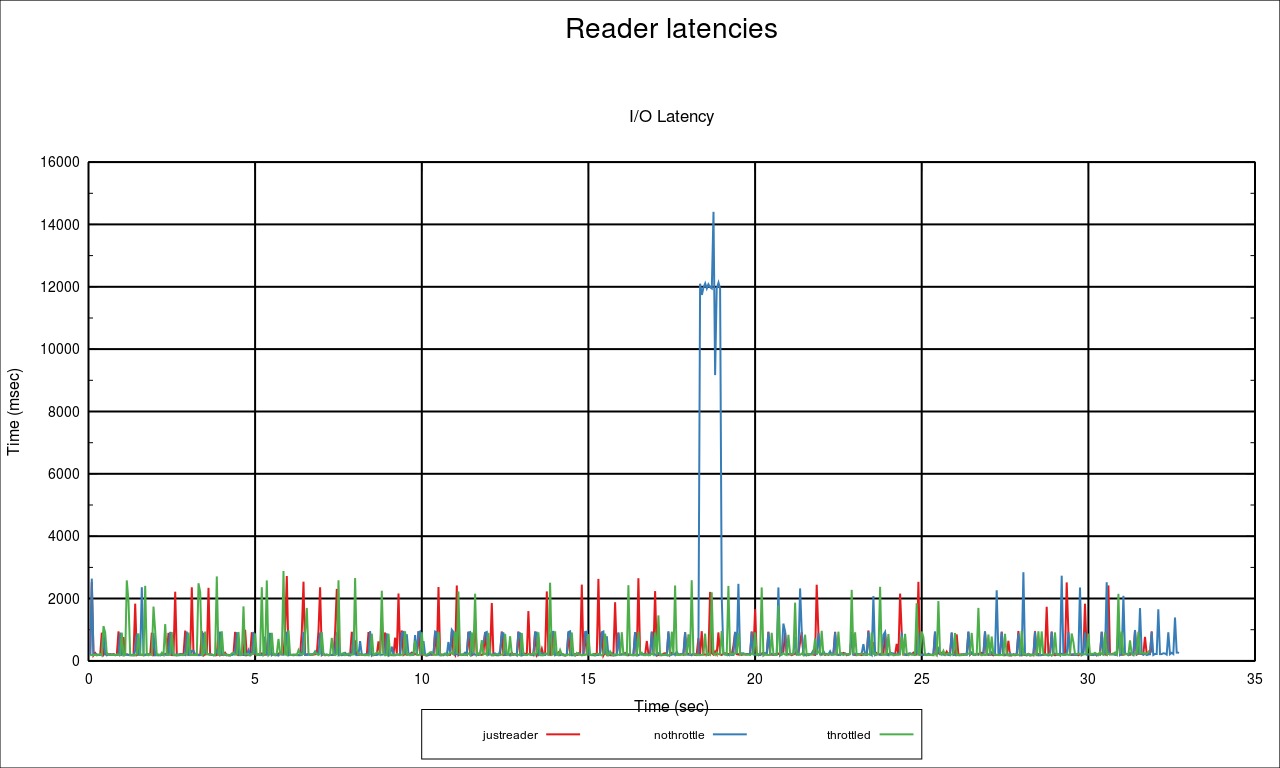
I implemented support for discards in blk-wbt, so we treat them like background writes. If we have competing foreground IO, then we may throttle discards. Otherwise they should run at full speed. Ran a quick local test case on a NVMe device. The test case here is doing reads from a file, while other files are being delete. File system is XFS. Three separate runs: 1) 'justreader' is just running the reader workload by itself. 2) 'nothrottle' is running the reader with the unlinks on the stock kernel. 3) 'throttled' is running the reader with the unlinks with the patches applied. The fio run logs latencies in windows of 50msec, logging only the worst latency seen in that window: [read] filename=file0 rw=randread bs=4k direct=1 ioengine=libaio iodepth=8 write_lat_log=read_lat log_avg_msec=50 log_max_value=1 Graph of the latencies here: http://kernel.dk/wbt-discard.jpg As you can see, with the throttling, the latencies and performance is the same as not having the unlinks running. They finish within 100msec of each other, after having read 10G of data. Without the throttling and unlinks running, we see spikes that are almost an order of magnitude worse. The reader also takes 1 second longer to complete. 322MB/sec vs 313MB/sec. It's also visible in the higher Pxx. Here's the throttled end of the percentiles: | 99.00th=[ 145], 99.50th=[ 153], 99.90th=[ 180], 99.95th=[ 198], | 99.99th=[ 889] and here's the unthrottled equivalent: | 99.00th=[ 145], 99.50th=[ 155], 99.90th=[ 188], 99.95th=[ 322], | 99.99th=[ 8586] Changes since v1: - Pass in enum wbt_flags for get_rq_wait() - Turn wbt_should_throttle() into a switch statement blk-lib.c | 7 +++--- blk-stat.h | 6 ++--- blk-wbt.c | 70 ++++++++++++++++++++++++++++++++++++------------------------- blk-wbt.h | 8 +++++- 4 files changed, 55 insertions(+), 36 deletions(-) -- To unsubscribe from this list: send the line "unsubscribe linux-xfs" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
