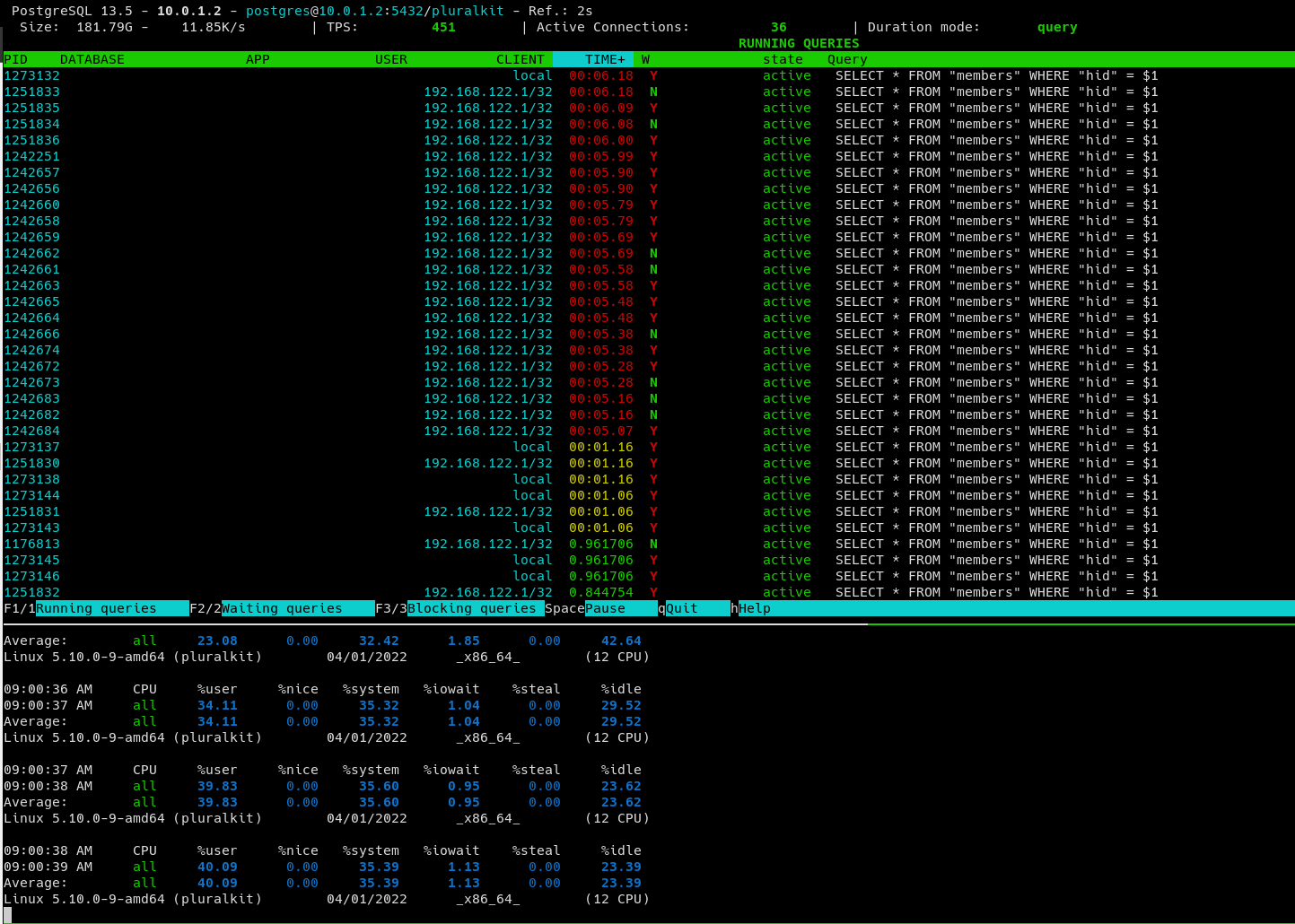
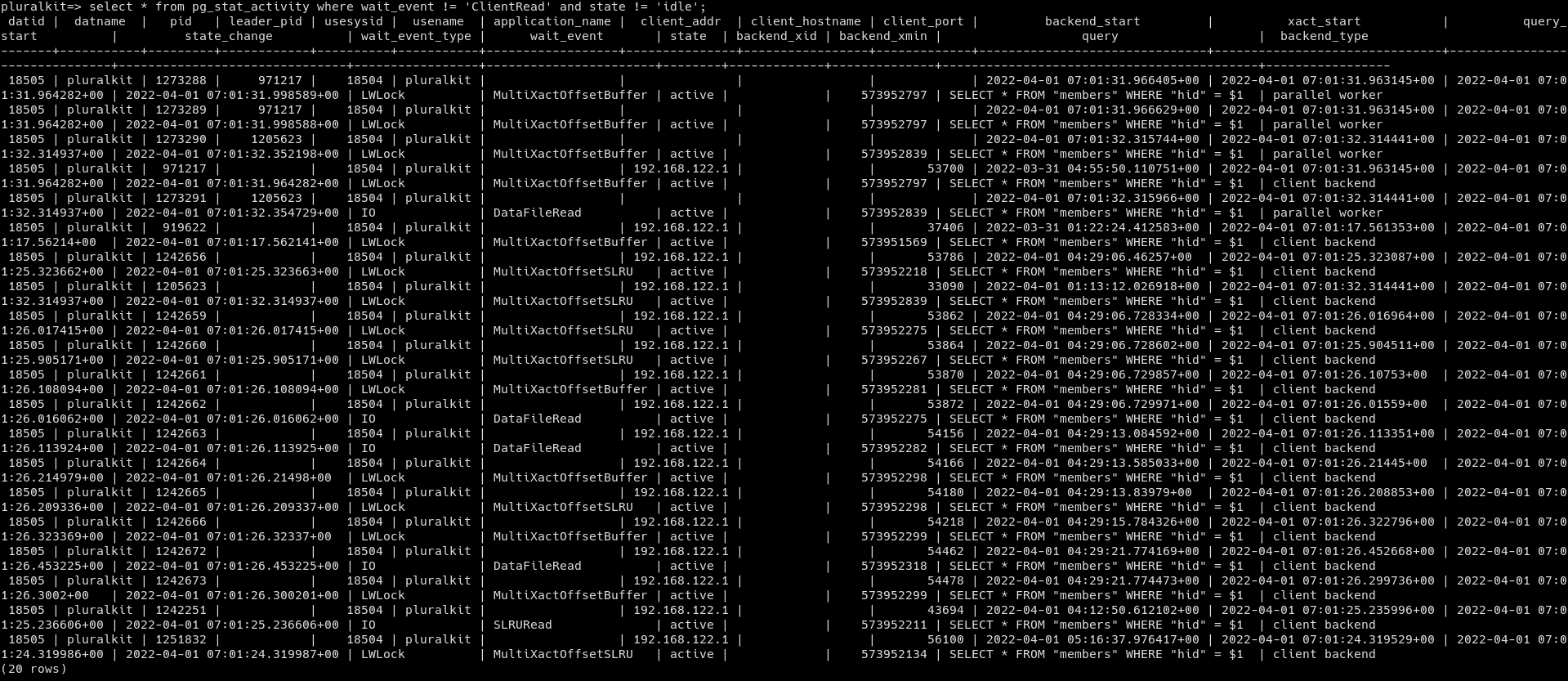
Hey, I'm having a weird issue where a few times a day, any query that hits a specific index (specifically a `unique` column index) gets stuck for anywhere between 1 and 15 minutes on a LWLock (mostly MultiXactOffsetSLRU - not sure what that is, I couldn't find anything about it except for a pgsql-hackers list thread that I didn't really understand). Checking netdata history, these stuck queries coincide with massive disk read; we average ~2MiB/s disk read and it got to 40MiB/s earlier today. These queries used to get stuck for ~15 minutes at worst, but I turned down the query timeout. I assume the numbers above would be worse if I let the queries run for as long as they need, but I don't have any logs from before that change and I don't really want to try that again as it would impact production. I asked on the IRC a few days ago and got the suggestion to increase shared_buffers, but that doesn't seem to have helped at all. I also tried deleting and recreating the index, but that seems to have changed nothing as well. Any suggestions are appreciated since I'm really not sure how to debug this further. I'm also attaching a couple screenshots that might be useful. spiral
Attachment:
20220401_03h04m49s_grim.png
Description: PNG image
Attachment:
20220401_03h05m22s_grim.png
Description: PNG image
Attachment:
pgpEG1BViYx8u.pgp
Description: OpenPGP digital signature

{kind=link}
{kind=link}