Thanks for testing, and sorry for confusion. It’s a quite complex problem, so please feel free to ask me.
1. nr_range is the number of page ranges to allocate (ie. the number of struct range in the flex array), not the number of pages.
Thanks for the correction, I misunderstood its role, but problem still remains. I have added some additional explanation below.
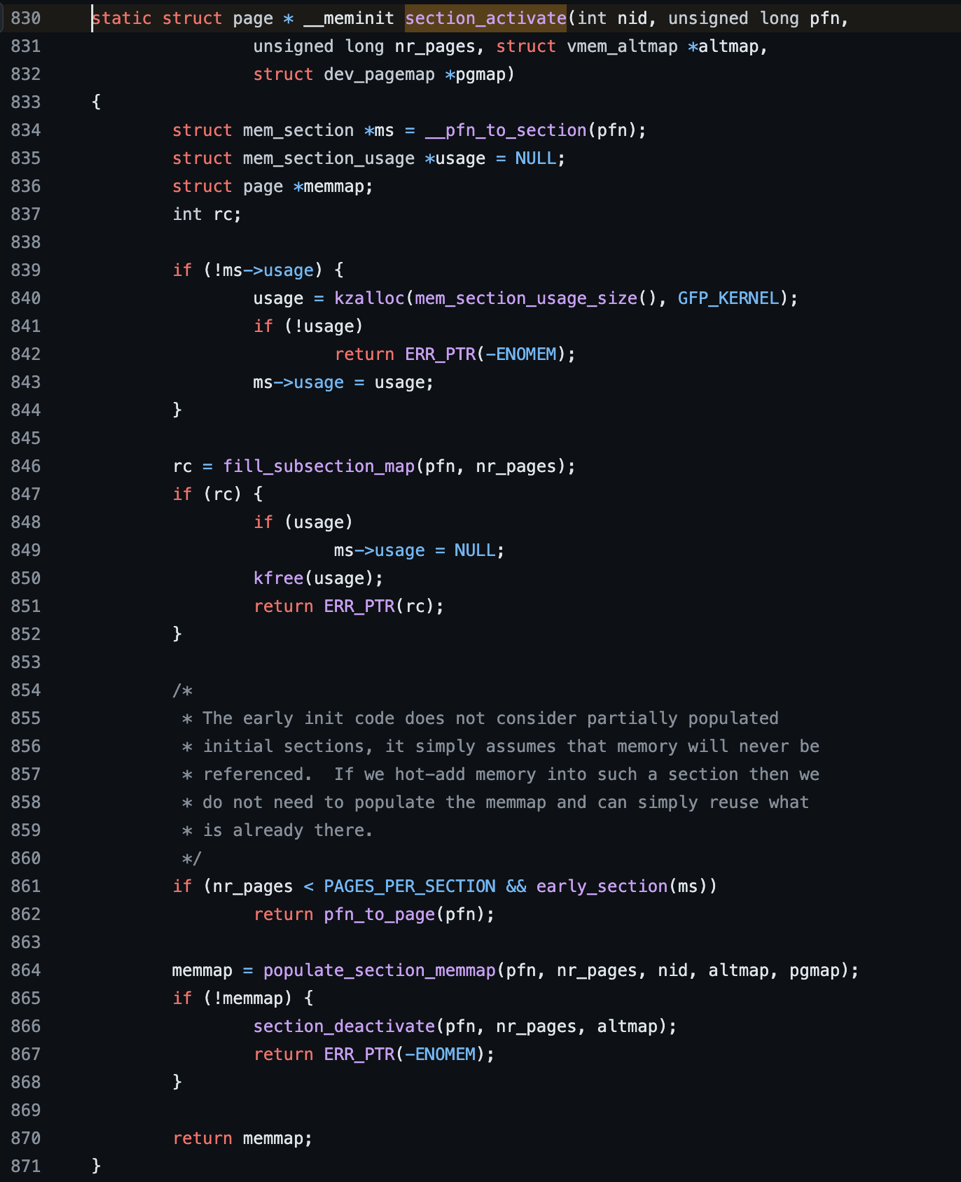
Figure 1. section_activate
Above figure 1 section_activate function is called by memremap_pages > pagemap_range > add_pages > section_activate. If line 864 in the section_activate function fails and returns -ENOMEM, the subsequent error handling code does not clear the subsection_map bit masked from line 846.
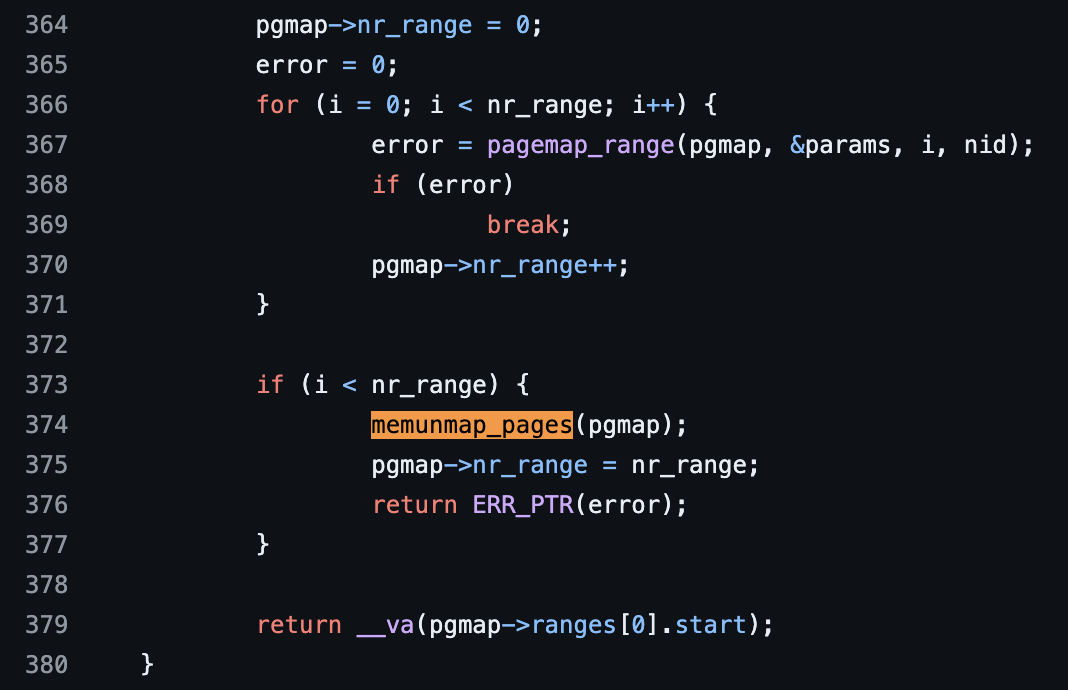
Figure 2. memremap_pages
The memunmap_pages function on line 374 is now responsible for clearing the subsection_map bits masked from pagemap_range on line 367. However, because pgmap->nr_range is not incremented after the subsection_map is masked (as pgmap->nr_range++ on line 370 is never executed due to an -ENOMEM error from pagemap_range), memunmap_pagescannot be executed. Consequently, the masked bits in the subsection_map are not cleared. This leads to subsequent processes that attempt to use the same page frame number encountering an -EEXIST error, as shown in Figure 1 on lines 846 and 851.
2. Even if that were the case it shouldn’ cause the below issue as the driver needs to deal with the failure. It appears that memremap_pages is used to map MMIO ranges during the initialization stage of a process. For instance, in NVIDIA CUDA, the CUDA driver calls a sequence of functions to link the GPU with the newly initialized process. These functions include add_gpu and meminit_gpu, which are part of the driver's code, and memremap_pages, which is a Linux function called by the driver's code. At this stage, one might reasonably assume that memremap_pages returns initialized data structures and memory space. However, this is not the case. It retains dirty data and does not clear it under the specified conditions (as seen in Error 867, Figure 1, where a dirty subsection_map is retained). Although the function has error handling code intended to initialize the entire allocated data structures under error conditions, it does not work as intended.
3. The strange thing here is that cudaMalloc doesn't use the kernel path mentioned above. As you mentioned, cudaMalloc does not utilize the kernel path. However, when a process using the CUDA driver initializes, it first calls a sequence of functions that link the process with the GPU. During this stage, memremap_pages is used, not during cudaMalloc. This detail might seem trivial, but functions such as add_gpu, init_gpu, uvm_pmm_gpu_init, and devmem_init in the CUDA driver code are invoked during the initialization of every CUDA process. Specifically, the devmem_init function in the driver code calls memremap_pages. Here is the relevant NVIDIA driver code that calls memremap_pages in Linux (devmem_init): https://github.com/NVIDIA/open-gpu-kernel-modules/blob/main/kernel-open/nvidia-uvm/uvm_pmm_gpu.c#L3493
2024. 6. 11. 오전 11:35, Alistair Popple <apopple@xxxxxxxxxx> 작성:
노시현 / 학생 / 전기·정보공학부 <sihyeonroh@xxxxxxxxx> writes: It is an obvious linux kernel bug (wrong clearance of used data while error handling), and kernel drivers using this function can be affected.
I wouldn't rule out the possiblity that this is a driver rather than kernel bug either. I will need to go look at the kernel code more closely but are you saying that after a driver calls a sequence of memremap_pages()/memunmap_pages() that any subsequent call to memremap_pages() will fail? Even if that were the case it shouldn't cause the below issue as the driver needs to deal with the failure. So I am having a bit of a hard time following some of the reasoning, comments below. 1. Summary: Due to a bug in the Linux kernel, devices using the Linux kernel API cannot guarantee fault isolation between processes.
2. Full Description of the Problem
(1) Overview of Problematic Functions
This section provides an overview of problematic functions, briefly explaining their purposes. Following three functions are responsible for handling the bug, broken device fault isolation. two are defined in <linux/mm/memremap.c>, and the other is defined in <linux/mm/sparse.c>. Function name, location, and brief explanation for understanding the problem are specified below.
Function 1. <memremap_pages>
Source path: linux/mm/memremap.c
[cid:995e2ceb-43a8-4818-a023-9817801ac767]
Function 2. <section_activate>
(called by pagemap_range > add_pages > __add_pages > sparse_add_section > section_activate)
Source path: linux/mm/sparse.c
[cid:7ce32169-d894-452f-bc90-0036849ce79a]
Function 3. <memunmap_pages>
(called by memremap_pages > section_activate)
Source path: linux/mm/memremap.c
[cid:e90f753d-25b6-465f-b4f8-214ca254da00]
(2) Bug Triggering Flow
Let’s begin with assuming that process A calls memremap_pages with nr_range (the number of pages to allocate) 1.
Nit: nr_range is the number of page ranges to allocate (ie. the number of struct range in the flex array), not the number of pages. Each range can contain multiple pages as controlled by range.start/end. [cid:ec1e9d21-b358-4ff1-af38-da1a43ca7cd0]
Above flow shows that if allocating memory in 864 line of section_activate function fails, the subsection_map masked by process A can never be cleared. This is because pageunmap_range is responsible for clearing subsection_map mask bit, but it can’t be called due to wrong nr_range count.
As the mask bit of subsection_map is not cleared, following call of memremap_pages from other processes ends up with failure, because given pfn is masked as busy by process A.
[cid:993c1924-9680-4981-8b99-0436b7e7a5c7]An error occurred in process A affects other processes using same pfn, which is usually the case of the processes that share the device with process A. The device driver using this linux kernel api can cause fatal vulnerability in security perspective. For example, NVIDIA guarantees GPU users a fault isolation between GPU-using processes. What makes the situation worse in CUDA programming is that checking for GPU errors is the user's responsibility. So, If users believe that GPU has a robust fault isolation, and uses it like TPM[1] or Security Engine Accelerator[2, 3], attacker can use this vulnerability to tear down GPU-based security systems.
(3) Bug usage by an attacker
Followings show how attackers can use this vulnerability, in security perspective.
[cid:c5b488fa-9ca1-4d44-99f8-847ca63d0387]
This is a classical parallel AES encryption implementation using CUDA, which tries to accelerate AES encryption through GPU.
Source code is from github repository, https://github.com/allenlee820202/Parallel-AES-Algorithm-using-CUDA.
This application encrypts strings, “Hello World!” written in novel.txt, using AES keys in key.txt. The encryption’s result is written into encrypt.txt, and its decryption is written into decrypt.txt.
[cid:b19783df-cf21-4659-9952-0d8ba6d18ad3]
[cid:a12df0c2-01e4-4564-8fee-05d9978abc9f]
You can see that encryption (“Hello world!” in novel.txt is encrypted into “d5 68 … “ in encrypt.txt) works well. However, in case this bug is triggered by another process using same GPU driver, the following shows GPU does not work, and encryption fails, resulting in plain text is stored in encrypt.txt.
[cid:1920d919-2658-4c49-9add-fa2148f9515e]
(4) Proof of Concept
You can test above cases by following codes. It needs 2 applications to trigger the bug.
(4.1) DRAM-overuse application
#include <stdlib.h>
int main(int argc, char* argv[])
{
while(1) {
int *dummy = (int *) malloc (4096);
}
return 0;
}
(4.2) Normal CUDA-using application
#include <cuda_runtime.h>
__global__ void cuda_function (float *input)
{
if (blockDim.x * blockIdx.x + threadIdx.x < 512) {
input[blockDim.x * blockIdx.x + threadIdx.x] += 1.0;
}
}
int main(int argc, char* argv[])
{
float *input;
float *comp = (float *) malloc(512 * sizeof(float));
cudaMalloc(&input, 512*sizeof(float));
The strange thing here is that cudaMalloc doesn't use the kernel paths mentioned above. cuda_function<<<16, 32>>>(input);
cudaMemcpy(&comp, input, 512 * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
First, multiple DRAM-overuse applications should be executed background, so that they fill DRAM free area.
Second, While Swap in and out pages frequently occur in DRAM, execute Normal CUDA-using application multiple times.
Third, When CUDA-using application fails its execution due to the bug specified in (4) bug triggering flow, All following applications using CUDA driver cannot be executed normally.
3. Keywords: device, driver, kernel, memory, allocation
4. Kernel Version: From Old to Latest Kernel version, All versions are affected.
5. Bug Fix.
Solution is simple. Clearing subsection_map’s mask in section_deactivate with correct nr_range counts, and deleting subsection_map unmasking role in memunmap_pages can be a solution
References
[1] PixelVault: Using GPUs for Securing Cryptographic Operations, CCS, 2014, Giorgos Vasiliadis, et al.
[2] A framework for GPU-accelerated AES-XTS encryption in mobile devices, TENCON 2011, Mohammad Ahmed Alomari, et al.
[3] https://github.com/allenlee820202/Parallel-AES-Algorithm-using-CUDA
Thanks,
Sihyun Roh.
________________________________
From: Greg KH <gregkh@xxxxxxxxxxxxxxxxxxx>
Sent: Tuesday, June 11, 2024 12:05 AM
To: �������� / �л� / ���⡤�������к� <sihyeonroh@xxxxxxxxx>
Cc: akpm@xxxxxxxxxxxxxxxxxxxx <akpm@xxxxxxxxxxxxxxxxxxxx>; security@xxxxxxxxxx <security@xxxxxxxxxx>; linux-mm@xxxxxxxxx <linux-mm@xxxxxxxxx>
Subject: Re: [Linux bug report] A bug breaking device drivers' fault isolation guarantees
On Mon, Jun 10, 2024 at 02:58:16PM +0000, �������� / �л� / ���⡤�������к� wrote:
Hi,
I'm Sihyun Roh, a security researcher at Compsec Lab, Seoul National University.
While testing NVIDIA GPU code, I discovered a minor mistake in the
Linux kernel code. This issue can cause one process's fault to
affect other processes, compromising the fault isolation
guarantee. Given the potential security implications, I am
forwarding this to the security team as well.
If you have any questions, feel free to ask.
Thank you for your efforts in maintaining the Linux kernel code.
Sincerely,
Sihyun
For obvious reasons we can't open unsolicited .pdf files. Can you send
this in text format?
And if this is for an out-of-tree kernel driver, there's nothing we can
do about that :(
thanks,
greg k-h
|