Hello, I have a table defined as:
CREATE TABLE demo AS
(
id serial PRIMARY KEY,
start_time timestamp without timezone,
duration integer
)
A sample data set I am working with is:
start_time | duration | end_time
---------------------+----------+---------------------
2006-08-28 16:55:11 | 94 | 2006-08-28 16:56:45
2006-08-28 16:56:00 | 63 | 2006-08-28 16:57:03
2006-08-28 16:56:02 | 25 | 2006-08-28 16:56:27
2006-08-28 16:56:20 | 11 | 2006-08-28 16:56:31
2006-08-28 16:56:20 | 76 | 2006-08-28 16:57:36
2006-08-28 16:56:29 | 67 | 2006-08-28 16:57:36
2006-08-28 16:56:45 | 21 | 2006-08-28 16:57:06
2006-08-28 16:56:50 | 44 | 2006-08-28 16:57:34
2006-08-28 16:56:50 | 36 | 2006-08-28 16:57:26
2006-08-28 16:56:53 | 26 | 2006-08-28 16:57:19
2006-08-28 16:56:57 | 55 | 2006-08-28 16:57:52
2006-08-28 16:57:28 | 1 | 2006-08-28 16:57:29
2006-08-28 16:57:42 | 17 | 2006-08-28 16:57:59
2006-08-28 16:57:46 | 28 | 2006-08-28 16:58:14
2006-08-28 16:58:25 | 51 | 2006-08-28 16:59:16
2006-08-28 16:58:31 | 20 | 2006-08-28 16:58:51
2006-08-28 16:58:35 | 27 | 2006-08-28 16:59:02
generated by the query:
SELECT start_time, duration, to_timestamp((extract(epoch from start_time) + duration))::timestamp as end_time
FROM demo
ORDER BY start_time, duration, 3;
My goal is: To find the maximum number of concurrent rows over an arbitrary interval. Concurrent is defined as overlapping in their duration. Example from the set above: Assume the desired interval is one day. Rows 1 and 2 are concurrent because row 2's start_time is within the duration of row 1. If you go through the set the max concurrency is 5 (this is a guess cause I did it visually and may have miscounted). I took a scan of how I tried to solve it manually and attached the image. I tried using timelines to visualize the start, duration, and end of each row then looked for where they overlapped.
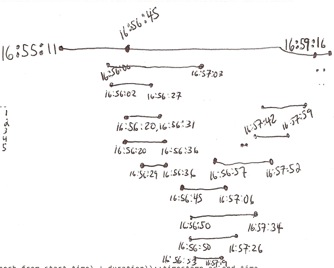
My desired output set would be:
max_concurrency | interval (in this case grouped by day)
--------------------+-----------------
5 | 2006-08-28
if the interval for this set were different, say 30 minutes, then I would expect to see something like:
max_concurrency | interval
--------------------+--------------------------------------------
0 | 2006-08-28 00:00:00 - 2006-08-28 00:29:59
0 | 2006-08-28 00:30:00 - 2006-08-28 00:59:59
0 | 2006-08-28 01:00:00 - 2006-08-28 01:29:59
.......continues.....
0 | 2006-08-28 16:00:00 - 2006-08-28 16:29:59
5 | 2006-08-28 16:30:00 - 2006-08-28 16:59:59
I think that a query that involves a window could be used to solve this question as the documentation says:
"A window function call represents the application of an aggregate-like function over some portion of the rows selected by a query...the window function is able to scan all the rows that would be part of the current row's group according to the grouping specification...."
I am hoping that someone with more experience could help devise a way to do this with a query. Thanks in advance.
--
Sent via pgsql-general mailing list (pgsql-general@xxxxxxxxxxxxxx)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
