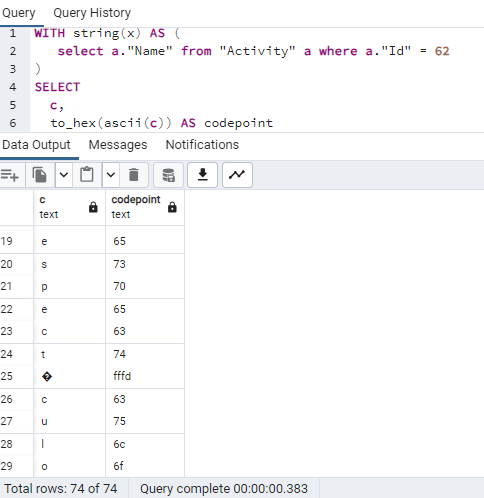
this is the result I got, now I have to figure it out how to solve it, thank you so much El mar, 12 dic 2023 a las 14:42, Daniel Verite (<daniel@xxxxxxxxxxxxxxxx>) escribió: > > Igniris Valdivia Baez wrote: > > > hello, thank you for answering, it's not a typo, in the attachments > > you can see that this is actually my collation, algo a pic of the > > problem for more clarification, > > This character is meant to replace undisplayable characters: > > From https://en.wikipedia.org/wiki/Specials_(Unicode_block): > > U+FFFD � REPLACEMENT CHARACTER used to replace an unknown, > unrecognised, or unrepresentable character > > It would useful to know whether: > > - this code point U+FFFD is in the database contents in places > where accented characters should be. In this case the SQL client is > just faithfully displaying it and the problem is not on its side. > > - or whether the database contains the accented characters normally > encoded in UTF8. In this case there's a configuration mismatch on the > SQL client side when reading. > > To break down a string into code points to examine it, a query like > the following can be used, where you replace SELECT 'somefield' > with a query that selects a suspicious string from your actual table: > > WITH string(x) AS ( > SELECT 'somefield' > ) > SELECT > c, > to_hex(ascii(c)) AS codepoint > FROM > string CROSS JOIN LATERAL regexp_split_to_table(x, '') AS c > ; > > > Best regards, > -- > Daniel Vérité > https://postgresql.verite.pro/ > Twitter: @DanielVerite
Attachment:
image.png
Description: PNG image

{kind=link}