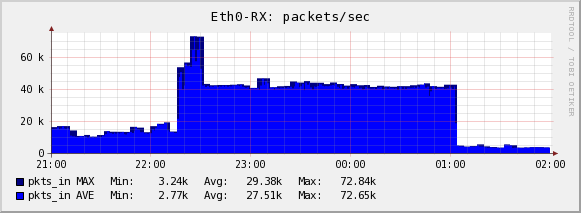
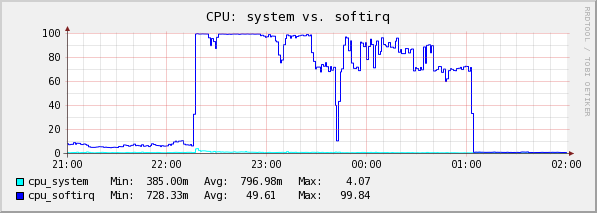
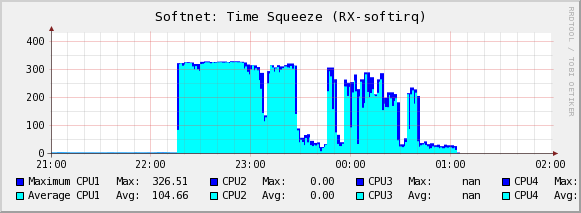
Le samedi 24 avril 2010 à 13:11 +0200, Jesper Dangaard Brouer a écrit : > On Fri, 23 Apr 2010, Eric Dumazet wrote: > > > Le jeudi 22 avril 2010 à 22:38 +0200, Jesper Dangaard Brouer a écrit : > > > >> > >> I think its plausable, there is a lot of modification going on. > >> Approx 40.000 deletes/sec and 40.000 inserts/sec. > >> The hash bucket size is 300032, and with 80000 modifications/sec, we are > >> (potentially) changing 26.6% of the hash chains each second. > >> > >> As can be seen from the graphs: > >> http://people.netfilter.org/hawk/DDoS/2010-04-12__001/list.html > >> > >> Notice that primarily CPU2 is doing the 40k deletes/sec, while CPU1 is > >> caught searching... > >> > >> > >>> maybe hash table has one slot :) > >> > >> Guess I have to reproduce the DoS attack in a testlab (I will first have > >> time Tuesday). So we can determine if its bad hashing or restart of the > >> search loop. > >> > >> > >> The traffic pattern was fairly simple: > >> > >> 200 bytes UDP packets, comming from approx 60 source IPs, going to one > >> destination IP. The UDP destination port number was varied in the range > >> of 1 to 6000. The source UDP port was varied a bit more, some ranging > >> from 32768 to 61000, and some from 1028 to 5000. > >> > >> > > > > Re-reading this, I am not sure there is a real problem on RCU as you > > pointed out. > > > > With 800.000 entries, in a 300.032 buckets hash table, each lookup hit > > about 3 entries (aka searches in conntrack stats) > > > > 300.000 packets/second -> 900.000 'searches' per second. > > The machine is not getting 300.000 pps, its only getting 40.000 pps (the > rest is stopped by the NIC by sending Ethernet flowcontrol pause frames) > > http://people.netfilter.org/hawk/DDoS/2010-04-12__001/eth0-rx.png > > We are doing 700.000 'searches' per second, with 40.000 pps, thus on > average the list lenght (in each hash bucket) just need to be 17.5 > elements. Is this an acceptable has distribution, with 900.000 elements > in a 300.032 buckets hash table? > > > > If you have four cpus all trying to insert/delete entries in //, they > > all hit the central conntrack lock. > > This machine only have two CPUs, or rather one physical CPU and one > hyperthreaded. The server is a old HP380 G4, with an old Xeon type CPU > 3.4 GHz (1MB cache). If remember correctly its based on Pentium-4 > technologi, which had a pretty bad hyperthreading. > > > > On a DDOS scenario, every packet needs to take this lock twice, > > once to free an old conntrack (early drop), once to insert a new entry. > > I was worried about if the "early drop" e.g. free an old conntrack would > disturbe the conntrack searching? > > > > To scale this, only way would be to have an array of locks, like we have > > for TCP/UDP hash tables. > > > > I did some tests here, with a multiqueue card, flooded with 300.000 > > pack/second, 65.536 source IP, millions of flows, and nothing wrong > > happened (but packets drops, of course) > > A small hint when testing, use Haralds tool 'lnstat' to see the stats on > the command line, thus you don't need to RRDtool graphe every thing: > > Command: > lnstat -f nf_conntrack -i 1 -c 1000 > > I don't have a multiqueue NIC in this old machine. > > I also ran some tests on my 10G testlab, but it didn't go wrong. > Tweeking the pktgen DDoS I could get the system to do 4.500.000 'searches' > per sec with a 1.500.000 packets/sec. (Have not reloaded the kernel with > the new failed lookup stats). Guess my 10G machines are too fast to hit > the issues. > > > > My two cpus were busy 100%, after tweaking smp_affinities, because on > > first try, irqbalance put "01" mask on both queues, so only one ksoftirq > > was working, other cpu was idle :( > > Think my machine is some what slower than yours, perhaps its simply not > fast enough for this kind of workload (pretty sure that the cache is the > CPU is getting f*ked in this case). > > On my machine one CPU in stuck in softirq: > http://people.netfilter.org/hawk/DDoS/2010-04-12__001/cpu_softirq001.png > > And another observation is that the CPUs are disturbing each other on the > RX softirq code path. > http://people.netfilter.org/hawk/DDoS/2010-04-12__001/softnet_time_squeeze_rx-softirq001.png > (/proc/net/softnet_stat column 3) > > Monday or Tuesdag I'll do a test setup with some old HP380 G4 machines to > see if I can reproduce the DDoS attack senario. And see if I can get > it into to lookup loop. Theorically a loop is very unlikely, given a single retry is very unlikly too. Unless a cpu gets in its cache a corrupted value of a 'next' pointer. Maybe a hardware problem ? My test machine is a fairly low end one, an AMD Athlon Dual core 5050e, 2.6 GHz I used an igb card for ease of setup, and to make sure my two cores would handle packets in parallel, without RPS. With same hash bucket size (300.032) and max conntracks (800.000), and after more than 10 hours of test, not a single lookup was restarted because of a nulls with wrong value. I can setup a test on a 16 cpu machine, multiqueue card too. Hmm, I forgot to say I am using net-next-2.6, not your kernel version... -- To unsubscribe from this list: send the line "unsubscribe netfilter-devel" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
{kind=link}
{kind=link}
