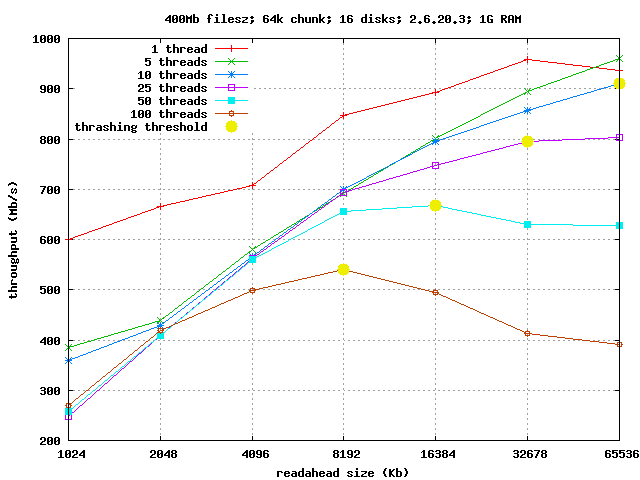
On Sunday 22 April 2007 13:42:43 Justin Piszcz wrote: > http://www.rhic.bnl.gov/hepix/talks/041019pm/schoen.pdf > Check page 13 of 20. Thanks, interesting presentation. I'm working in the same area now, big media files and many clients. I spent some days to build a low-cost, high performance server. With my experience, I think, some results of this presentation can't be applied to recent kernels. It's off-topic in this thread, sorry, but I like to swagger what can be done with Linux! :) ASUS P5B-E Plus, P4 641, 1024Mb RAM, 6 disks on 965P's south bridge, 1 disk on Jmicron (both driven by AHCI driver), 1 disk on Silicon Image 3132, 8 disks on HPT2320 (hpt's driver). 16x Seagate 500Gb 16Mb cache. kernel 2.6.20.3 anticipatory scheduler chunk size 64Kb XFS file system file size is 400Mb, I read 200 of them in each test The yellow points are marking thrashing thresholds, I computed it based on process number and RAM size. It's not an exact threshold. - now see the attached picture :) Awesome performance, near disk-platter speed with big RA! It's even better with ~+15% if I use the -mm tree with the new adaptive readahead! Bigger files, bigger chunk also helps, but in my case, it's constant (unfortunately). The rule of readahead size is simple: the much is better, till no thrashing. -- d
Attachment:
r1.png
Description: PNG image

{kind=link}