On 2024/2/1 21:50, Iordache Costin (XC-AS/EAE-UK) wrote:
Hi,
This is Costin, Alex's colleague. We've got additional updates which we thought would be helpful to share with the community.
Brief reminder, our hardware/software context is as follows:
- 2 PCs, each equipped with one Mellanox ConnectX-5 HCA (MT27800), dual port
- only one HCA port is active/connected on each side (QSFP28 cable)
- max HCA throughput: 25Gbps ~ 3.12GBs.
- max/active MTU: 4096
- kernel: 6.5.0-14
- benchmarking tool: qperf 0.4.11
Our goal has been to gauge the SMC-R benefits vs TCP/IP . We are particularly interested in maximizing the throughput whilst reducing CPU utilisation and DRAM memory bandwidth for large data (> 2MB) transfers.
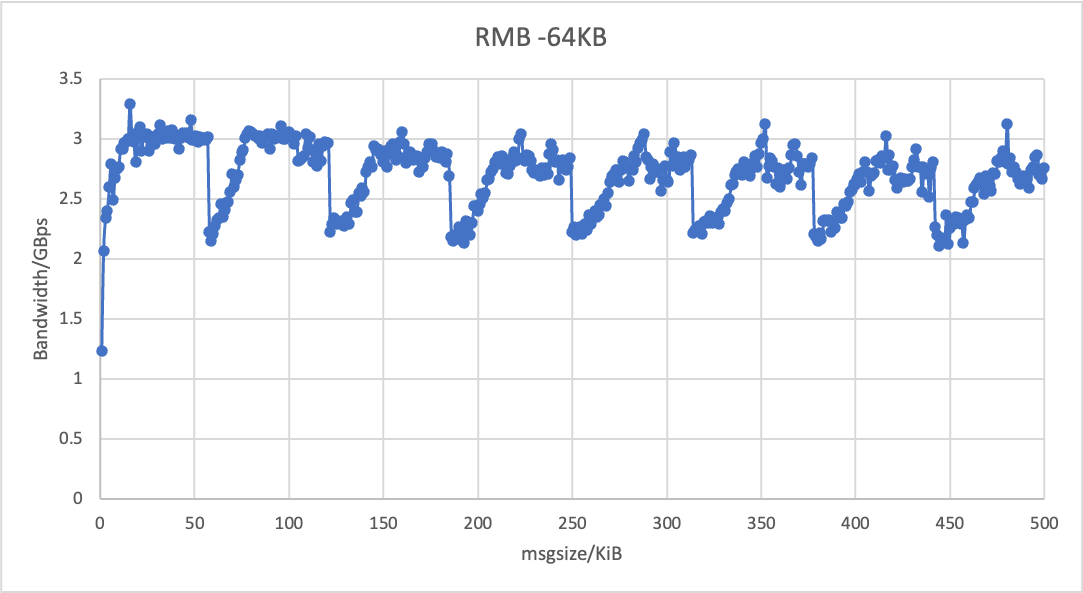
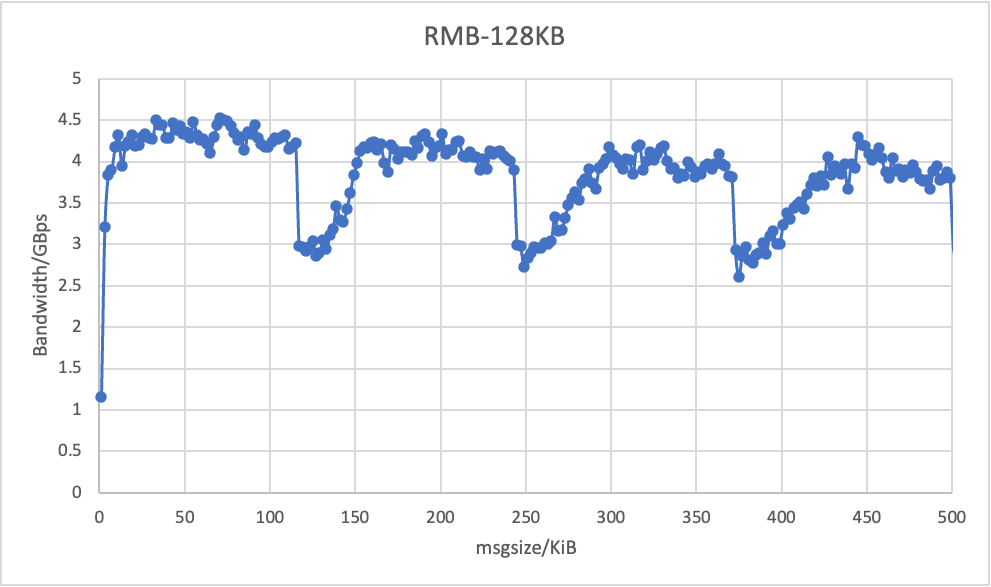
Our main issue so far has been SMC-R halves the throughput for some specific message sizes (as opposed to TCP/IP) - see "SMC-R vs TCP" plot.
Since our last post the kernel was upgraded from 5.4 to 6.5.0-14 hoping it would alleviate the throughput drops, but it did not, so we bit the bullet and delved into the SMC-R code.
Hi Costin, FYI, I have also reproduced this in my environment(see attached), with Linux6.8-rc1 - 2 VMs, each with 2 passthrough ConnectX-4. - kernel: Linux6.8-rc1 - benchmarking tool: qperf 0.4.11 But it might take me some time to dive deeper into what exactly happened.
The SMC-R source code revealed that __smc_buf_create / smc_compress_bufsize functions are in charge of computing the size of the RMB buffer and allocating either physical or virtual contiguous memory. We suspected that the throughput drops were caused by the size of this buffer being too small. We set out to determine whether there is a correlation between the drops and the size of the RMB buffer, and for that we set the size of the RMB buffer to 128KB, 256KB, 512KB, 1MB, 2MB, 4MB and 8MB and benchmarked the throughput for different message size ranges. The attached plot collates the benchmark results and shows that the period of the drops coincides with the size of the RMB buffer. Whilst increasing the size of the buffer seems to attenuate the throughput drops, we believe that the real root of the drops might lie somewhere else in the SMC-R code. We are suspecting that, for reasons unknown to us, the CDC messages that are sent after the RDMA WRITE operation are delayed in some circumstances. cheers, Costin. PS. for the sake of brevity many details have been omitted on purpose but we'd be happy to provide them if need be, e.g. by default the RMB buffer size is capped to 512KB so we remove the cap and recompile the SMC module; we use alternative tools such as iperf and iperf 3 for benchmarking to dismiss the possibility of the drops to be tool specific; corking has been disabled; etc.
Attachment:
RMB-64KB.png
Description: PNG image
Attachment:
RMB-128KB.png
Description: PNG image

{kind=link}
{kind=link}