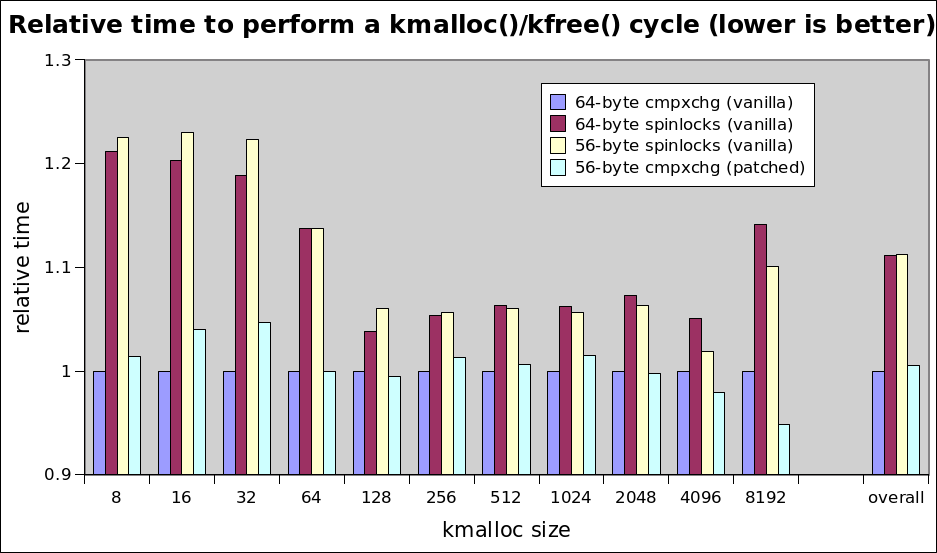
On Fri, 10 Jan 2014 12:52:32 -0800 Dave Hansen <dave@xxxxxxxx> wrote: > On 01/05/2014 08:32 PM, Joonsoo Kim wrote: > > On Fri, Jan 03, 2014 at 02:18:16PM -0800, Andrew Morton wrote: > >> On Fri, 03 Jan 2014 10:01:47 -0800 Dave Hansen <dave@xxxxxxxx> wrote: > >>> SLUB depends on a 16-byte cmpxchg for an optimization which > >>> allows it to not disable interrupts in its fast path. This > >>> optimization has some small but measurable benefits: > >>> > >>> http://lkml.kernel.org/r/52B345A3.6090700@xxxxxxxx > >> > >> So really the only significant benefit from the cmpxchg16 is with > >> cache-cold eight-byte kmalloc/kfree? 8% faster in this case? But with > >> cache-hot kmalloc/kfree the benefit of cmpxchg16 is precisely zero. > > > > I guess that cmpxchg16 is not used in this cache-hot kmalloc/kfree test, > > because kfree would be done in free fast-path. In this case, > > this_cpu_cmpxchg_double() would be called, so you cannot find any effect > > of cmpxchg16. > > That's a good point. I also confirmed this theory with the > free_{fast,slow}path slub counters. So, I ran another round of tests. > > One important difference from the last round: I'm now writing to each > allocation. I originally did this so that I could store the allocations > in a linked-list, but I also realized that it's important. It's rare in > practice to do an allocation and not write _something_ to it. This > change adds a bit of cache pressure which changed the results pretty > substantially. > > I tested 4 cases, all of these on the "cache-cold kfree()" case. The > first 3 are with vanilla upstream kernel source. The 4th is patched > with my new slub code (all single-threaded): > > http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png So we're converging on the most complex option. argh. > There are a few important takeaways here: > 1. The double-cmpxchg optimization has a measurable benefit > 2. 64-byte 'struct page' is faster than the 56-byte one independent of > the cmpxchg optimization. Maybe because foo/sizeof(struct page) is > then a simple shift. > 3. My new code is probably _slightly_ slower than the existing code, > but still has the huge space savings > 4. All of these deltas are greatly magnified here and are hard or > impossible to demonstrate in practice. > > Why does the double-cmpxchg help? The extra cache references that it > takes to go out and touch the paravirt structures and task struct to > disable interrupts in the spinlock cases start to show up and hurt our > allocation rates by about 30%. So all this testing was performed in a VM? If so, how much is that likely to have impacted the results? > This advantage starts to evaporate when > there is more noise in the caches, or when we start to run the tests > across more cores. > > But the real question here is whether we can shrink 'struct page'. The > existing (64-byte struct page) slub code wins on allocations under 256b > by as much as 5% (the 32-byte kmalloc()), but my new code wins on > allocations over 1k. 4k allocations just happen to be the most common > on my systems, and they're also very near the "sweet spot" for the new > code. But, the delta here is _much_ smaller that it was in the spinlock > vs. cmpxchg cases. This advantage also evaporates when we run things > across more cores or in less synthetic benchmarks. > > I also explored that 5% hit that my code caused in the 32-byte > allocation case. It looked to me to be mostly explained by the code > that I added. There were more instructions executed and the > cycles-per-instruction went down. This looks to be mostly due to a ~15% > increase in branch misses, probably from the increased code size and > complexity. > > This is the perf stat output for a run doing 16.8M kmalloc(32)/kfree()'s: > vanilla: > > 883,412 LLC-loads # 0.296 M/sec [39.76%] > > 566,546 LLC-load-misses # 64.13% of all LL-cache hits [39.98%] > patched: > > 556,751 LLC-loads # 0.186 M/sec [39.86%] > > 339,106 LLC-load-misses # 60.91% of all LL-cache hits [39.72%] > > My best guess is that most of the LLC references are going out and > touching the struct pages for slab management. It's why we see such a > big change. -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxx. For more info on Linux MM, see: http://www.linux-mm.org/ . Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}