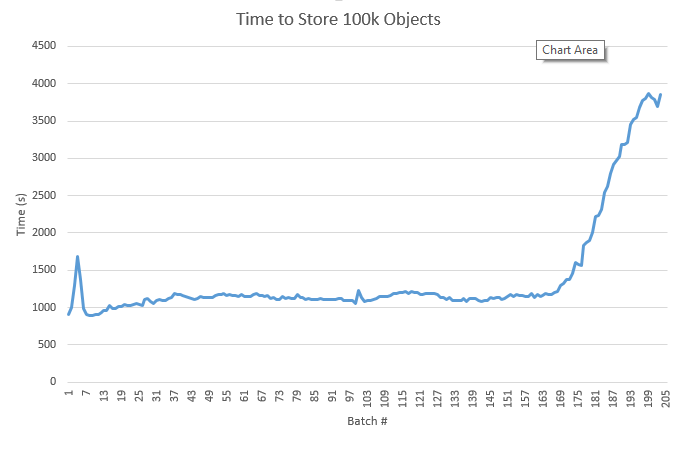
I've been testing the performance of ceph by storing objects through RGW. This is on Debian with Hammer using 40 magnetic OSDs, 5 mons, and 4 RGW instances. Initially the storage time was holding reasonably steady, but it has started to rise recently as shown in the attached chart.
The test repeatedly saves 100k objects of 55 kB size using multiple threads (50) against multiple RGW gateways (4). It uses a sequential identifier as the object key and shards the bucket name using id % 100. The buckets have index sharding enabled with 64 index shards per bucket.
ceph status doesn't appear to show any issues. Is there something I should be looking at here?
# ceph status
cluster 3fc86d01-cf9c-4bed-b130-7a53d7997964
health HEALTH_OK
monmap e2: 5 mons at
{condor=192.168.188.90:6789/0,duck=192.168.188.140:6789/0,eagle=192.168.188.100:6789/0,falcon=192.168.188.110:6789/0,shark=192.168.188.118:6789/0}
election epoch 18, quorum 0,1,2,3,4
condor,eagle,falcon,shark,duck
osdmap e674: 40 osds: 40 up, 40 in
pgmap v258756: 3128 pgs, 10 pools, 1392 GB data, 27282 kobjects
4784 GB used, 69499 GB / 74284 GB avail
3128 active+clean
client io 268 kB/s rd, 1100 kB/s wr, 493 op/s
Kris Jurka
Attachment:
StorageTime.png
Description: PNG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}