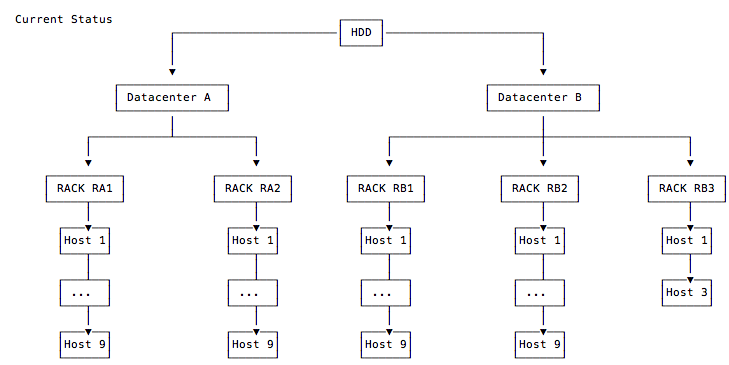
Hi all, In our current production cluster we have the following CRUSH hierarchy, see https://pastebin.com/640Q4XSH or the attached image. This reflects 1:1 real physical deployment. We currently use also a replica factor of 3 with the following CRUSH rule on our pools: rule hdd_replicated { id 0 type replicated min_size 1 max_size 10 step take hdd step chooseleaf firstn 0 type rack step emit } I can imagine with such design it's hard to achieve a good data distribution. Right? Moreover, we are currently getting a lot of "near full" warnings for several OSDs and had one full OSD, but the cluster has more than 400 TB free space available from a total cluster size of 1,2 PB. So what could we consider: 1) Changing the crush rule above in away to achieve better data distribution? 2) Adding a third "dummy" datacenter with 2 "dummy" racks and distribute the hosts evenly across all datacenters? Then use a crush rule with "step chooseleaf firstn 0 type datacenter". 3) Adding a third "dummy" datacenter each with on Rack and then distribute the hosts evenly across? Then use a crush rule with "step chooseleaf firstn 0 type datacenter". 4) Other suggestions? We a currently running on Luminous 12.2.4. Thanks for any feedback... Best, Martin
Attachment:
ceph_cursh_hierarchy.png
Description: PNG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}