This problem seems to have started from the 10th month, this parameter value was changed in the 9th month and was done for all clusters. I thought at first the vacuum didn't work but then I see the auto vacuum was on. My case was, that there was a problem with the auto vacuum but it seems like that's okay too. So the problem is because of the application? If the update-delete progress is coming a lot from application, because of that dead rows are going to loop. And when a new insert operation occurs, the number of dead rows for a single insert increases because it tries too many times.
Abdullah Ergin <abdullaherginwork@xxxxxxxxx>, 20 Kas 2023 Pzt, 01:24 tarihinde şunu yazdı:
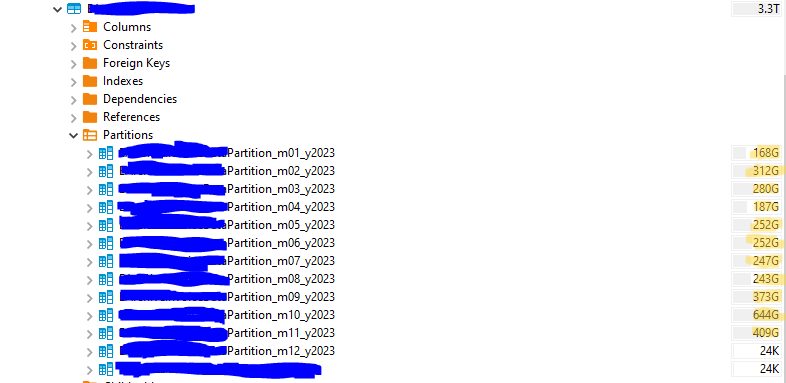
I have a table in a partitioned structure, and the size of the table for the 10th month has doubled compared to previous months. On October 7, 2023, a failover was performed in this database, and the replica server became the master server. Before October 7th, this database was a replica, and after the failover, the auto vacuum parameter in the postgresql.conf file of the database remained commented out. I noticed this on November 11, 2023, and enabled the parameter. During this period, I believe the unchecked increase in table size was due to the auto vacuum parameter being turned off. What should I do to prevent this from affecting the 12th month and beyond?
postgresql.conf;max_connections = 4096 - Memory - max_prepared_transactions = 4096 work_mem = 2MB maintenance_work_mem = 3GB - Asynchronous Behavior - effective_io_concurrency = 200 max_parallel_workers = 2 - Checkpoints - min_wal_size = 2GB max_wal_size = 3GB checkpoint_completion_target = 0.9 - Planner Cost Constants effective_cache_size = 48GB - Sending Servers - max_standby_archive_delay = 300s max_standby_streaming_delay = 300s - Planner Method Configuration - random_page_cost = 1.1 - Query and Index Statistics Collector - track_activity_query_size = 8192