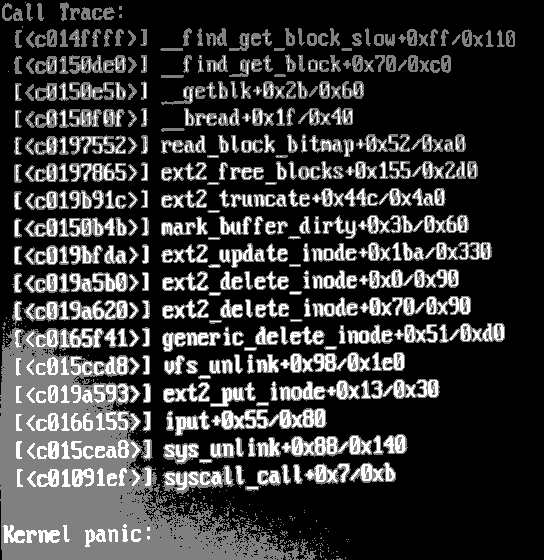
Sean Neakums <sneakums@xxxxxxxx> writes: > Sean Neakums <sneakums@xxxxxxxx> writes: > >> "Theodore Ts'o" <tytso@xxxxxxx> writes: >> >>> On Wed, Oct 29, 2003 at 07:52:23PM +0000, Sean Neakums wrote: >>>> Just now I ran tune2fs -j on the root filesystem of a box running >>>> 2.6.0-test8. Then I edited /etc/fstab and changed the FS type to from >>>> ext2 to ext3, saved the file, and invoked vim on the file again. A >>>> few moments after this, the box hung. Unfortunately X was running at >>>> the time, and so I don't have any messages to cite. >>>> >>>> Is this a known problem? >>> >>> This is the first time anyone has reported anything like this. All >>> tune2fs -j does on a mounted filesystem is to create a normal file >>> (which is used for the journal), mark it immutable, and the modify the >>> superblock to set the has_journal flag and set the journal inode >>> number. None of this should cause a kernel hang. >> >> I was rather taken aback myself. >> >>> What version of e2fsprogs/tune2fs were you using? >> >> tune2fs -V reports "tune2fs 1.35-WIP (21-Aug-2003)" >> >> Obtained from Debian package e2fsprogs version 1.34+1.35-WIP-2003.08.21-3. > > I tried reproducing this on my laptop, which also had an ext2 root and > was also running 2.6.0-test8. I ran the tune2fs -j (same version and > source as above) and updated /etc/fstab as before. Nothing seemed to > be breaking, so I went ahead and built 2.6.0-test9 in my homedir, > which is on a separate volume (/ and /boot are regular partitions; > /home, /usr and /var are lvm2 volumes. The other box has a similar > configuration.). When I ran make modules_install, messages of the > following form began streaming on the console: > > block=X, b_blocknr=X > b_state=0x00000000(?), b_size=1024 > > The Xes are numbers that I couldn't make out due to the messages > streaming so fast. b_blocknr seemed to be changing, although I don't > know if there were repeats. I'm fairly sure but not certain that > b_state was 0x00000000. The filesystem itself has 1024-byte blocks. > > I had a quick grep around, and this message seems to come from > fs/buffer.c:__find_get_block_slow(). I inserted a dump_stack and panic after the printk, removed the journal from the root FS in the usual manner, recreated as above, and triggered this again. Below is the call trace, sans addresses and offsets; the full trace is at http://zork.net/~sneakums/trace.png (44302 byte PNG image). The message that __find_get_block_slow prints was scrolled up by some network-related messages as I took the picture, but b_state was 0x00000000 and b_size 1024. __find_get_block_slow __find_get_block __getblk __bread read_block_bitmap ext2_free_blocks ext2_truncate mark_buffer_dirty ext2_update_inode ext2_delete_inode ext2_delete_inode generic_delete_inode vfs_unlink ext2_put_inode iput sys_unlink syscall_call _______________________________________________ Ext3-users@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/ext3-users
{kind=link}
