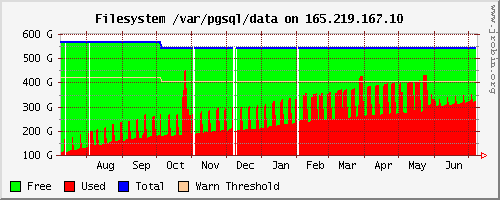
As a follow-up to this: http://archives.postgresql.org/pgsql-admin/2009-03/msg00233.php The strategy described in the above post has worked out very well for us. If you do backups across a relatively slow link, and significant portions of your database remain relatively stable, you might want to consider this approach. Attached is a graph which shows the space used on the volume containing the database and its backups for a county with fast growth in database size due to aggressive document scanning. Notice the weekly spikes -- these represent a new cpio|gzip PITR base backup copied to the local volume. A crontab script would check for completion of its copy to another local server and to the remote server; when both were successful, the *prior* base backup and the WAL files needed for it would be deleted. You can see how the spikes get wider as the portion of the week required to get the backup across the WAN expanded with size. After we implemented the new techniques at the end of May, there is a slightly higher base, because of a full, non-compressed copy of the live database, but the backup times, and the data which needs to be moved both are drastically reduced. (The shorter, narrower spikes give a pretty good idea of the improvement we've seen for this county.) One minor point -- we found that to minimize traffic, it was important to freeze tuples pretty aggressively; otherwise the large insert-only tables sent the data across twice, nearly doubling the bandwidth required for backups. -Kevin
Attachment:
backup-changes.png
Description: Portable Network Graphics Format
-- Sent via pgsql-admin mailing list (pgsql-admin@xxxxxxxxxxxxxx) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-admin

{kind=link}