So, the short answer to your question is, "Well, not yet, but, er, funny
that you should ask ..."
On Thu, 2006-12-07 at 22:11 +0200, Eftychios Eftychiou wrote:
> Got a few questions regarding RHCS. Would be grateful if someone could
> answer them.
>
> 1. Fencing in a two node cluster according to the FAQ could lead to
> each node trying to fence each other resulting in total cluster
> blowup. The suggested solution of that problem was to use serialized
> fencing devices. From my understanding the above scenario can occur
> because in a two node environment each node has 1 vote so there is no
> way to break the tie. In any case in a total unrelated section it is
> mentioned that a quorum disk can be used to break the tie. Well I am a
> bit confused since in the section it was mentioned that quorum disk
> support was initially removed from RHEL4 but then was added
> optionally. What is the proper way to create a two node cluster ? Is
> quorum disk required if a serialized fence device is used? Will quorum
> disks usage be phased out in the future ? If yes how do you plan to
> address the issues in a 2 node cluster.
>
> 2. I have seen veritas cluster server (VCS) being configured and it
> had the ability to define a dependency graph of the various services
> available. Is such a thing possible on RHCS? Let me be more specific.
Ironically, not... yet. It's a month or two out at the least.
I have basic dependency graph generation and transition-calculation
using a best-first-search in my sandbox, but there are a couple of bugs
I have to fix before I commit it to CVS (and the initial commit will
only be a PoC; it won't be integrated for at least another month or
two).
It allows you to specify:
- require-always: A must be running before B may start, and if A is
restarted, B must restart (note: A moving to the 'failed' state will
cause B to go to the 'stopped' state)
- require-start: A must running before B may start, but if A restarts,
nothing happens to B (e.g. it's smart enough to reconnect). Same about
moving to 'failed' state though.
- colocate-never: when both A and B are running, A must never run on the
same node as B
- colocate-always: when both A and B are running, A must always run on
the same node as B
> 2 node cluster. Only one node is active running all services. 2nd node
> is passive and in case of failure should take over from node 1.
>
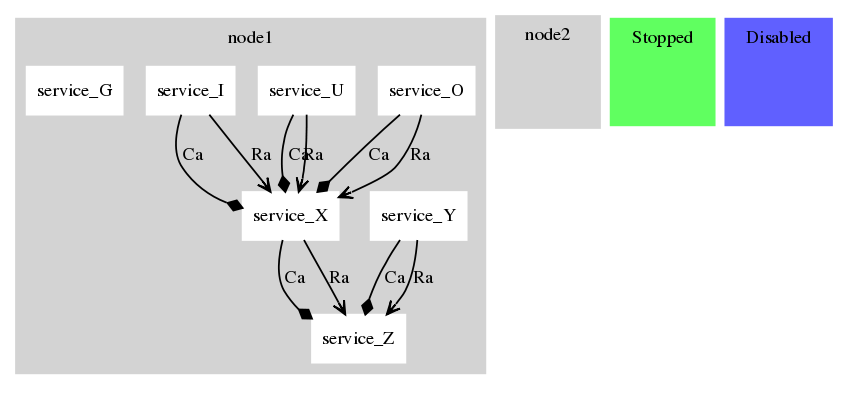
> Application X depends on the existence of network Z
> Application Y also depends on Z
> Application U, I and O depend on X
> Application G depends on nothing directly.
This can mostly be handled now, using 'recover' instead of stop/start
cycles and custom resource agents:
<service name="foo">
<ip ... monitor_link="yes"> <!-- monitors the link for
the service -->
<app_x>
<app_u/>
<app_i/>
<app_o/>
</app_x>
<app_y/>
</ip>
</service>
<service name="bar">
<script name="G" />
</service>
> Is is possible to configure the cluster to behave in the following
> manner
> If U or I or O die restart them
> If X dies the stop all applications and relocate them
You mean U, I, and O, right? G doesn't depend on X.
> if Y dies then restart only Y
> if Z dies Relocate all applications to Node 2
... except G ...
> If G dies restart it
> Of course if there are multiple false restarts all applications should
> be moved to node 2
Nothing for 'false starts' is currently in (as seen in RHCS3). That's
probably a "soon" thing;
> The above applications/components should be started in the following
> order
> Z or G ( G does not depend on anything )
> X or Y
> O, U,I
There are actually several start orders given the dependency set you
described, but yes, that's one of them.
> The actual setup is quite more complicated with multiple dependencies.
> I know it is possible to build dependencies in the service definition
> however I do not see how the above can be accomplished.
Well, if you don't craft special resource agents, then it can't
currently be done. Attached is an example cluster config w/
dependencies. Running it through the test tool:
Start service:G on 1 [1]
Start service:Z on 1 [2]
Start service:Y on 1 [3]
Start service:X on 1 [4]
Start service:O on 1 [5]
Start service:U on 1 [6]
Start service:I on 1 [7]
Application of those operations and running it through graphviz (dot)
yields the attached png as a result.
(come on, you gotta run it through graphviz!)
-- Lon
Attachment:
e.png
Description: PNG image
Attachment:
eftychios.conf
Description: application/xml
Attachment:
signature.asc
Description: This is a digitally signed message part
-- Linux-cluster mailing list Linux-cluster@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/linux-cluster

{kind=link}