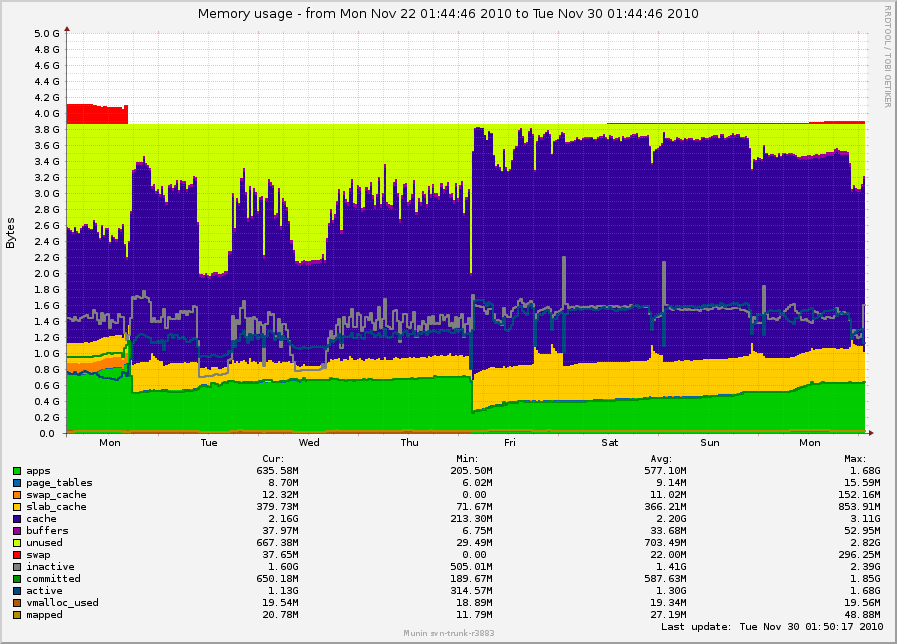
On Thu, Nov 25, 2010 at 04:12:38PM +0000, Mel Gorman wrote: > On Thu, Nov 25, 2010 at 01:03:28AM -0800, Simon Kirby wrote: > > > > <SNIP> > > > > > > > > This x86_64 box has 4 GB of RAM; zones are set up as follows: > > > > > > > > [ 0.000000] Zone PFN ranges: > > > > [ 0.000000] DMA 0x00000001 -> 0x00001000 > > > > [ 0.000000] DMA32 0x00001000 -> 0x00100000 > > > > [ 0.000000] Normal 0x00100000 -> 0x00130000 > > Ok. A consequence of this is that kswapd balancing a node will still try > to balance Normal even if DMA32 has enough memory. This could account > for some of kswapd being mean. This seemed to be the case. DMA32 would be freed until watermarks were met, and then it would fight order-0 allocations in Normal to try to meet the watermark there, even though DMA32 had more than enough free. > > > > The fact that so much stuff is evicted just because order-3 hits 0 is > > > > crazy, especially when larger order pages are still free. It seems like > > > > we're trying to keep large orders free here. Why? > > Watermarks. The steady stream of order-3 allocations is telling the > allocator and kswapd that these size pages must be available. It doesn't > know that slub can happily fall back to smaller pages because that > information is lost. Even removing __GFP_WAIT won't help because kswapd > still gets woken up for atomic allocation requests. Since slub has a fallback to s->min (order 0 in this case), I think it makes sense to make a GFP_NOBALANCE / GFP_NOKSWAPD, or GFP_NORECLAIM (allow compaction if compiled, since slub's purpose is to reduce object container waste). > > The funny thing here is that slub.c's allocate_slab() calls alloc_pages() > > with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a > > lower order allocation automatically if it fails. This is why there is > > no allocation failure warning when this happens. However, it is too late > > -- kswapd is woken and it ties to bring order 3 up to the watermark. > > If we hacked __alloc_pages_slowpath() to not wake kswapd when > > __GFP_NOWARN is set, we would never see this problem and the slub > > optimization might still mostly work. > > Yes, but we'd see more high-order atomic allocation (e.g. jumbo frames) > failures as a result so that fix would cause other regressions. The part of your patch that fixes the SWAP_CLUSTER_MAX also increases this chance. > I think there are at least two fixes required here. > > 1. sleeping_prematurely() must be aware that balance_pgdat() has dropped > the order. > 2. kswapd is trying to balance all zones for higher orders even though > it doesn't really have to. > > This patch has potential fixes for both of these problems. I have a split-out > series but I'm posting it as a single patch so see if it allows kswapd to > go to sleep as expected for you and whether it stops hammering the Normal > zone unnecessarily. I tested it locally here (albeit with compaction > enabled) and it did reduce the amount of time kswapd spent awake. Ok, so this patch has been running in production since Friday, and there is a definite improvement in our case. The reading of daemons and core system stuff back into memory all the time from /dev/sda has stopped, since kswapd now actually sleeps. Since this allows caching to work, we can keep swap enabled. However, my userspace reimplementation of zone_watermark_ok(order=3) shows that order-3 is almost never reached now. It's not freeing The Right Stuff, or not enough of it before SWAP_CLUSTER_MAX. Also, as the days go by, it is still keeping more and more free memory. my whitespace-compressed buddyinfo+extras right now shows: DMA32 234402 493 2 3 2 2 2 0 0 0 0 235644 249 <= 512 Normal 369 5 3 7 1 0 0 0 0 0 0 463 87 <= 238 So, the order-3 watermarks are still not met, and the free order-0 free pages seems to keep rising. Here is the munin memory graph of the week: http://0x.ca/sim/ref/2.6.36/memory_mel_patch_4days.png Things seem to be drifting to kswapd reclaiming order-0 in a way that doesn't add up to more order-3 blocks available, so fragmentation is increasing. You mentioned that there was some mechanism to have it actually target allocations that could be made into higher order allocations? Simon- > ==== CUT HERE ==== > diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h > index 39c24eb..25fe08d 100644 > --- a/include/linux/mmzone.h > +++ b/include/linux/mmzone.h > @@ -645,6 +645,7 @@ typedef struct pglist_data { > wait_queue_head_t kswapd_wait; > struct task_struct *kswapd; > int kswapd_max_order; > + enum zone_type high_zoneidx; > } pg_data_t; > > #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages) > @@ -660,7 +661,7 @@ typedef struct pglist_data { > > extern struct mutex zonelists_mutex; > void build_all_zonelists(void *data); > -void wakeup_kswapd(struct zone *zone, int order); > +void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx); > int zone_watermark_ok(struct zone *z, int order, unsigned long mark, > int classzone_idx, int alloc_flags); > enum memmap_context { > diff --git a/mm/page_alloc.c b/mm/page_alloc.c > index 07a6544..344b597 100644 > --- a/mm/page_alloc.c > +++ b/mm/page_alloc.c > @@ -1921,7 +1921,7 @@ void wake_all_kswapd(unsigned int order, struct zonelist *zonelist, > struct zone *zone; > > for_each_zone_zonelist(zone, z, zonelist, high_zoneidx) > - wakeup_kswapd(zone, order); > + wakeup_kswapd(zone, order, high_zoneidx); > } > > static inline int > diff --git a/mm/vmscan.c b/mm/vmscan.c > index d31d7ce..00529a0 100644 > --- a/mm/vmscan.c > +++ b/mm/vmscan.c > @@ -2118,15 +2118,17 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont, > #endif > > /* is kswapd sleeping prematurely? */ > -static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining) > +static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining) > { > int i; > + bool all_zones_ok = true; > + bool any_zone_ok = false; > > /* If a direct reclaimer woke kswapd within HZ/10, it's premature */ > if (remaining) > return 1; > > - /* If after HZ/10, a zone is below the high mark, it's premature */ > + /* Check the watermark levels */ > for (i = 0; i < pgdat->nr_zones; i++) { > struct zone *zone = pgdat->node_zones + i; > > @@ -2138,10 +2140,20 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining) > > if (!zone_watermark_ok(zone, order, high_wmark_pages(zone), > 0, 0)) > - return 1; > + all_zones_ok = false; > + else > + any_zone_ok = true; > } > > - return 0; > + /* > + * For high-order requests, any zone meeting the watermark is enough > + * to allow kswapd go back to sleep > + * For order-0, all zones must be balanced > + */ > + if (order) > + return !any_zone_ok; > + else > + return !all_zones_ok; > } > > /* > @@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining) > static unsigned long balance_pgdat(pg_data_t *pgdat, int order) > { > int all_zones_ok; > + int any_zone_ok; > int priority; > int i; > unsigned long total_scanned; > @@ -2201,6 +2214,7 @@ loop_again: > disable_swap_token(); > > all_zones_ok = 1; > + any_zone_ok = 0; > > /* > * Scan in the highmem->dma direction for the highest > @@ -2310,10 +2324,12 @@ loop_again: > * spectulatively avoid congestion waits > */ > zone_clear_flag(zone, ZONE_CONGESTED); > + if (i <= pgdat->high_zoneidx) > + any_zone_ok = 1; > } > > } > - if (all_zones_ok) > + if (all_zones_ok || (order && any_zone_ok)) > break; /* kswapd: all done */ > /* > * OK, kswapd is getting into trouble. Take a nap, then take > @@ -2336,7 +2352,7 @@ loop_again: > break; > } > out: > - if (!all_zones_ok) { > + if (!(all_zones_ok || (order && any_zone_ok))) { > cond_resched(); > > try_to_freeze(); > @@ -2361,7 +2377,13 @@ out: > goto loop_again; > } > > - return sc.nr_reclaimed; > + /* > + * Return the order we were reclaiming at so sleeping_prematurely() > + * makes a decision on the order we were last reclaiming at. However, > + * if another caller entered the allocator slow path while kswapd > + * was awake, order will remain at the higher level > + */ > + return order; > } > > /* > @@ -2417,6 +2439,7 @@ static int kswapd(void *p) > prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE); > new_order = pgdat->kswapd_max_order; > pgdat->kswapd_max_order = 0; > + pgdat->high_zoneidx = MAX_ORDER; > if (order < new_order) { > /* > * Don't sleep if someone wants a larger 'order' > @@ -2464,7 +2487,7 @@ static int kswapd(void *p) > */ > if (!ret) { > trace_mm_vmscan_kswapd_wake(pgdat->node_id, order); > - balance_pgdat(pgdat, order); > + order = balance_pgdat(pgdat, order); > } > } > return 0; > @@ -2473,7 +2496,7 @@ static int kswapd(void *p) > /* > * A zone is low on free memory, so wake its kswapd task to service it. > */ > -void wakeup_kswapd(struct zone *zone, int order) > +void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx) > { > pg_data_t *pgdat; > > @@ -2483,8 +2506,10 @@ void wakeup_kswapd(struct zone *zone, int order) > pgdat = zone->zone_pgdat; > if (zone_watermark_ok(zone, order, low_wmark_pages(zone), 0, 0)) > return; > - if (pgdat->kswapd_max_order < order) > + if (pgdat->kswapd_max_order < order) { > pgdat->kswapd_max_order = order; > + pgdat->high_zoneidx = min(pgdat->high_zoneidx, high_zoneidx); > + } > trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order); > if (!cpuset_zone_allowed_hardwall(zone, GFP_KERNEL)) > return; -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxxx For more info on Linux MM, see: http://www.linux-mm.org/ . Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/ Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}