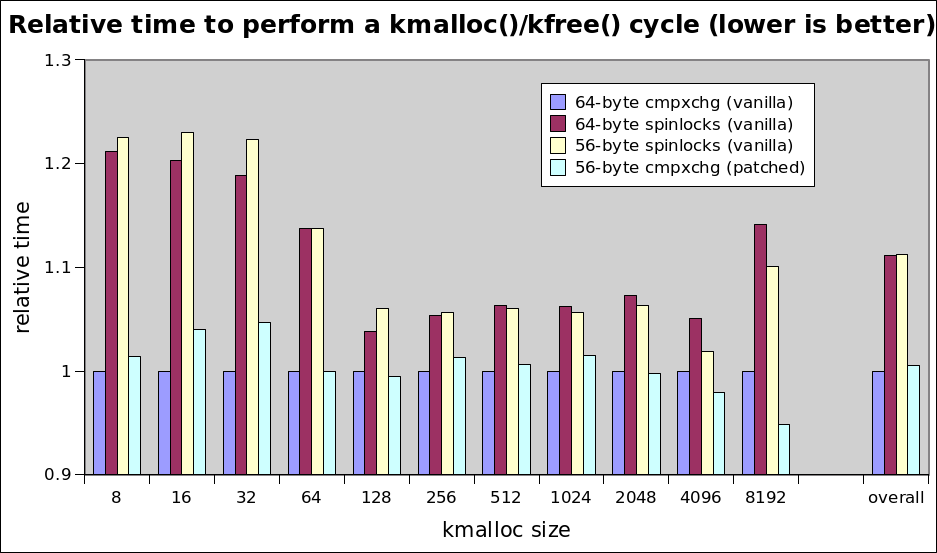
On Mon, 2014-01-13 at 10:44 +0900, Joonsoo Kim wrote: > On Sat, Jan 11, 2014 at 06:55:39PM -0600, Christoph Lameter wrote: > > On Sat, 11 Jan 2014, Pekka Enberg wrote: > > > > > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <dave@xxxxxxxx> wrote: > > > > On 01/10/2014 03:39 PM, Andrew Morton wrote: > > > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The > > > >>> first 3 are with vanilla upstream kernel source. The 4th is patched > > > >>> with my new slub code (all single-threaded): > > > >>> > > > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png > > > >> > > > >> So we're converging on the most complex option. argh. > > > > > > > > Yeah, looks that way. > > > > > > Seems like a reasonable compromise between memory usage and allocation speed. > > > > > > Christoph? > > > > Fundamentally I think this is good. I need to look at the details but I am > > only going to be able to do that next week when I am back in the office. > > Hello, > > I have another guess about the performance result although I didn't look at > these patches in detail. I guess that performance win of 64-byte sturct on > small allocations can be caused by low latency when accessing slub's metadata, > that is, struct page. > > Following is pages per slab via '/proc/slabinfo'. > > size pages per slab > ... > 256 1 > 512 1 > 1024 2 > 2048 4 > 4096 8 > 8192 8 > > We only touch one struct page on small allocation. > In 64-byte case, we always use one cacheline for touching struct page, since > it is aligned to cacheline size. However, in 56-byte case, we possibly use > two cachelines because struct page isn't aligned to cacheline size. > > This aspect can change on large allocation cases. For example, consider > 4096-byte allocation case. In 64-byte case, it always touches 8 cachelines > for metadata, however, in 56-byte case, it touches 7 or 8 cachelines since > 8 struct page occupies 8 * 56 bytes memory, that is, 7 cacheline size. > > This guess may be wrong, so if you think it wrong, please ignore it. :) > > And I have another opinion on this patchset. Diminishing struct page size > will affect other usecases beside the slub. As we know, Dave found this > by doing sequential 'dd'. I think that it may be the best case for 56-byte case. > If we randomly touch the struct page, this un-alignment can cause regression > since touching the struct page will cause two cachline misses. So, I think > that it is better to get more benchmark results to this patchset for convincing > ourselves. If possible, how about asking Fengguang to run whole set of > his benchmarks before going forward? Cc'ing him. -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxx. For more info on Linux MM, see: http://www.linux-mm.org/ . Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}