On 9/30/21 7:41 PM, Peter Rajnoha wrote:
On 9/30/21 10:07, heming.zhao@xxxxxxxx wrote:
On 9/30/21 3:51 PM, Martin Wilck wrote:
On Thu, 2021-09-30 at 00:06 +0200, Peter Rajnoha wrote:
On Tue 28 Sep 2021 12:42, Benjamin Marzinski wrote:
On Tue, Sep 28, 2021 at 03:16:08PM +0000, Martin Wilck wrote:
I have pondered this quite a bit, but I can't say I have a
concrete
plan.
To avoid depending on "udev settle", multipathd needs to
partially
revert to udev-independent device detection. At least during
initial
startup, we may encounter multipath maps with members that don't
exist
in the udev db, and we need to deal with this situation
gracefully. We
currently don't, and it's a tough problem to solve cleanly. Not
relying
on udev opens up a Pandora's box wrt WWID determination, for
example.
Any such change would without doubt carry a large risk of
regressions
in some scenarios, which we wouldn't want to happen in our large
customer's data centers.
I'm not actually sure that it's as bad as all that. We just may
need a
way for multipathd to detect if the coldplug has happened. I'm
sure if
we say we need it to remove the udev settle, we can get some method
to
check this. Perhaps there is one already, that I don't know about.
If
The coldplug events are synthesized and as such, they all now contain
SYNTH_UUID=<UUID> key-value pair with kernel>=4.13:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/testing/sysfs-uevent
I've already tried to proposee a patch for systemd/udev that would
mark
all uevents coming from the trigger (including the one used at boot
for
coldplug) with an extra key-value pair that we could easily match in
rules,
but that was not accepted. So right now, we could detect that
synthesized uevent happened, though we can't be sure it was the
actual
udev trigger at boot. For that, we'd need the extra marks. I can give
it
another try though, maybe if there are more people asking for this
functionality, we'll be at better position for this to be accepted.
That would allow us to discern synthetic events, but I'm unsure how
this what help us. Here, what matters is to figure out when we don't
expect any more of them to arrive.
I guess it would be possible to compare the list of (interesting)
devices in sysfs with the list of devices in the udev db. For
multipathd, we could
- scan set U of udev devices on startup
- scan set S of sysfs devices on startup
- listen for uevents for updating both S and U
- after each uevent, check if the difference set of S and U is emtpy
- if yes, coldplug has finished
- otherwise, continue waiting, possibly until some timeout expires.
It's more difficult for LVM because you have no daemon maintaining
state.
Another performance story:
The legacy lvm2 (2.02.xx) with lvmetad daemon, the event-activation mode
is very likely timeout on a large scale PVs.
When customer met this issue, we suggested them to disable lvmetad.
We've already dumped lvmetad. Has this also been an issue with lvm versions without lvmetad, but still using the event-activation mode? (...the lvm versions where instead of lvmetad, we use the helper files under /run/lvm to track the state of incoming PVs and VG completeness)
Also, when I tried bootup with over 1000 devices in place (though in a VM, I don't have access to real machine with so many devices), I've noticed a performance regression in libudev itself with the interface to enumerate devices (which is the default obtain_device_list_from_udev=1 in lvm.conf):
https://bugzilla.redhat.com/show_bug.cgi?id=1986158
It's very important to measure what's exactly causing the delays. And also important how we measure it - I'm not that trustful to systemd-analyze blame as it's very misty of what it is actually measuring.
I just want to say that some of the issues might simply be regressions/issues with systemd/udev that could be fixed. We as providers of block device abstractions where we need to handle, sometimes, thousands of devices, might be the first ones to hit these issues.
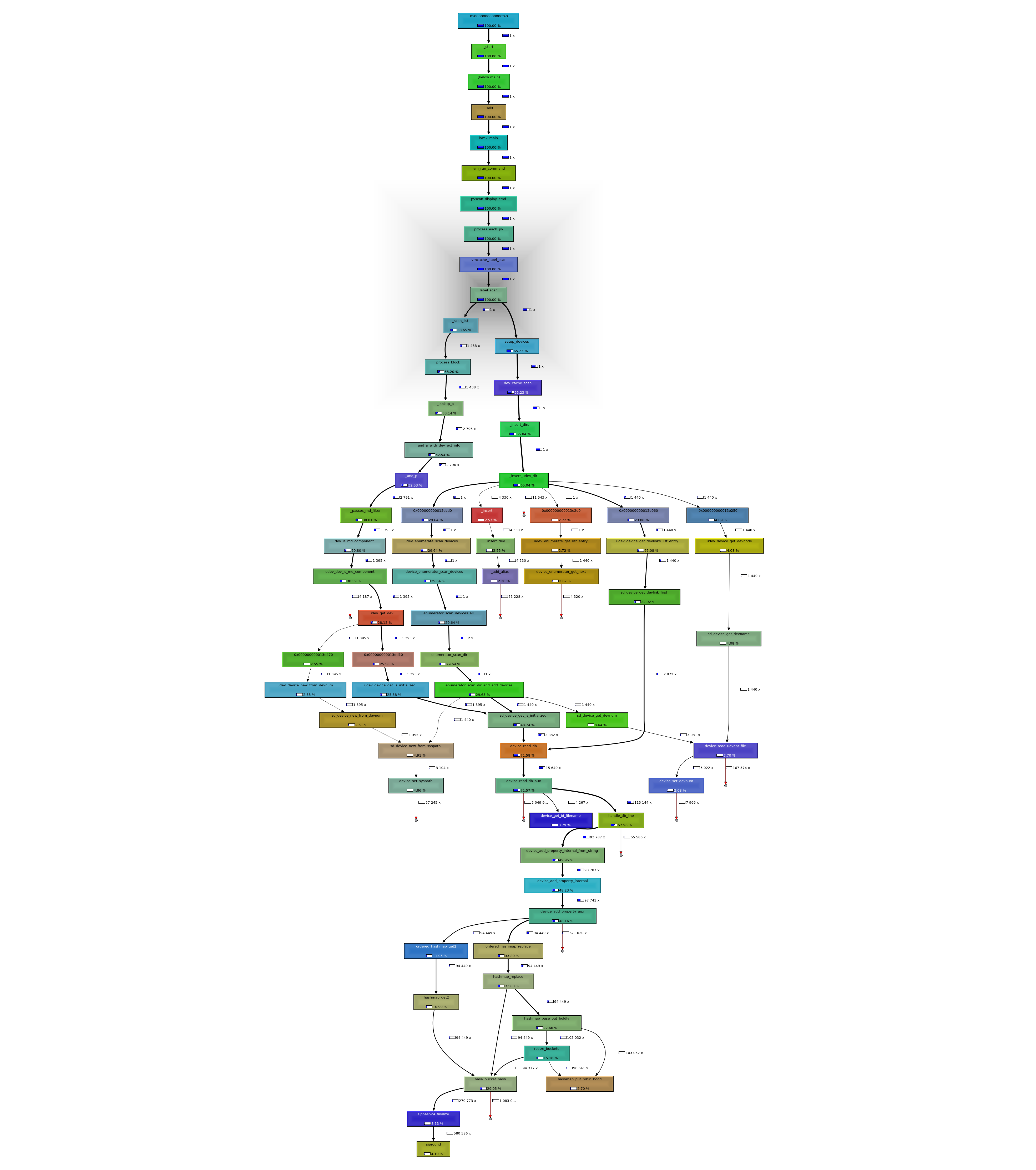
The rhel8 callgrind picture (https://prajnoha.fedorapeople.org/bz1986158/rhel8_libudev_critical_cost.png)
responds to my analysis:
https://listman.redhat.com/archives/linux-lvm/2021-June/msg00022.html
handle_db_line took too much time and become the hotspot.
Heming
_______________________________________________
linux-lvm mailing list
linux-lvm@xxxxxxxxxx
https://listman.redhat.com/mailman/listinfo/linux-lvm
read the LVM HOW-TO at http://tldp.org/HOWTO/LVM-HOWTO/

{kind=link}