Dne 18.2.2017 v 17:55 Mark Mielke napsal(a):
One aspect that has confused me in this discussion, that I was hoping somebody
would address...
I believe I have seen slower than expected pvmove times in the past (but I
only rarely do it, so it has never particularly concerned me). When I saw it,
my first assumption was that the pvmove had to be done "carefully" to ensure
that every segment was safely moved in such a way that it was definitely in
one place, or definitely in the other, and not "neither" or "both". This is
particularly important if the volume is mounted, and is being actively used,
which was my case.
Would these safety checks not reduce overall performance? Sure, it would
transfer one segment at full speed, but then it might pause to do some
book-keeping, making sure to fully synch the data and metadata out to both
physical volumes and ensure that it was still crash-safe?
For SAN speeds - I don't think LVM has ever been proven to be a bottleneck for
me. On our new OpenStack cluster, I am seeing 550+ MByte/s with iSCSI backed
disks, and 700+ MByte/s with NFS backed disks (with read and write cached
disabled). I don't even look at LVM as a cause of concern here as there is
usually something else at play. In fact, on the same OpenStack cluster, I am
using LVM on NVMe drives, with an XFS LV to back the QCOW2 images, and I can
get 2,000+ MByte/s sustained with this setup. Again, LVM isn't even a
performance consideration for me.
So let's recap some fact first:
lvm2 is NOT doing any device itself - all the lvm2 does - it manages dm tables
and keeps metadata for them in sync.
So it's always some 'dm' device what does the actual work.
For pvmove there is currently a bit 'oldish' dm mirror target
(see dmsetup targets for available one).
Once it will be possible lvm2 will switch to use 'raid' target which might
provide slightly better speed for some tasks.
There is some 'known' issue with old mirror and smaller region size if there
is parallel read&write into a mirror - this was not yet fully addressed,
but if the device in the mirror the have 'bigger' latencies, usage of
bigger chunks size does help to increase throughput.
(In simple words - bigger --regionsize has less commit points)
However this is likely not the case here - all devices are supposedly very
fast and attached over hyperfast network.
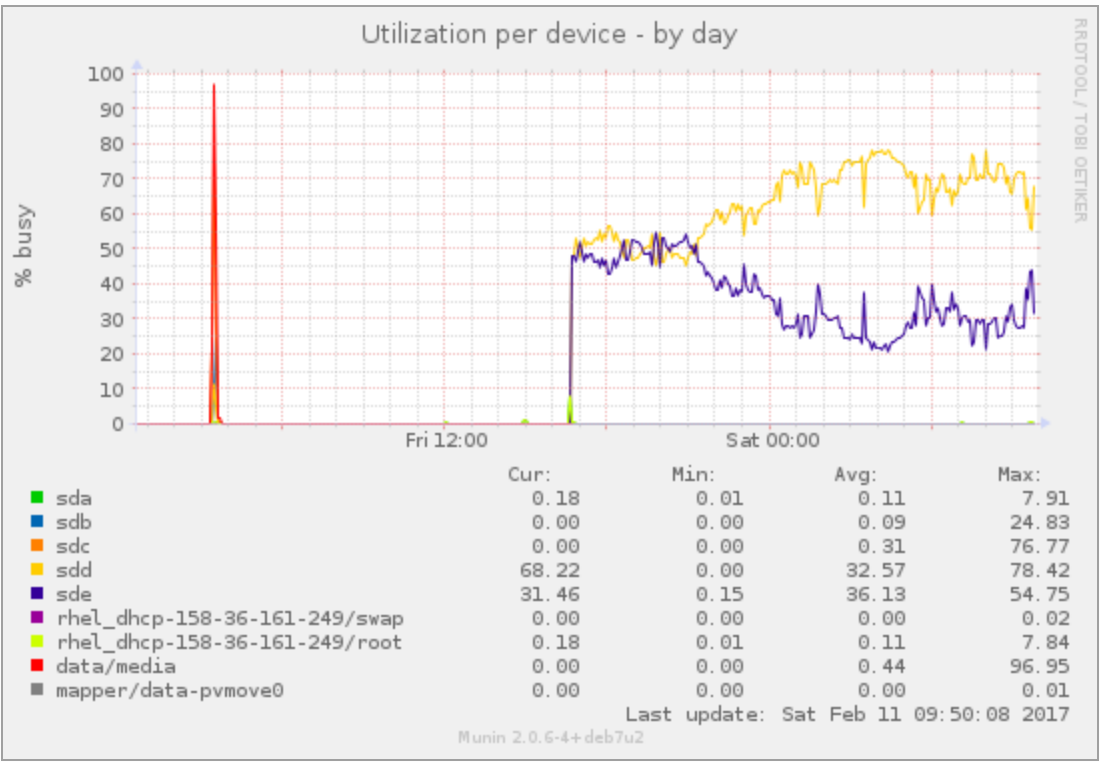
When looking at this graph: https://karlsbakk.net/tmp/pvmove-dev-util.png
it strikes in the eyes that initial couple hours were running fine, but after
a while 'controller' started to prefer /dev/sdd over /dev/sde and the
usage is mostly 'reflected'.
So my question would be - how well the controller works over the longer period
of time of sustained load ?
To me this looks more like a 'driver' issue for this iSCSI hardware blackbox?
Could you also try the same load with 'dd' ?
i.e. running 'dd' 1/2 day whether the performance will not start to drop as
can be observed with pvmove ?
dm mirror target is basically only using kernel kcopyd thread to copy device
'A' to device 'B' and it does sync bitmap (a bit of slowdown factor)
So in theory it should work just like 'dd'. For 'dd' you could however
configure some better options for 'directio' and buffer sizes.
Regards
Zdenek
_______________________________________________
linux-lvm mailing list
linux-lvm@redhat.com
https://www.redhat.com/mailman/listinfo/linux-lvm
read the LVM HOW-TO at http://tldp.org/HOWTO/LVM-HOWTO/

{kind=link}