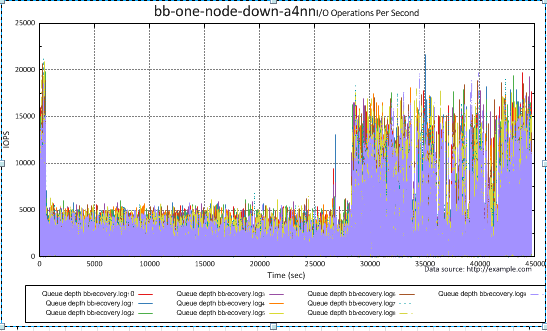
Yes Mark, I have the following io profile going on during recovery. [recover-test] ioengine=rbd clientname=admin pool=mypool rbdname=<> direct=1 invalidate=0 rw=randrw norandommap randrepeat=0 rwmixread=40 rwmixwrite=60 iodepth=256 numjobs=6 end_fsync=0 bssplit=512/4:1024/1:1536/1:2048/1:2560/1:3072/1:3584/1:4k/67:8k/10:16k/7:32k/3:64k/3 group_reporting=1 time_based runtime=24h There is a degradation on the client io but unfortunately I didn't quantify that for all the cases. Will do that next time. I have one for scenario 2 though (attached here). Thanks & Regards Somnath -----Original Message----- From: Mark Nelson [mailto:mnelson@xxxxxxxxxx] Sent: Wednesday, May 11, 2016 5:16 AM To: Somnath Roy; Nick Fisk; Ben England; Kyle Bader Cc: Sage Weil; Samuel Just; ceph-users@xxxxxxxxxxxxxx Subject: Re: Weighted Priority Queue testing > 1. First scenario, only 4 node scenario and since it is chassis level > replication single node remaining on the chassis taking all the traffic. > It seems that is a bottleneck as for the host level replication on the > similar setup recovery time is much less (data is not in this table). > > > > 2. In the second scenario , I kept everything else same but doubled > the node/chassis. Recovery time is also half. > > > > 3. For the third scenario, increased cluster data and also now I have > doubled the number of OSDs in the cluster (since each drive size is > 4TB now). Recovery time came down further. > > > > 4. Moved to Jewel keeping everything else same, got further improvement. > Mostly because of improved write performance in jewel (?). > > > > 5. Last scenario is interesting. I got improved recovery speed than > any other scenario with this WPQ. Degraded PG % came down to 2% within > 3 hours , ~0.6% within 4 hours and 15 min , but *last 0.6% took ~4 > hours* hurting overall time for recovery. > > 6. In fact, this long tail latency is hurting the overall recovery > time for every other scenarios. Related tracker I found is > http://tracker.ceph.com/issues/15763 > > > > Any feedback much appreciated. We can discuss this in tomorrow’s > performance call if needed. Hi Somnath, Thanks for these! Interesting results. Did you have a client load going at the same time as recovery? It would be interesting to know how client IO performance was affected in each case. Too bad about the long tail on WPQ. I wonder if the long tail is consistently higher with WPQ or it just happened to be higher in that test. Anyway, thanks for the results! Glad to see the recovery time in general is lower in hammer. Mark PLEASE NOTE: The information contained in this electronic mail message is intended only for the use of the designated recipient(s) named above. If the reader of this message is not the intended recipient, you are hereby notified that you have received this message in error and that any review, dissemination, distribution, or copying of this message is strictly prohibited. If you have received this communication in error, please notify the sender by telephone or e-mail (as shown above) immediately and destroy any and all copies of this message in your possession (whether hard copies or electronically stored copies).
Attachment:
bb_one_node_down.png
Description: bb_one_node_down.png
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}