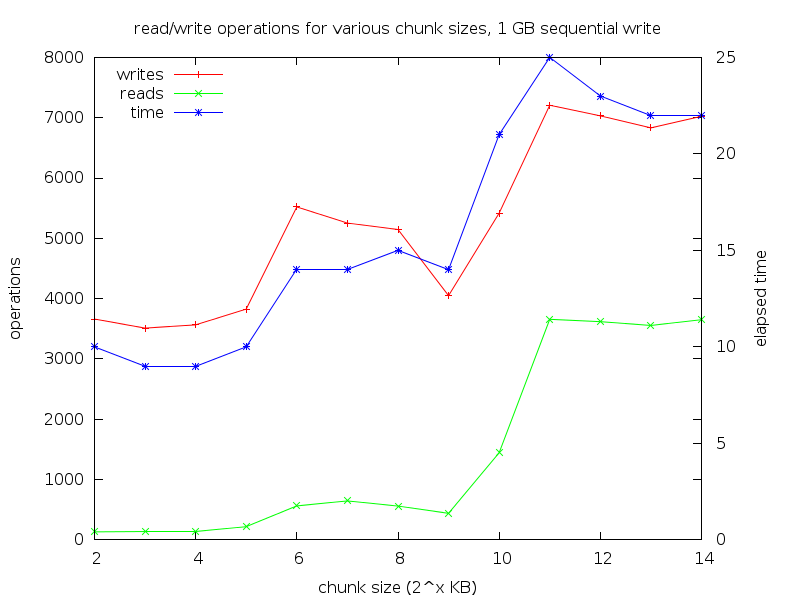
Hi, I'm getting poorer performance for large sequential writes than I expected with a 3-drive RAID 5--each drive writes at about half of the speed it is capable of. When I monitor the I/O with dstat or iostat, I see a high number of read operations for each drive, and I suspect that is related to the low performance, since presumably the drives are having to seek in order to perform these reads. I'm aware of the RAID 5 write penalty, but does it still apply to large sequential writes that traverse many stripes? If the kernel is overwriting an entire stripe, can't it just overwrite the parity chunk without having to read anything beforehand? I tried to find out if the kernel actually does this, but my searches came up short. Perhaps my assumption is naive. I know this doesn't have anything to do with the filesystem--I was able to reproduce the behavior on a test system, writing directly to an otherwise unused array, using a single 768 MB write() call (verified by strace). I wrote a script to benchmark the number of read/write operations along with the elapsed time for writing. The methodology is basically: 1. create array 2. read 768 MB to a buffer 3. wait for array to finish resyncing 4. sync; drop buffers/caches 5. read stats from /proc/diskstats 6. write buffer to array 7. sync 8. read stats from /proc/diskstats 9. analyze data: - for each component device, subtract initial stats from final stats - sum up the stats from all the devices That last step is probably invalid for the fields in /proc/diskstats that are not counters, but I wasn't interested in them. I measured chunk sizes at each power of 2 from 2^2 to 2^14 KB. The results of this are that smaller chunks performed the best, with generally lower performance for larger ones, corresponding to more read and write operations. http://www.fatooh.org/files/tmp/chunks/output1.png Note that the blue line (time) has the Y axis on the right. Does this behavior seem expected? Am I doing something wrong, or is there something I can tune? I'd like to be able to understand this better, but I don't have enough background. Full results, scripts, and raw data are available here: http://www.fatooh.org/files/tmp/chunks/ The CSV fields are: - chunk size - time to write 768 MB - the fields calculated from /proc/diskstat in step #9 above Test system stats: 2 GB RAM Athlon64 3400+ Debian Sid, 64-bit Linux 3.8-2-amd64 (Debian kernel) mdadm v3.2.5 3 disk raid 5 of 1 GB partitions on separate disks (small RAID size for testing to keep the resync time down) Thanks for any help, Corey -- To unsubscribe from this list: send the line "unsubscribe linux-raid" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
