Maybe you're not doing this.... but:
Using "data" json(b)/hstore column for all/most/many fields is an antipattern. Use 'data' ONLY for columns that you know will be dynamic.
This way you'll write less data into static-columns (no key-names overhead and better types) --> less data to disk etc (selects will also be faster).Using "data" json(b)/hstore column for all/most/many fields is an antipattern. Use 'data' ONLY for columns that you know will be dynamic.
On Tue, Jan 12, 2016 at 7:25 PM, Cory Tucker <cory.tucker@xxxxxxxxx> wrote:
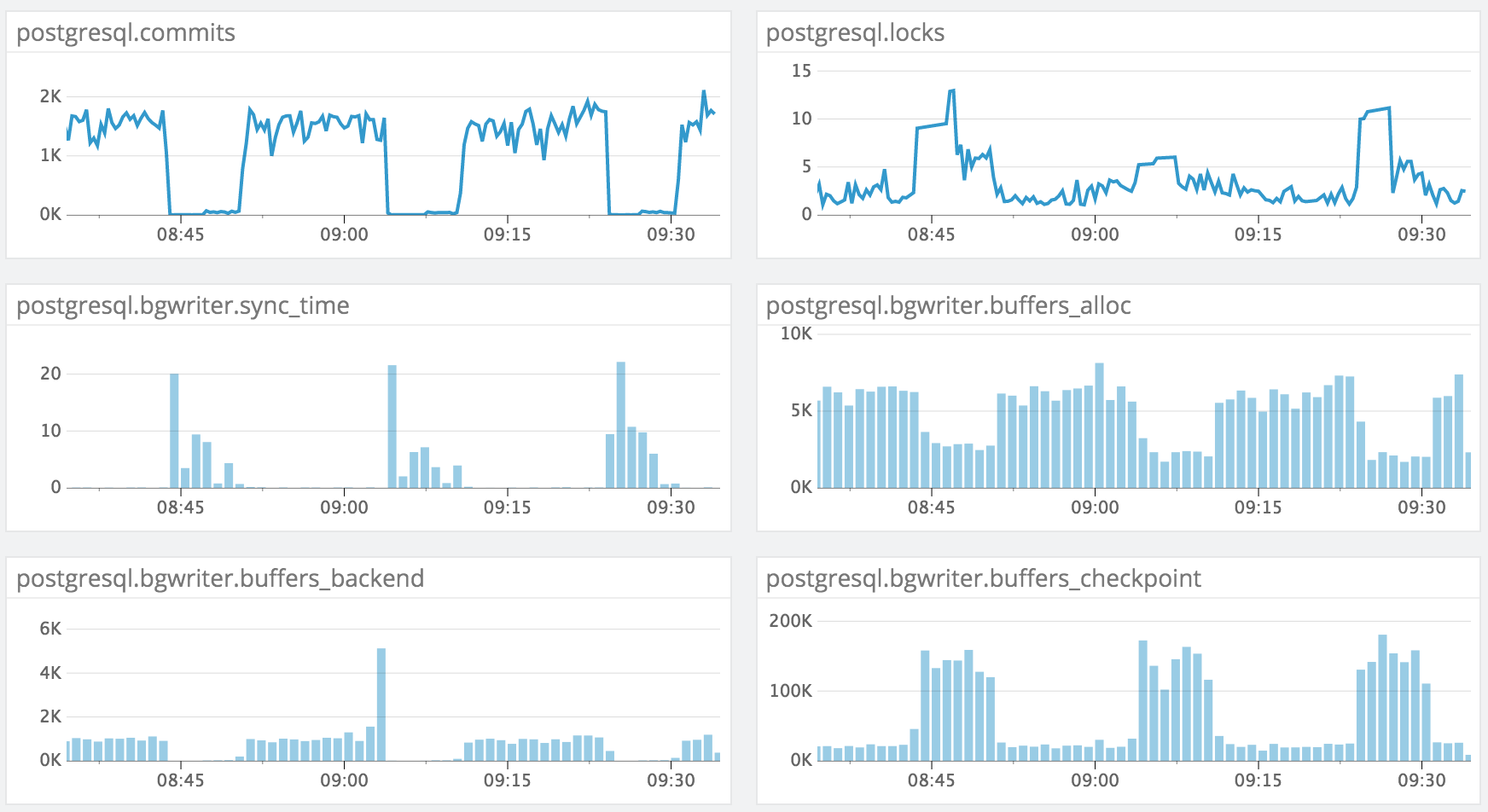
PG 9.4.4 (RDS)I'm experiencing an issue when trying to update many rows in a single table (one row at a time, but parallelized across ~12 connections). The issue we see is that the writes will periodically be blocked for a duration of several minutes and then pick back up. After digging through our monitoring stack, I was able to uncover these stats which seem to allude to it being a background writer performance problem:(apologies for the image)Our settings for the background writer are pretty standard OOB (I threw in some others that I thought might be helpful, too):name | setting | unit-------------------------+---------+------bgwriter_delay | 200 | msbgwriter_lru_maxpages | 100 |bgwriter_lru_multiplier | 2 |maintenance_work_mem | 65536 | kBmax_worker_processes | 8 |work_mem | 32768 | kBThe table that is being written to contains a jsonb column with a GIN index:Table "public.ced"Column | Type | Modifiers---------------+--------------------------+-----------id | bigint | not nullcreated_at | timestamp with time zone |modified_at | timestamp with time zone |bean_version | bigint | default 0account_id | bigint | not nulldata | jsonb | not nullIndexes:"ced_pkey" PRIMARY KEY, btree (id)"ced_data" gin (data jsonb_path_ops)"partition_key_idx" btree (account_id, id)It seems to me that the background writer just can't keep up with the amount of writes that I am trying to do and freezes all the updates. What are my options to improve the background writer performance here?thanks--Cory