Hey folks,
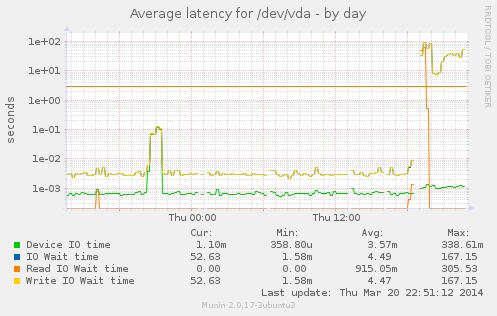
We've been running VM's on qemu using a replicated gluster volume connecting using gfapi and things have been going well for the most part. Something we've noticed though is that we have problems with many concurrent disk operations and disk latency. The latency gets bad enough that the process eats the cpu and the entire machine stalls. The place where we've seen it the worst is a apache2 server under very high load which had to be converted to raw disk image due to performance issues. The hypervisors are connected directly to each other over a bonded pair of 10Gb fiber modules and are the only bricks in the volume. Volume info is
Volume Name: VMARRAY
Type: Replicate
Volume ID: 67b3ad79-4b48-4597-9433-47063f90a7a0
Status: Started
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: 10.9.1.1:/mnt/xfs/VMARRAY
Brick2: 10.9.1.2:/mnt/xfs/VMARRAY
Options Reconfigured:
nfs.disable: on
network.ping-timeout: 7
cluster.eager-lock: on
performance.flush-behind: on
performance.write-behind: on
performance.write-behind-window-size: 4MB
performance.cache-size: 1GB
server.allow-insecure: on
diagnostics.client-log-level: ERROR
Any advice for performance improvements for high IO / low bandwidth tuning would be appreciated.
Thanks,
Josh
Attachment:
vda-day.png
Description: PNG image
_______________________________________________ Gluster-users mailing list Gluster-users@xxxxxxxxxxx http://supercolony.gluster.org/mailman/listinfo/gluster-users

{kind=link}