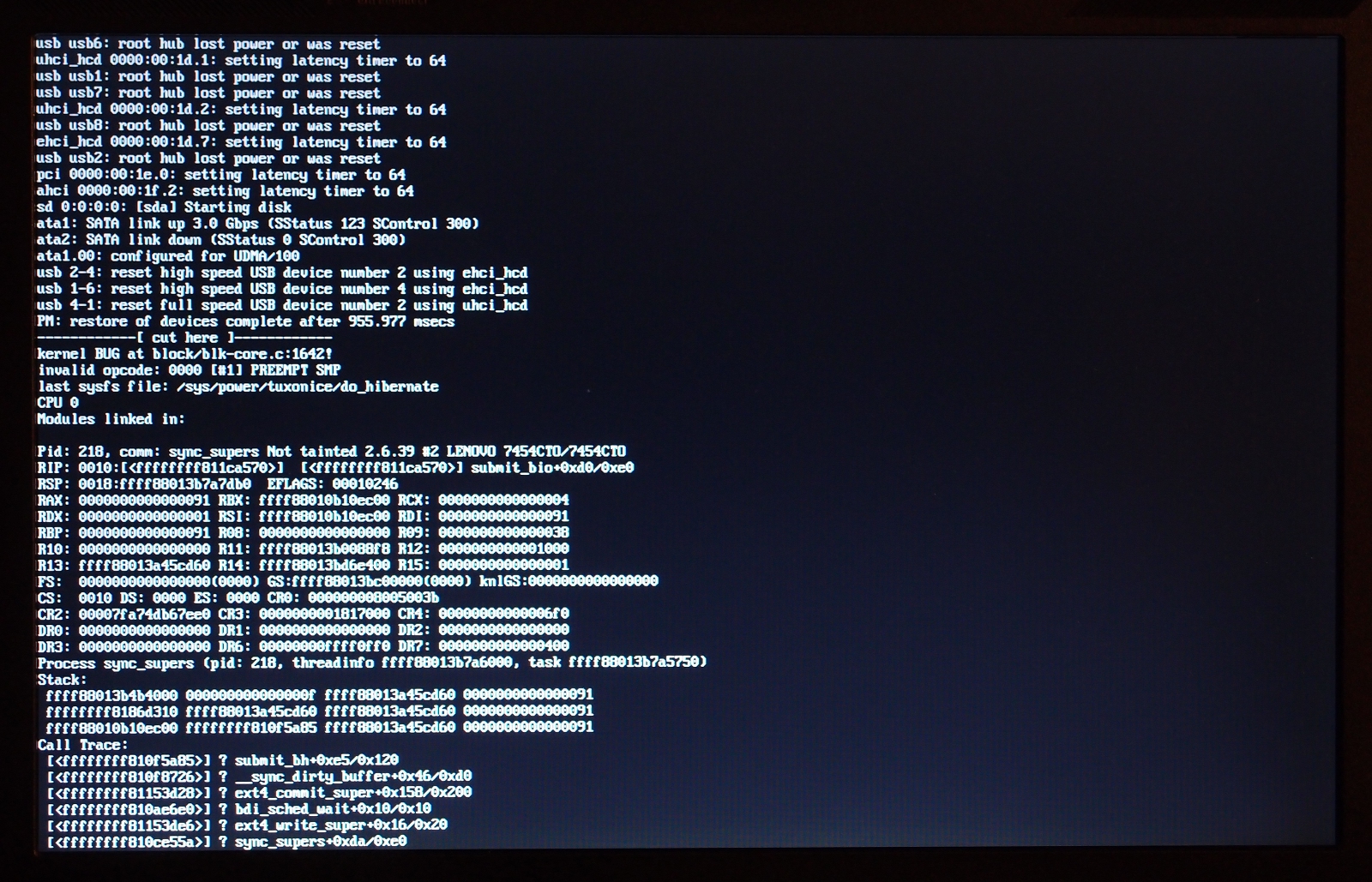
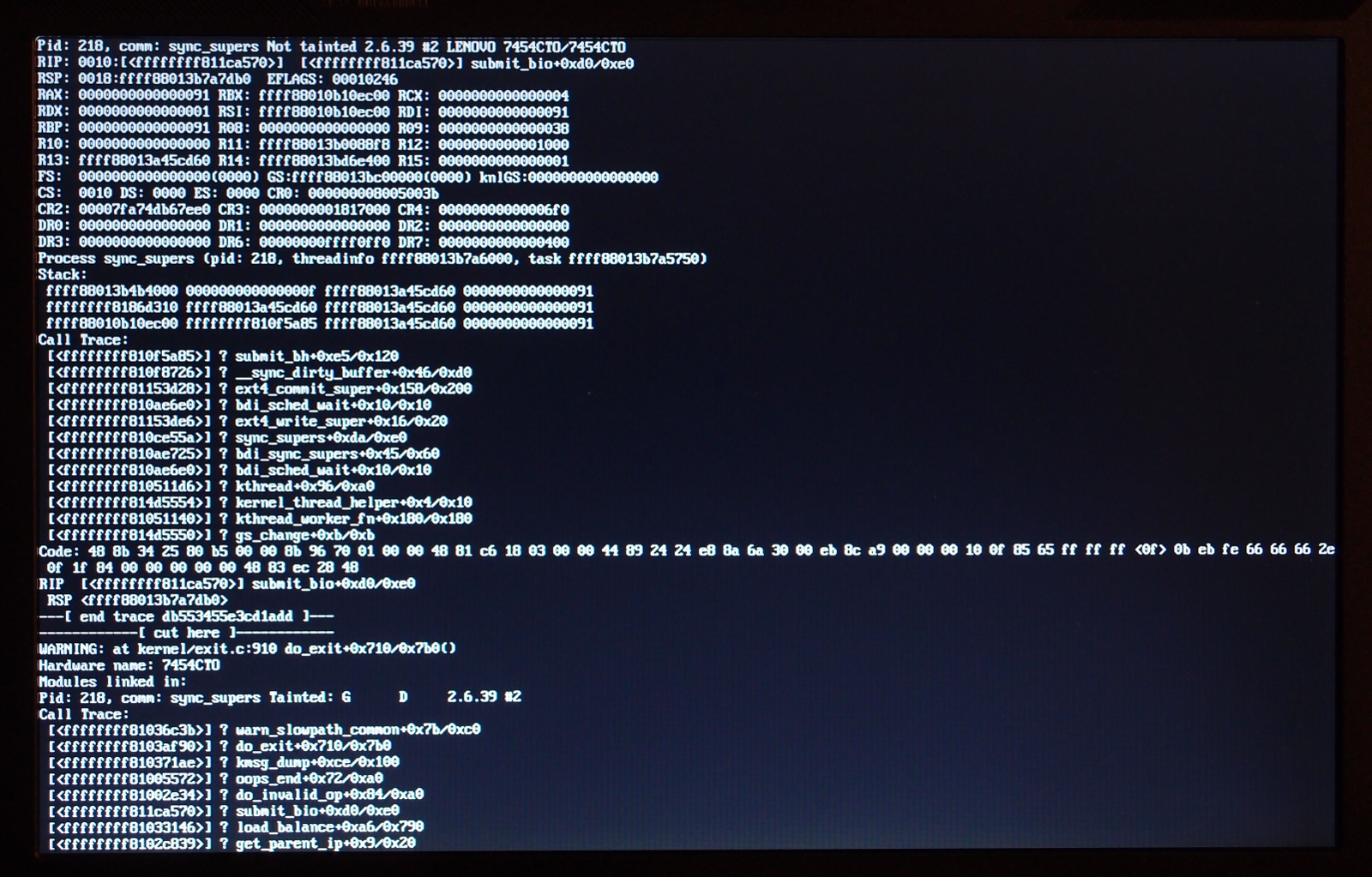
On 6 Sep 2011, Vitaly Minko spake thusly: > Matt Graham <danceswithcrows <at> gmail.com> writes: > >> Vitaly, could you get a picture of the OOPS you get? > > For 2.6.39: > http://vminko.org/storage/toi_oops/photo0.jpg > http://vminko.org/storage/toi_oops/photo1.jpg That's a different oops from the one I started seeing in 2.6.39. (I use md1 for every filesystem, but not for swap.) I see an oops-panic-and-reboot with this backtrace right before what would normally be the post-hibernation powerdown, plainly an attempt to submit a bio for an md superblock write after the blockdev has been frozen: panic+0x0a/0x1a6 oops_end+0x86/0x93 die+0x5a/0x66 do_trap+0x121/0x130 do_invalid_op+0x96/0x9f ? submit_bio+0x33/0xf8 invalid_op+0x15/0x20 ? submit_bio+0x33/0xf8 md_super_write+0x85/0x94 md_update_sb+0x253/0x2f4 __md_stop_writes+0x73/0x77 md_set_readonly+0x7a/0xcc md_notify_reboot+0x64/0xce notifier_call_chain+0x37/0x63 __blocking_notifier_call_chain+0x4b/0x60 blocking_notifier_call_chain+0x14/0x16 kernel_shutdown_prepare+0x2b/0x3f kernel_power_off+0x13/0x4a __toi_power_down+0xef/0x133 ? memory_bm_next_pfn+0x10/0x12 do_toi_step+0x608/0x700 toi_try_hibernate+0x108/0x145 toi_main_wrapper+0xe/0x10 toi_attr_store+0x203/0x256 sysfs_write_file+0xf4/0x130 vfs_write+0xb5/0x151 sys_write+0x4a/0x71 system_call_fastpath+0x16/0x1b The cause is plainly this, in md_set_readonly(): if (!mddev->in_sync || mddev->flags) { /* mark array as shutdown cleanly */ mddev->in_sync = 1; md_update_sb(mddev, 1); } which you juwt can't do once the blockdev has been frozen. -- not that I'm terribly clear on what we *should* do: mark the array as shut down at the same moment as we suspend the first of the blockdevs that makes it up, perhaps? Neil will know, he knows everything. >> I guess it won't >> have md_super_write anywhere, but it'd be interesting to see where the >> common elements are. > > Actually the call trace is completely different. Not mine. We may have two different bugs. But as with yours, the oops above started in the 2.6.39.x era. -- NULL && (void) -- To unsubscribe from this list: send the line "unsubscribe linux-raid" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
{kind=link}
