Hello!
I recently installed
INTEL SSD 400GB 750 SERIES PCIE 3.0 X4 in 3 of my OSD nodes.
I
primarily use my ceph as a beckend for OpenStack nova, glance, swift
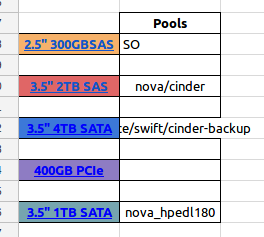
and cinder. My crushmap is configured to have rulesets for SAS disks,
SATA disks and another ruleset that resides in HPE nodes using SATA
disks too.
Scenario:
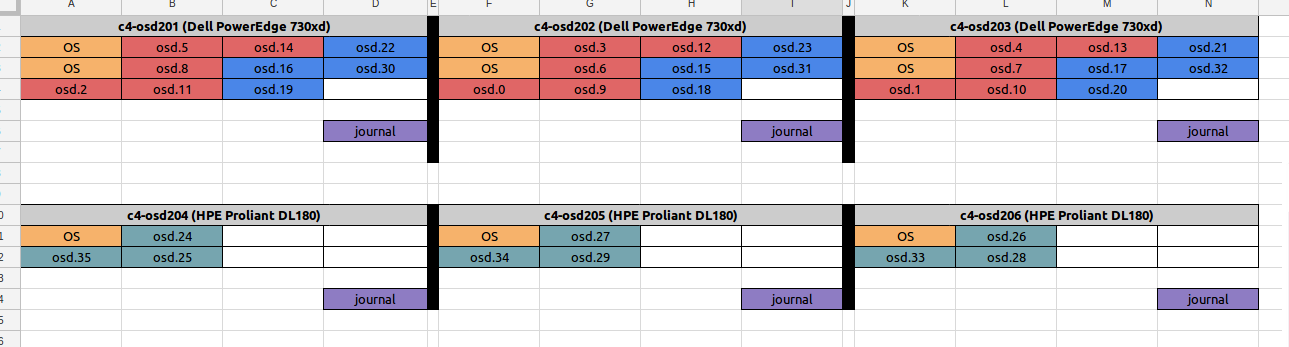
- Using pools to store instance disks for OpenStack
- Pool nova in "ruleset SAS" placed on c4-osd201, c4-osd202 and c4-osd203 with 5 osds per hosts
- Pool nova_hpedl180 in "ruleset NOVA_HPEDL180" placed on c4-osd204, c4-osd205, c4-osd206 with 3 osds per hosts
- Every OSD has one partition of 35GB in a INTEL SSD 400GB 750 SERIES PCIE 3.0 X4
- Internal link for cluster and public network of 10Gbps
- Deployment via ceph-ansible. Same configuration define in ansible for every host on cluster
Instance on pool nova in ruleset SAS:
# dd if=/dev/zero of=/mnt/bench bs=1G count=1 oflag=direct
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.56255 s, 419 MB/s
Instance on pool nova in ruleset NOVA_HPEDL180:
# dd if=/dev/zero of=/mnt/bench bs=1G count=1 oflag=direct
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 11.8243 s, 90.8 MB/s
Any clue about what is missing or what is happening?
Thanks in advance._______________________________________________
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com