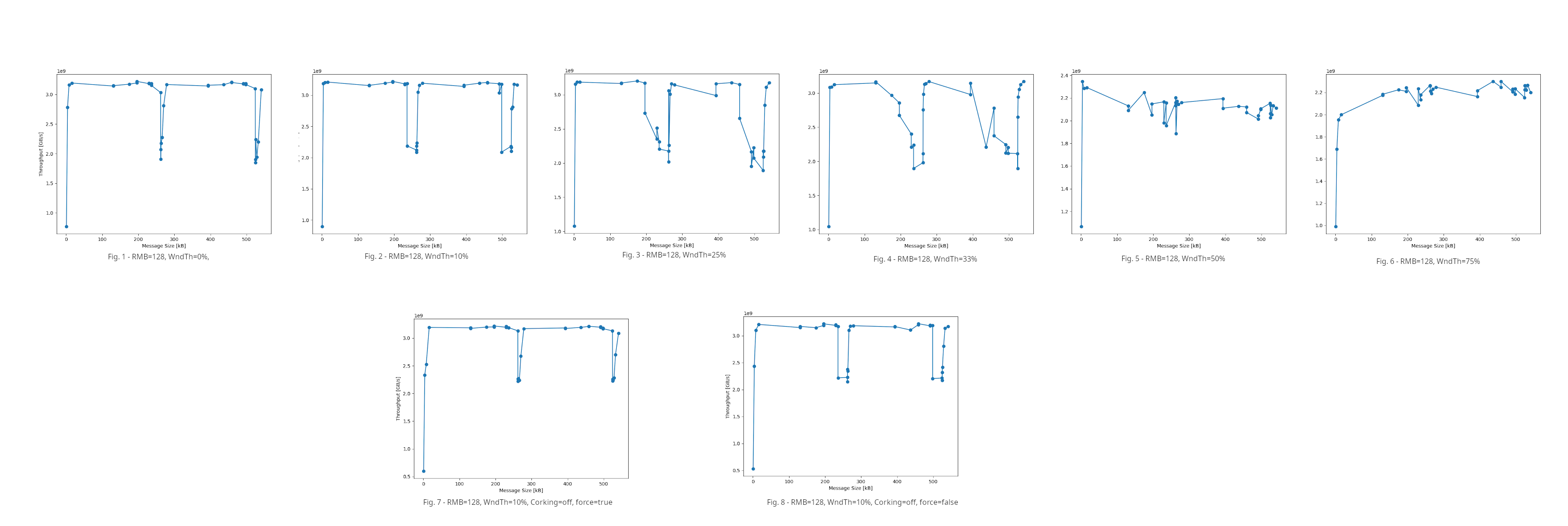
Hi Wen Gu, Cheers for looking into this. We conducted additional experiments to try to get to the bottom of it. For the sake of brevity, I'll refer to the threshold detailed in section 4.5.1 of https://datatracker.ietf.org/doc/html/rfc7609#section-4.5.1 as "window threshold", or for short WndTh. Q1: Does force=1 have the same effect as setting the window threshold to 0? Yes, it does. Figs. 1 and 7 prove that this is indeed the case. Furthermore, Fig. 7 suggests that corking has no effect. Q2: Is the width of the throughput drops proportional with RMB * WndTh% ? Yes, it is. Figs. 1 through 6 show the evolution of the drops width as the window threshold increases, with 50% and 75% cases revealing a contiguous drop with respect to the max throughput (3.2GB/s. This behaviour demonstrates that the effect of the window threshold is as expected for all cases but 0% where drops are still observed. Q3: Assuming the answer to Q2 is affirmative then setting the window threshold to 0 should make the drops disappear. Fig. 1 demonstrates that this is not the case, which makes us think that there might actually be two bugs (possibly unrelated?) causing the drops. Q4: Could corking be responsible for the drops? No. Figs. 7 and 8 still display drops in spite of corking being off. cheers, Costin PS. apologies for the chunkiness of the plots, we used a coarse sampling step to speed up the experiment. On 2024/2/5 11:50, Wen Gu wrote: > > > On 2024/2/1 21:50, Iordache Costin (XC-AS/EAE-UK) wrote: >> Hi, >> >> This is Costin, Alex's colleague. We've got additional updates which we thought would be helpful to share with the >> community. >> >> Brief reminder, our hardware/software context is as follows: >> - 2 PCs, each equipped with one Mellanox ConnectX-5 HCA (MT27800), dual port >> - only one HCA port is active/connected on each side (QSFP28 cable) >> - max HCA throughput: 25Gbps ~ 3.12GBs. >> - max/active MTU: 4096 >> - kernel: 6.5.0-14 >> - benchmarking tool: qperf 0.4.11 >> >> Our goal has been to gauge the SMC-R benefits vs TCP/IP . We are particularly interested in maximizing the throughput >> whilst reducing CPU utilisation and DRAM memory bandwidth for large data (> 2MB) transfers. >> >> Our main issue so far has been SMC-R halves the throughput for some specific message sizes (as opposed to TCP/IP) - >> see "SMC-R vs TCP" plot. >> >> Since our last post the kernel was upgraded from 5.4 to 6.5.0-14 hoping it would alleviate the throughput drops, but >> it did not, so we bit the bullet and delved into the SMC-R code. >> > > Hi Costin, > > FYI, I have also reproduced this in my environment(see attached), with Linux6.8-rc1 > > - 2 VMs, each with 2 passthrough ConnectX-4. > - kernel: Linux6.8-rc1 > - benchmarking tool: qperf 0.4.11 > > But it might take me some time to dive deeper into what exactly happened. > Hi Costin and community, I would like to share some findings with you. The performance drop might be related to the SMC window size update strategy. Under certain message sizes, the RMB utilization may drop and transmission is inefficient. SMC window size update strategy can be referred from page 63 of RFC7609: https://datatracker.ietf.org/doc/html/rfc7609#page-63 . and the linux implementation is smc_tx_consumer_update() in net/smc/smc_tx.c. " The current window size (from a sender's perspective) is less than half of the receive buffer space, and the consumer cursor update will result in a minimum increase in the window size of 10% of the receive buffer space. " void smc_tx_consumer_update(struct smc_connection *conn, bool force) { <...> if (conn->local_rx_ctrl.prod_flags.cons_curs_upd_req || force || ((to_confirm > conn->rmbe_update_limit) && ((sender_free <= (conn->rmb_desc->len / 2)) || conn->local_rx_ctrl.prod_flags.write_blocked))) { if (conn->killed || conn->local_rx_ctrl.conn_state_flags.peer_conn_abort) return; if ((smc_cdc_get_slot_and_msg_send(conn) < 0) && <- update the window !conn->killed) { queue_delayed_work(conn->lgr->tx_wq, &conn->tx_work, SMC_TX_WORK_DELAY); return; } } <...> } # Test results In my qperf test, one of performance drops can be observed when msgsize changes from (90% * RMB - 1) to (90% * RMB). Take 128KB sndbuf and RMB as an example, #sysctl net.smc.wmem=131072 # both sides #sysctl net.smc.rmem=131072 10% * RMB is 13107 bytes, so compare the qperf results when msgsize is 117964 bytes (128KB - 13107B - 1) and 117965 bytes (128KB - 13107B): - msgsize 117964 # smc_run taskset -c <serv_cpu> qperf # smc_run taskset -c <clnt_cpu> qperf <serv_ip> -m 117964 -t 10 -vu tcp_bw tcp_bw: bw = 4.12 GB/sec msg_size = 118 KB time = 10 sec CPU: %serv_cpu : 1.8 us, 54.6 sy, 0.0 ni, 42.9 id, 0.0 wa, 0.7 hi, 0.0 si, 0.0 st %clnt_cpu : 2.5 us, 40.0 sy, 0.0 ni, 57.1 id, 0.0 wa, 0.4 hi, 0.0 si, 0.0 st - msgsize 117965 # smc_run taskset -c <serv_cpu> qperf # smc_run taskset -c <clnt_cpu> qperf <serv_ip> -m 117965 -t 10 -vu tcp_bw tcp_bw: bw = 2.86 GB/sec msg_size = 118 KB time = 10 sec CPU: %serv_cpu : 1.7 us, 30.0 sy, 0.0 ni, 68.0 id, 0.0 wa, 0.3 hi, 0.0 si, 0.0 st %clnt_cpu : 1.0 us, 23.1 sy, 0.0 ni, 75.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st The bandwidth drop is obvious and the CPU utilization is relatively low. # Analysis I traced the copylen in smc_tx_sendmsg and smc_rx_recvmsg, and found that: tracepoint:smc:smc_tx_sendmsg { @tx_len = hist(args->len); } tracepoint:smc:smc_rx_recvmsg { @rx_len = hist(args->len); } - msgsize 117964 @rx_len: [4, 8) 1 | | [8, 16) 24184 |@@ | [16, 32) 40 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 177963 |@@@@@@@@@@@@@@@@@@ | [16K, 32K) 212122 |@@@@@@@@@@@@@@@@@@@@@@ | [32K, 64K) 490755 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64K, 128K) 111529 |@@@@@@@@@@@ | @tx_len: [8, 16) 30768 |@@@ | [16, 32) 61 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 138977 |@@@@@@@@@@@@@@@ | [16K, 32K) 265929 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [32K, 64K) 469183 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64K, 128K) 111082 |@@@@@@@@@@@@ | - msgsize 117965 @rx_len: [4, 8) 1 | | [8, 16) 0 | | [16, 32) 2 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 237415 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [16K, 32K) 0 | | [32K, 64K) 0 | | [64K, 128K) 237389 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | @tx_len: [16, 32) 2 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 22 | | [16K, 32K) 237357 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [32K, 64K) 23 | | [64K, 128K) 237390 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| According to the trace results, when msgsize is 117964 (good), the Tx or Rx data size are distributed between 8K-128K, but when msgsize is 117965 (bad), the Tx or Rx data size are concentrated in the two intervals [16K, 32K) and [64K, 128K). To further see what's going on, I wrote a simple reproduce program (see server.c and client.c in attachment, they transfer 10 specific size message and acts like qperf tcp_bw) and added some debug information in SMC kernel (see 0001-debug-record-cursor-update-process.patch in attachment). Then run my simple reproducer and check the dmesg. # smc_run ./server -p <serv_port> -m <msgsize: 117964 or 117965> # smc_run ./client -i <serv_ip> -p <serv_port> -m <msgsize: 117964 or 117965> According to the dmesg debug information (see dmesg.txt in attachment), we can recover how data is produced and consumed in RMB when msgsize is 117964 or 117965 (see diagram.svg in attachment, it is made based on server-side demsg information). (Please check the above diagram and dmesg information first) When msgsize is 117964 (good), each time the server consumes data in RMB, the window size will be updated to client in time (cfed cursor in linux) because the size of data consumed is always larger than 10% * RMB, and then new data can be produced in RMB. However, when msgsize is 117965 (bad), the window will only be updated when the entire 117965 bytes data has been consumed since the first part of 117965 is always no larger than 10% * RMB, which is 13107 (see diagram.svg for details). This results in low utilization of RMB. To verify this, I made a simple modification to the SMC kernel code, forcing the receiver always updates the window size. (However, this modification is far from a solution for the period drop issue, SMC window can't be always updated for silly window syndrome avoidance.) " diff --git a/net/smc/smc_rx.c b/net/smc/smc_rx.c index 9a2f3638d161..6a4d8041d6b5 100644 --- a/net/smc/smc_rx.c +++ b/net/smc/smc_rx.c @@ -61,7 +61,7 @@ static int smc_rx_update_consumer(struct smc_sock *smc, { struct smc_connection *conn = &smc->conn; struct sock *sk = &smc->sk; - bool force = false; + bool force = true; int diff, rc = 0; smc_curs_add(conn->rmb_desc->len, &cons, len); " Then run qperf test under message size of 117964 and 117965: # smc_run taskset -c <cpu> qperf <ip> -m 117964 -t 10 -vu tcp_bw tcp_bw: bw = 4.13 GB/sec msg_size = 118 KB time = 10 sec # smc_run taskset -c <cpu> qperf <ip> -m 117965 -t 10 -vu tcp_bw tcp_bw: bw = 4.18 GB/sec msg_size = 118 KB time = 10 sec The performance drop disapper, and copylen tracing results under the two msgsize are similar: - msgsize 117964 @rx_len: [4, 8) 1 | | [8, 16) 7521 | | [16, 32) 422 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 225144 |@@@@@@@@@@@@@@@@@@@@ | [16K, 32K) 311010 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [32K, 64K) 571816 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64K, 128K) 62061 |@@@@@ | - msgsize 117965 @rx_len: [2, 4) 54360 |@@@@ | [4, 8) 1025 | | [8, 16) 2 | | [16, 32) 2 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 1 | | [256, 512) 0 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 214217 |@@@@@@@@@@@@@@@@@@ | [16K, 32K) 288575 |@@@@@@@@@@@@@@@@@@@@@@@@@ | [32K, 64K) 593644 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64K, 128K) 50187 |@@@@ | Hope the above analysis can be of some help for you. Thanks, Wen Gu >> The SMC-R source code revealed that __smc_buf_create / smc_compress_bufsize functions are in charge of computing the >> size of the RMB buffer and allocating either physical or virtual contiguous memory. We suspected that the throughput >> drops were caused by the size of this buffer being too small. >> >> We set out to determine whether there is a correlation between the drops and the size of the RMB buffer, and for that >> we set the size of the RMB buffer to 128KB, 256KB, 512KB, 1MB, 2MB, 4MB and 8MB and benchmarked the throughput for >> different message size ranges. >> >> The attached plot collates the benchmark results and shows that the period of the drops coincides with the size of the >> RMB buffer. Whilst increasing the size of the buffer seems to attenuate the throughput drops, we believe that the real >> root of the drops might lie somewhere else in the SMC-R code. We are suspecting that, for reasons unknown to us, the >> CDC messages that are sent after the RDMA WRITE operation are delayed in some circumstances. >> >> cheers, >> Costin. >> >> PS. for the sake of brevity many details have been omitted on purpose but we'd be happy to provide them if need be, >> e.g. by default the RMB buffer size is capped to 512KB so we remove the cap and recompile the SMC module; we use >> alternative tools such as iperf and iperf 3 for benchmarking to dismiss the possibility of the drops to be tool >> specific; corking has been disabled; etc.
Attachment:
threshold_cork.png
Description: threshold_cork.png

{kind=link}