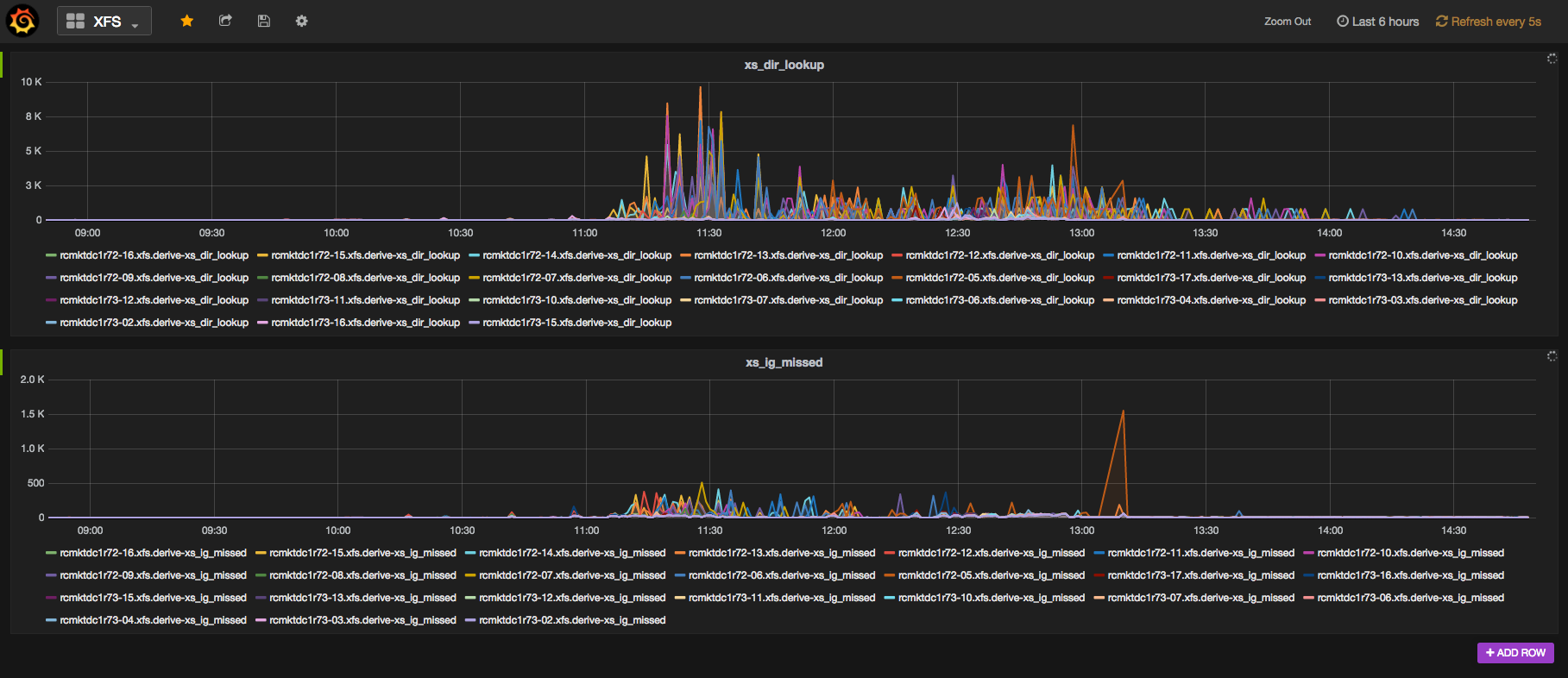
Based on everyones suggestions; The first modification to 50 / 16 enabled our config to get to ~645Mill objects before the behavior in question was observed (~330 was the previous ceiling). Subsequent modification to 50 / 24 has enabled us to get to 1.1 Billion+ Thank you all very much for your support and assistance. Best Regards, Wade On Mon, Jun 20, 2016 at 6:58 PM, Christian Balzer <chibi@xxxxxxx> wrote: > > Hello, > > On Mon, 20 Jun 2016 20:47:32 +0000 Warren Wang - ISD wrote: > >> Sorry, late to the party here. I agree, up the merge and split >> thresholds. We're as high as 50/12. I chimed in on an RH ticket here. >> One of those things you just have to find out as an operator since it's >> not well documented :( >> >> https://bugzilla.redhat.com/show_bug.cgi?id=1219974 >> >> We have over 200 million objects in this cluster, and it's still doing >> over 15000 write IOPS all day long with 302 spinning drives + SATA SSD >> journals. Having enough memory and dropping your vfs_cache_pressure >> should also help. >> > Indeed. > > Since it was asked in that bug report and also my first suspicion, it > would probably be good time to clarify that it isn't the splits that cause > the performance degradation, but the resulting inflation of dir entries > and exhaustion of SLAB and thus having to go to disk for things that > normally would be in memory. > > Looking at Blair's graph from yesterday pretty much makes that clear, a > purely split caused degradation should have relented much quicker. > > >> Keep in mind that if you change the values, it won't take effect >> immediately. It only merges them back if the directory is under the >> calculated threshold and a write occurs (maybe a read, I forget). >> > If it's a read a plain scrub might do the trick. > > Christian >> Warren >> >> >> From: ceph-users >> <ceph-users-bounces@xxxxxxxxxxxxxx<mailto:ceph-users-bounces@xxxxxxxxxxxxxx>> >> on behalf of Wade Holler >> <wade.holler@xxxxxxxxx<mailto:wade.holler@xxxxxxxxx>> Date: Monday, June >> 20, 2016 at 2:48 PM To: Blair Bethwaite >> <blair.bethwaite@xxxxxxxxx<mailto:blair.bethwaite@xxxxxxxxx>>, Wido den >> Hollander <wido@xxxxxxxx<mailto:wido@xxxxxxxx>> Cc: Ceph Development >> <ceph-devel@xxxxxxxxxxxxxxx<mailto:ceph-devel@xxxxxxxxxxxxxxx>>, >> "ceph-users@xxxxxxxxxxxxxx<mailto:ceph-users@xxxxxxxxxxxxxx>" >> <ceph-users@xxxxxxxxxxxxxx<mailto:ceph-users@xxxxxxxxxxxxxx>> Subject: >> Re: [ceph-users] Dramatic performance drop at certain number of objects >> in pool >> >> Thanks everyone for your replies. I sincerely appreciate it. We are >> testing with different pg_num and filestore_split_multiple settings. >> Early indications are .... well not great. Regardless it is nice to >> understand the symptoms better so we try to design around it. >> >> Best Regards, >> Wade >> >> >> On Mon, Jun 20, 2016 at 2:32 AM Blair Bethwaite >> <blair.bethwaite@xxxxxxxxx<mailto:blair.bethwaite@xxxxxxxxx>> wrote: On >> 20 June 2016 at 09:21, Blair Bethwaite >> <blair.bethwaite@xxxxxxxxx<mailto:blair.bethwaite@xxxxxxxxx>> wrote: >> > slow request issues). If you watch your xfs stats you'll likely get >> > further confirmation. In my experience xs_dir_lookups balloons (which >> > means directory lookups are missing cache and going to disk). >> >> Murphy's a bitch. Today we upgraded a cluster to latest Hammer in >> preparation for Jewel/RHCS2. Turns out when we last hit this very >> problem we had only ephemerally set the new filestore merge/split >> values - oops. Here's what started happening when we upgraded and >> restarted a bunch of OSDs: >> https://au-east.erc.monash.edu.au/swift/v1/public/grafana-ceph-xs_dir_lookup.png >> >> Seemed to cause lots of slow requests :-/. We corrected it about >> 12:30, then still took a while to settle. >> >> -- >> Cheers, >> ~Blairo >> >> This email and any files transmitted with it are confidential and >> intended solely for the individual or entity to whom they are addressed. >> If you have received this email in error destroy it immediately. *** >> Walmart Confidential *** > > > -- > Christian Balzer Network/Systems Engineer > chibi@xxxxxxx Global OnLine Japan/Rakuten Communications > http://www.gol.com/ -- To unsubscribe from this list: send the line "unsubscribe ceph-devel" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
