Are you using mclock?
I'm not sure. I'll read about it.
What happens if you set it through the Ceph UI?There are global, mon, mgr, osd, mds and client values that I changed to 10 (the default is 1):
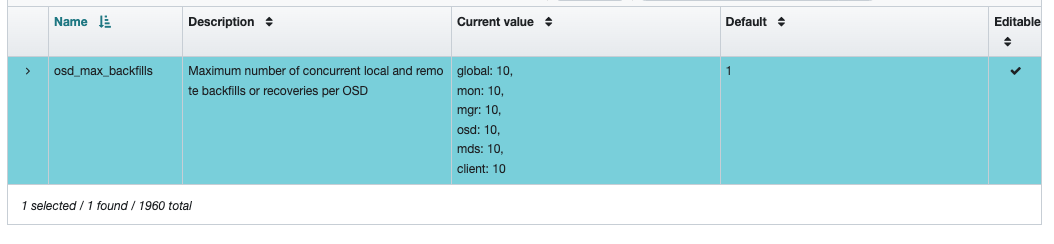
...but the output is still:
# ceph-conf --show-config | egrep osd_max_backfills
osd_max_backfills = 1
osd_max_backfills = 1
You could try turning it off and do the balancing yourself (this might be helpful: https://github.com/laimis9133/plankton-swarm).
I'll definitely look into that. Thanks a bunch!
On Sat, 4 Jan 2025 at 17:06, Laimis Juzeliūnas <laimis.juzeliunas@xxxxxxxxxx> wrote:
Hello Bruno,Interesting case, few observations.What’s the average size of your PGs?Judging from the ceph status you have 1394 pls in total and 696TiB of used storage, that’s roughly 500GB per pg if I’m not mistaken.With the backfilling limits this results in a lot of time spent per single pg due to its size. You could try increasing their number in the pools to have lighter placement groups.Are you using mclock? If yes, you can try setting the profile to prioritise recovery operations with 'ceph config set osd osd_mclock_profile high_recovery_ops'The max backfills configuration is an interesting one - it should persist.What happens if you set it through the Ceph UI?In general it looks like the balancer might be “fighting” with the manual OSD balancing.You could try turning it off and do the balancing yourself (this might be helpful: https://github.com/laimis9133/plankton-swarm).Also probably known already but keep in mind erasure coded pools are known to be on the slower side when it comes to any data movement due to additional operations needed.Best,Laimis J.On 4 Jan 2025, at 13:18, bruno.pessanha@xxxxxxxxx wrote:Hi everyone. I'm still learning how to run Ceph properly in production. I have a a cluster (Reef 18.2.4) with 10 nodes (8 x 15TB nvme's each). There are prod 2 pools, one for RGW (3 x replica) and one for CephFS (EC 8k2m). It was all fine but one users started store more data I started seeing:
1. Very high number of misplaced PG's.
2. OSD's very unbalanced and getting 90% full
```
ceph -s
cluster:
id: 7805xxxe-6ba7-11ef-9cda-0xxxcxxx0
health: HEALTH_WARN
Low space hindering backfill (add storage if this doesn't resolve itself): 195 pgs backfill_toofull
150 pgs not deep-scrubbed in time
150 pgs not scrubbed in time
services:
mon: 5 daemons, quorum host01,host02,host03,host04,host05 (age 7w)
mgr: host01.bwqkna(active, since 7w), standbys: host02.dycdqe
mds: 5/5 daemons up, 6 standby
osd: 80 osds: 80 up (since 7w), 80 in (since 4M); 323 remapped pgs
rgw: 30 daemons active (10 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 11 pools, 1394 pgs
objects: 159.65M objects, 279 TiB
usage: 696 TiB used, 421 TiB / 1.1 PiB avail
pgs: 230137879/647342099 objects misplaced (35.551%)
1033 active+clean
180 active+remapped+backfill_toofull
123 active+remapped+backfill_wait
28 active+clean+scrubbing
15 active+remapped+backfill_wait+backfill_toofull
10 active+clean+scrubbing+deep
5 active+remapped+backfilling
io:
client: 668 MiB/s rd, 11 MiB/s wr, 1.22k op/s rd, 1.15k op/s wr
recovery: 479 MiB/s, 283 objects/s
progress:
Global Recovery Event (5w)
[=====================.......] (remaining: 11d)
```
I've been trying to rebalance the OSD's manually since the balancer does not work due to:
```
"optimize_result": "Too many objects (0.355160 > 0.050000) are misplaced; try again later",
```
I manually re-weighted the top 10 most used OSD's and the number of misplaced objects are going down very slowly. I think it could take many weeks at that ratio.
There's almost 40% of total free space but the RGW pool is almost full at ~94% I think because of OSD's unbalancing.
```
ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
ssd 1.1 PiB 421 TiB 697 TiB 697 TiB 62.34
TOTAL 1.1 PiB 421 TiB 697 TiB 697 TiB 62.34
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 69 MiB 15 207 MiB 0 13 TiB
.nfs 2 32 172 KiB 43 574 KiB 0 13 TiB
.rgw.root 3 32 2.7 KiB 6 88 KiB 0 13 TiB
default.rgw.log 4 32 2.1 MiB 209 7.0 MiB 0 13 TiB
default.rgw.control 5 32 0 B 8 0 B 0 13 TiB
default.rgw.meta 6 32 97 KiB 280 3.5 MiB 0 13 TiB
default.rgw.buckets.index 7 32 16 GiB 2.41k 47 GiB 0.11 13 TiB
default.rgw.buckets.data 10 1024 197 TiB 133.75M 592 TiB 93.69 13 TiB
default.rgw.buckets.non-ec 11 32 78 MiB 1.43M 17 GiB 0.04 13 TiB
cephfs.cephfs01.data 12 144 83 TiB 23.99M 103 TiB 72.18 32 TiB
cephfs.cephfs01.metadata 13 1 952 MiB 483.14k 3.7 GiB 0 10 TiB
```
I also tried changing the following but it does not seem to persist:
```
# ceph-conf --show-config | egrep "osd_recovery_max_active|osd_recovery_op_priority|osd_max_backfills"
osd_max_backfills = 1
osd_recovery_max_active = 0
osd_recovery_max_active_hdd = 3
osd_recovery_max_active_ssd = 10
osd_recovery_op_priority = 3
# ceph config set osd osd_max_backfills 10
# ceph-conf --show-config | egrep "osd_recovery_max_active|osd_recovery_op_priority|osd_max_backfills"
osd_max_backfills = 1
osd_recovery_max_active = 0
osd_recovery_max_active_hdd = 3
osd_recovery_max_active_ssd = 10
osd_recovery_op_priority = 3
```
1. Why I ended up with so many misplaced PG's since there were no changes on the cluster: number of osd's, hosts, etc.
2. Is it ok to change the target_max_misplaced_ratio to something higher than .05 so the autobalancer would work and I wouldn't have to constantly rebalance the osd's manually?
3. Is there a way to speed up the rebalance?
4. Any other recommendation that could help to make my cluster healthy again?
Thank you!
Bruno
_______________________________________________
ceph-users mailing list -- ceph-users@xxxxxxx
To unsubscribe send an email to ceph-users-leave@xxxxxxx
Bruno Gomes Pessanha
_______________________________________________ ceph-users mailing list -- ceph-users@xxxxxxx To unsubscribe send an email to ceph-users-leave@xxxxxxx
