Hi Wido, I came across this ancient ML entry with no responses and wanted to follow up with you to see if you recalled any solution to this. Copying the ceph-users list to preserve any replies that may result for archival. I have a couple of boxes with 10x Micron 5100 SATA SSD’s, journaled on Micron 9100 NVMe SSD’s; ceph 10.2.7; Ubuntu 16.04 4.8 kernel. I have noticed now twice that I’ve had SSD’s flapping due to the fstrim eating up the io 100%. It eventually righted itself after a little less than 8 hours. Noout flag was set, so it didn’t create any unnecessary rebalance or whatnot. Timeline showing that only 1 OSD ever went down at a time, but they seemed to go down in a rolling fashion during the fstrim session. You can actually see in the OSD graph all 10 OSD’s on this node go down 1 by 1 over time. 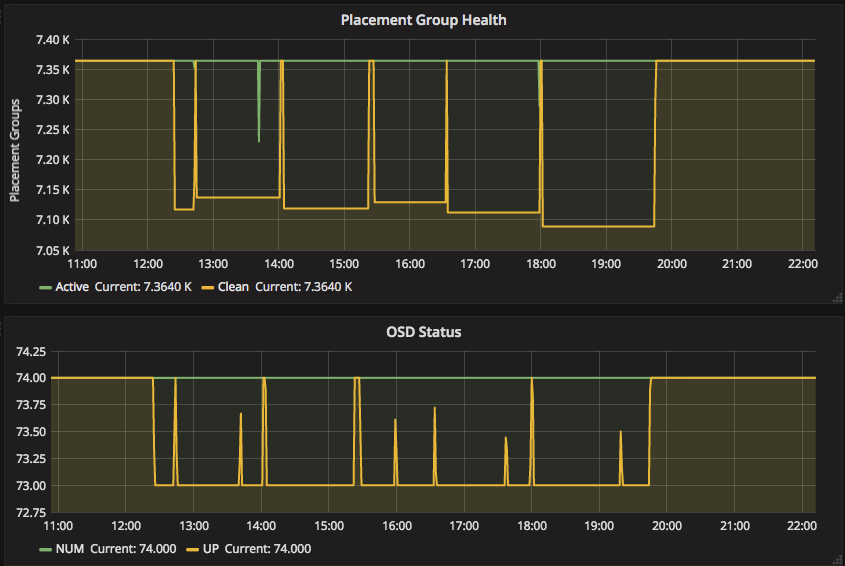 And the OSD’s were going down because of: 2017-07-02 13:47:32.618752 7ff612721700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7ff5ecd0c700' had timed out after 15
I am curious if you were able to nice it or something similar to mitigate this issue? Oddly, I have similar machines with Samsung SM863a’s with Intel P3700 journals that do not appear to be affected by the fstrim load issue despite identical weekly cron jobs enabled. Only the Micron drives (newer) have had these issues. Appreciate any pointers, Reed Wido den Hollander wido at 42on.com Hi, Last sunday I got a call early in the morning that a Ceph cluster was having some issues. Slow requests and OSDs marking each other down. Since this is a 100% SSD cluster I was a bit confused and started investigating. It took me about 15 minutes to see that fstrim was running and was utilizing the SSDs 100%. On Ubuntu 14.04 there is a weekly CRON which executes fstrim-all. It detects all mountpoints which can be trimmed and starts to trim those. On the Intel SSDs used here it caused them to become 100% busy for a couple of minutes. That was enough for them to no longer respond on heartbeats, thus timing out and being marked down. Luckily we had the "out interval" set to 1800 seconds on that cluster, so no OSD was marked as "out". fstrim-all does not execute fstrim with a ionice priority. From what I understand, but haven't tested yet, is that running fstrim with ionice -c Idle should solve this. It's weird that this issue didn't come up earlier on that cluster, but after killing fstrim all problems we resolved and the cluster ran happily again. So watch out for fstrim on early Sunday mornings on Ubuntu! -- Wido den Hollander 42on B.V. Ceph trainer and consultant |
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
