|
Hi Florian, Wido, That's interesting. I ran some bluestore benchmarks a few weeks ago on Luminous dev (1st release) and came to the same (early) conclusion regarding the performance drop with many small objects on bluestore, whatever the number of PGs is on a pool. Here is the graph I generated from the results: 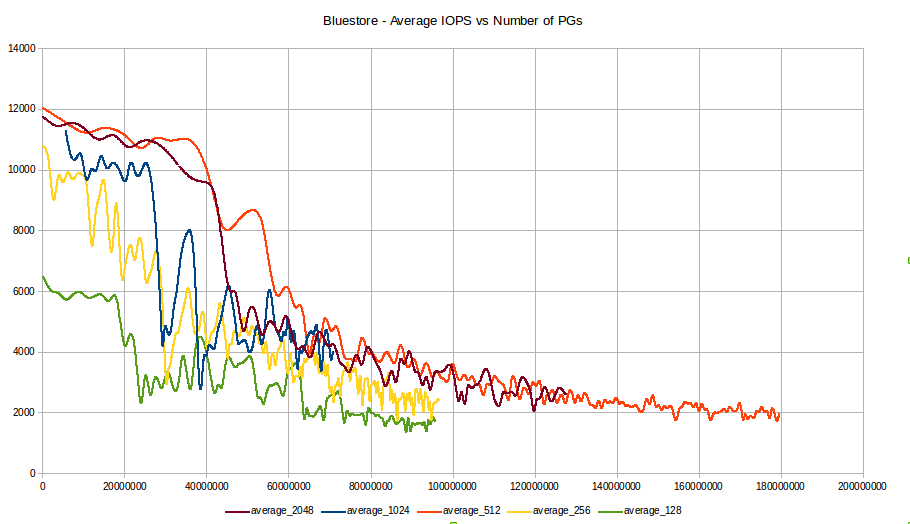 The test was run on a 36 OSDs cluster (3x R730xd with 12x 4TB SAS drives) with rocksdb and WAL on same SAS drives. Test consisted of multiple runs of the following command on a size 1 pool : rados bench -p pool-test-mom02h06-2 120 write -b 4K -t 128 --no-cleanup I hope this will improve as the performance drop seems more related to how many objects are in the pool (> 40M) rather than how many objects are written each second. Like Wido, I was thinking that we may have to increase the number of disks in the future to keep up with the needed performance for our Zimbra messaging use case. Or move datas from current EC pool to a replicated pool, as erasure coding doesn't help either for this type of use cases. Regards, Frédéric. Le 26/04/2017 à 22:25, Wido den
Hollander a écrit :
Op 24 april 2017 om 19:52 schreef Florian Haas <florian@xxxxxxxxxxx>: Hi everyone, so this will be a long email — it's a summary of several off-list conversations I've had over the last couple of weeks, but the TL;DR version is this question: How can a Ceph cluster maintain near-constant performance characteristics while supporting a steady intake of a large number of small objects? This is probably a very common problem, but we have a bit of a dearth of truly adequate best practices for it. To clarify, what I'm talking about is an intake on the order of millions per hour. That might sound like a lot, but if you consider an intake of 700 objects/s at 20 KiB/object, that's just 14 MB/s. That's not exactly hammering your cluster — but it amounts to 2.5 million objects created per hour.I have seen that the amount of objects at some point becomes a problem. Eventually you will have scrubs running and especially a deep-scrub will cause issues. I have never had the use-case to have a sustained intake of so many objects/hour, but it is interesting though.Under those circumstances, two things tend to happen: (1) There's a predictable decline in insert bandwidth. In other words, a cluster that may allow inserts at a rate of 2.5M/hr rapidly goes down to 1.8M/hr and then 1.7M/hr ... and by "rapidly" I mean hours, not days. As I understand it, this is mainly due to the FileStore's propensity to index whole directories with a readdir() call which is an linear-time operation. (2) FileStore's mitigation strategy for this is to proactively split directories so they never get so large as for readdir() to become a significant bottleneck. That's fine, but in a cluster with a steadily growing number of objects, that tends to lead to lots and lots of directory splits happening simultanously — causing inserts to slow to a crawl. For (2) there is a workaround: we can initialize a pool with an expected number of objects, set a pool max_objects quota, and disable on-demand splitting altogether by setting a negative filestore merge threshold. That way, all splitting occurs at pool creation time, and before another split were to happen, you hit the pool quota. So you never hit that brick wall causes by the thundering herd of directory splits. Of course, it also means that when you want to insert yet more objects, you need another pool — but you can handle that at the application level. It's actually a bit of a dilemma: we want directory splits to happen proactively, so that readdir() doesn't slow things down, but then we also *don't* want them to happen, because while they do, inserts flatline. (2) will likely be killed off completely by BlueStore, because there are no more directories, hence nothing to split. For (1) there really isn't a workaround that I'm aware of for FileStore. And at least preliminary testing shows that BlueStore clusters suffer from similar, if not the same, performance degradation (although, to be fair, I haven't yet seen tests under the above parameters with rocksdb and WAL on NVMe hardware).Can you point me to this testing of BlueStore?For (1) however I understand that there would be a potential solution in FileStore itself, by throwing away Ceph's own directory indexing and just rely on flat directory lookups — which should be logarithmic-time operations in both btrfs and XFS, as both use B-trees for directory indexing. But I understand that that would be a fairly massive operation that looks even less attractive to undertake with BlueStore around the corner. One suggestion that has been made (credit to Greg) was to do object packing, i.e. bunch up a lot of discrete data chunks into a single RADOS object. But in terms of distribution and lookup logic that would have to be built on top, that seems weird to me (CRUSH on top of CRUSH to find out which RADOS object a chunk belongs to, or some such?) So I'm hoping for the likes of Wido and Dan and Mark to have some alternate suggestions here: what's your take on this? Do you have suggestions for people with a constant intake of small objects?I have a bit of similar use-case. A customer needs to store a lot of objects (4M per TB) and we eventually went for a lot of smal(ler) disks instead of big disks. In this case we picked 3TB disks instead of 6 or 8TB so that we have a large number of OSDs, high number of PGs and thus have less objects per OSD. You are ingesting ~50GB/h. For how long are you keeping the objects in the cluster? What is the total TB storage you need? Would it work in this use-case to have a lot of OSDs on smaller disks? I think that in this you can partly overcome the problem by simply having more OSDs. WidoLooking forward to hearing your thoughts. Cheers, Florian _______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com |
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
