On Wed, Mar 20, 2019 at 9:36 AM Maracska Ádám <csuszmusz@xxxxxxxxx> wrote:
Hi,I would like to overcome an issue which occurs only in case with order by clause.Details:I am trying to insert into a temporary table 50 rows from a joined table ordered by a modification time column which is inserted by the current time so it is ordered ascending.Each table has index on the following columns: PRIMARY KEY(SystemID, ObjectID, ElementID, ModificationTime)Statement:sqlString := 'INSERT INTO ResultTable (SELECT * FROM "TABLE" a LEFT OUTER JOIN "TABLE_Text" l1031 ON a.ModificationTime = l1031.ModificationTime AND a.SystemID = l1031.SystemID AND a.ObjectID = l1031.ObjectID AND a.ElementID = l1031.ElementID AND l1031.LCID = 1031 LEFT OUTER JOIN ( SELECT * AS CommentNumber FROM "TABLE_Comment" v1 GROUP BY v1.ModificationTime, v1.SystemID, v1.ObjectID, v1.ElementID ) c ON a.ModificationTime = c.ModificationTime AND a.SystemID = c.SystemID AND a.ObjectID = c.ObjectID AND a.ElementID = c.ElementID WHERE a.ModificationTime BETWEEN $1 AND $2 AND ( a.Enabled = 1 ) ORDER BY a.ModificationTime DESC LIMIT 50));EXECUTE sqlString USING StartTime,EndTime;
node type count sum of times % of query Hash 1 8.844 ms 10.0 % Hash Left Join 1 33.715 ms 38.0 % Insert 1 0.734 ms 0.8 % Limit 1 0.003 ms 0.0 % Seq Scan 2 22.735 ms 25.6 % Sort 1 22.571 ms 25.5 % Subquery Scan 1 0.046 ms 0.1 % Execution Plan: https://explain.depesz.com/s/S96g (Obfuscated)If I remove the order by clause I get the following results:
node type
count
sum of times
% of query
Index Scan
2
27.632 ms
94.9 %
Insert
1
0.848 ms
2.9 %
Limit
1
0.023 ms
0.1 %
Merge Left Join
1
0.423 ms
1.5 %
Result
1
0.000 ms
0.0 %
Subquery Scan
1
0.186 ms
0.6 %
Which is pointing me to a problem with the sorting. Is there any way that I could improve the performance with order by clause?To make the problem more transparent I ran a long run test where you can see that with order by clause the performance is linearly getting worse:Postgresql version: "PostgreSQL 11.1, compiled by Visual C++ build 1914, 64-bit"Istalled by: With EnterpriseDB One-click installer from EDB's offical site.Postgresql.conf changes: Used pgtune suggestions:# DB Version: 11# OS Type: windows# DB Type: desktop# Total Memory (RAM): 8 GB# CPUs num: 4# Connections num: 25# Data Storage: hddmax_connections = 25shared_buffers = 512MBeffective_cache_size = 2GBmaintenance_work_mem = 512MBcheckpoint_completion_target = 0.5wal_buffers = 16MBdefault_statistics_target = 100random_page_cost = 4work_mem = 8738kBmin_wal_size = 100MBmax_wal_size = 1GBmax_worker_processes = 4max_parallel_workers_per_gather = 2max_parallel_workers = 4Operating System: Windows 10 x64, Version: 1607Thanks in advance,Best Regards,Tom Nay
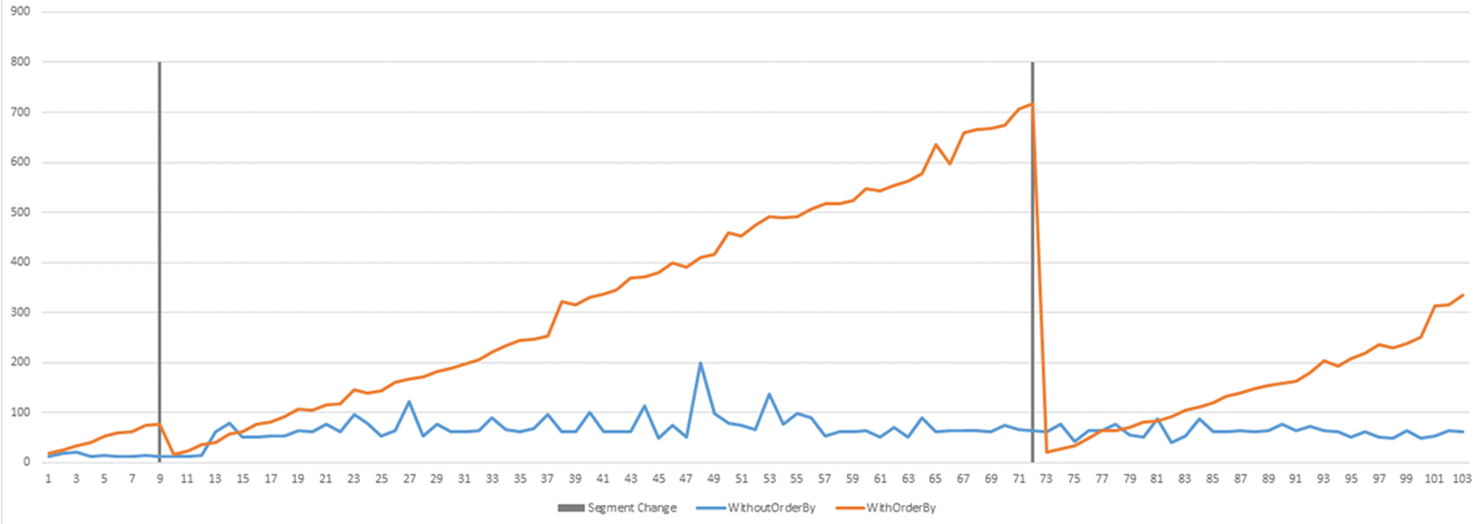
The queries are not equivalent. One returns the first 50 rows it finds regardless of what qualities they possess, and the other one must fetch all rows and then decide which 50 are the most recent.
They're the difference between:
Find any 10 people in your city.
Find the TALLEST 10 people in your city. This will scale poorly in large cities.
Find any 10 people in your city.
Find the TALLEST 10 people in your city. This will scale poorly in large cities.
If you have an index on ModificationTime, then the query can seek to the highest row matching the between clause, and walk backwards looking for rows that match any other criteria, so that will help, because it will avoid the sort.
