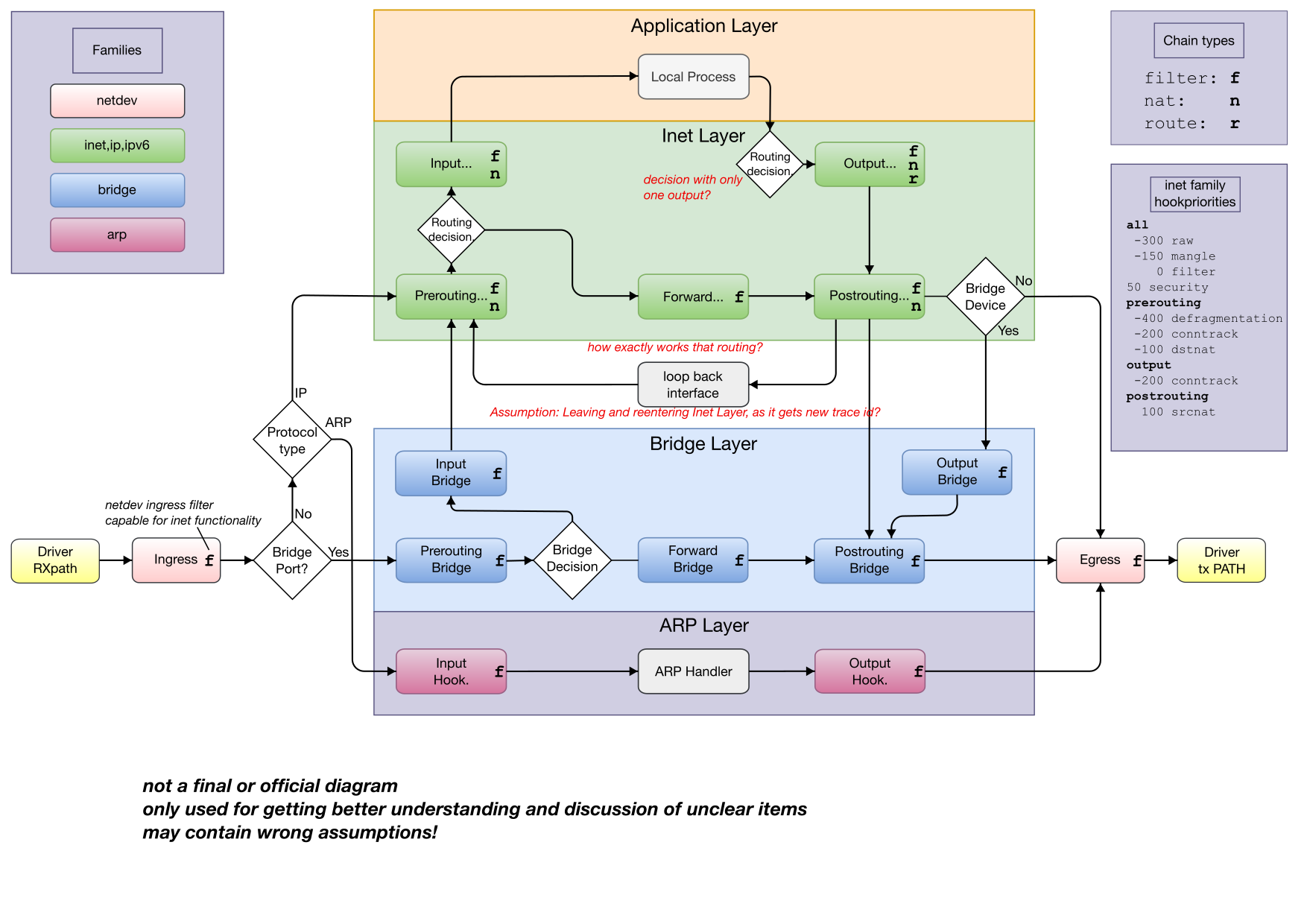
Hello Kerin, thanks for your reply, I will try to answer your questions > You are describing (not altogether persuasively) why you want for so many hooks but not why you > want to set nftrace to 1 for each of them. With the exception of ingress/egress, enabling nftrace > for the two previously suggested hooks would have been quite sufficient. > # Pointless if solely for enabling nftrace for a 'big picture' perspective. > # Please use raw (-300) as was suggested. > type filter hook prerouting priority filter - 1; policy accept; I just wan't the hooks for my understanding, and have a template, I later can take, modifying for tracing down issues in real live. Right now its just for understanding the system, and seeing, that those hooks are beeing called for certain packets. About raw priority: When I understand https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks#Priority_within_hook right, priorities have no influence that a hook is called or not. Priorities only assign the order, in which the chains are called at this hook. So I can have for example two chains in the same hook, one with priority -450 and one with priority 301. So I would see e.g. in prerouting in the first hook two fragmentated packets and in the latter hook only one defragmented packet. Or I could see in a postrouting chain a packet before and after snat. But my hook should see the packet in each case, please correct me, if I am wrong. So from my understanding, priorities are getting important, as soon, as I wish to investigate in a certain kind of problem, than the priority is very important, to understand, what I am seeing. > It's not clear that you understand that the value of nftrace doesn't quietly reset itself to 0 between hooks, however. Can you explain this further? Which value of nftrace? What shall reset itself? >> 1) How is inet traffic flowing from application to application? Where >> is the hidden way from >> postrouting to prerouting? It must somehow leave netfilter, as packets >> are reappearing with a new >> trace id? > A packet is transmitted over the loopback interface then a packet is received at the loopback > interface. Locally generated packets are routed over the loopback interface for all locally owned > destination addresses, not only 127.0.0.0/8 and ::1. Otherwise, the fact that the loopback > interface is involved isn't of any particular significance. Thanks for that very important answer! That helps me a lot and that should be part of the diagram, as this path is not going to ingress/egress. I try to investigate that further, as I am interested in the whole picture. Can it be, that the "Bridge device?" decision is a tri-state decision, for checking bridge, physical interface or loopback? I enclose an updated diagram, where I have included this path as an temporary one and some other findings. Please have a look at it and give me feedback. >> >> 2) Why nat traces need a trigger through a succesful nat connection, to >> start working? Is my >> observation right, that tcp-wise only SYN-packets pass the nat-hooks? > The previously offered wiki link attempts to explain this, though the wording could be improved. > The following two bullet points have been lifted from the article in question. > - The first packet of a flow is used to look up for a matching rule which sets up the NAT binding > for this flow. This also manipulates this first packet accordingly. > - No rule lookup happens for follow up packets in the flow: the NAT engine uses the NAT binding > information already set up by the first packet to perform the packet manipulation. > The "information" in question is stored by the conntrack table, whose contents can be inspected > with - and monitored by - the conntrack(8) utility from conntrack-tools. The overwhelming majority > of Linux distributions activate the conntrack subsystem at the point that any ruleset is loaded > containing at least one rule pertaining to conntrack state, thereby causing for the applicable > kernel modules to be dynamically loaded. Typically, that would be a NAT rule or a rule that tries > to match on ctstate. One activated, the conntrack state machine continues to perform its duties > until such time as the kernel modules are unloaded, even in the case of an empty ruleset. > A TCP packet with the SYN flag set is something that might create a new entry in the conntrack > table. As such, it is to be expected that it may be intercepted by a nat hook, whereas subsequent > packets that the conntrack state machine can match against an existing flow won't be. In fact, > even an ACK packet can create a new TCP flow, unless the value of the > "net.netfilter.nf_conntrack_tcp_loose" sysctl is set to 0. Thanks for that hint as well, looks like, that I have overseen that. The picture gets more clear every day! Regards Wolfgang
Attachment:
nf-hooks-temporary-version.png
Description: PNG image

{kind=link}