when 75 then 110 when 76 then 581 when 77 then 915 when 78 then 800 when 79 then 823 when 80 then 855 when 81 then 836 when 82 then 496 when 83 then 929 when 84 then 48 when 85 then 513 when 86 then 92when 87 then 916 when 88 then 858 when 89 then 213 when 90 then 593 when 91 then 60 when 92 then 547 when 93 then 796 when 94 then 581 when 95 then 438 when 96 then 735 when 97 then783 when 98 then 260 when 99 then 380 when 100 then 878 end AS pos_asset,date, valueFROM metric_valueWHEREdate >= '2016-01-01' and date < '2016-06-01'AND timerange_transaction @> current_timestampORDER BY metric_value.id_metric, metric_value.id_asset, date;
Thanks again for the suggestions :) I'm still very happy for any ideas on how to get back the 2 seconds longer than it takes without any joins to the dimension tables (3.7 seconds), or explain why the cartesian join helps and/or how we can get the same speedup without materialising it.
SELECT id_metric, id_asset, date, valueFROM metric_valueWHEREdate >= '2016-01-01' and date < '2016-06-01'AND timerange_transaction @> current_timestampORDER BY date, metric_value.id_metric;
Cheers, Chris.
