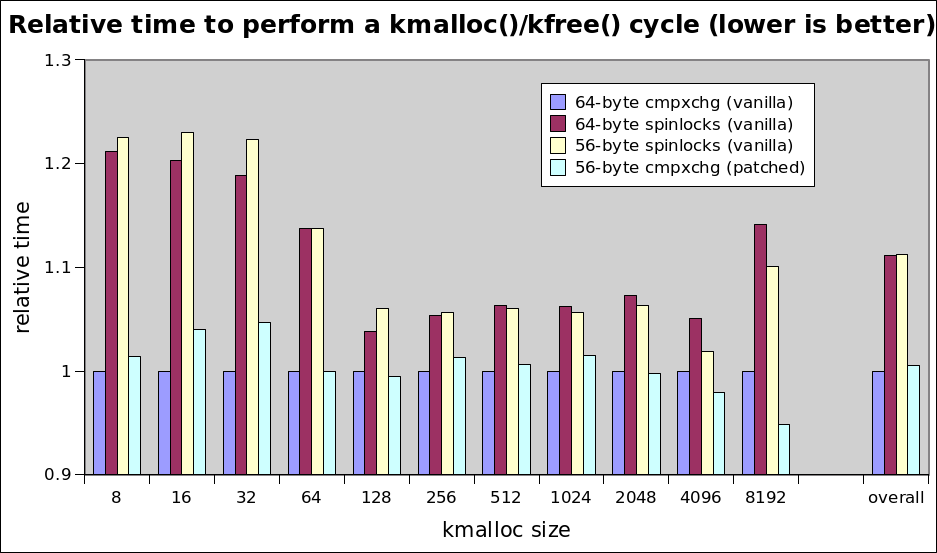
This is a minor update from the last version. The most notable thing is that I was able to demonstrate that maintaining the cmpxchg16 optimization has _some_ value. These are still of RFC quality. They're stable, but definitely needs some wider testing, especially on 32-bit. Mostly just resending for Christoph to take a look. These currently apply on top of linux-next. Otherwise, the code changes are just a few minor cleanups. --- SLUB depends on a 16-byte cmpxchg for an optimization which allows it to not disable interrupts in its fast path. This optimization has some small but measurable benefits stemming from the cmpxchg code not needing to disable interrrupts: http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png In order to get guaranteed 16-byte alignment (required by the hardware on x86), 'struct page' is padded out from 56 to 64 bytes. Those 8-bytes matter. We've gone to great lengths to keep 'struct page' small in the past. It's a shame that we bloat it now just for alignment reasons when we have extra space. Plus, bloating such a commonly-touched structure *HAS* cache footprint implications. The implications can be easily shown with 'proc stat' when doing 16.8M kmalloc(32)/kfree() pairs: vanilla 64-byte struct page: > 883,412 LLC-loads # 0.296 M/sec > 566,546 LLC-load-misses # 64.13% of all LL-cache hits patched 56-byte struct page: > 556,751 LLC-loads # 0.186 M/sec > 339,106 LLC-load-misses # 60.91% of all LL-cache hits These patches attempt _internal_ alignment instead of external alignment for slub. I also got a bug report from some folks running a large database benchmark. Their old kernel uses slab and their new one uses slub. They were swapping and couldn't figure out why. It turned out to be the 2GB of RAM that the slub padding wastes on their system. On my box, that 2GB cost about $200 to populate back when we bought it. I want my $200 back. This set takes me from 16909584K of reserved memory at boot down to 14814472K, so almost *exactly* 2GB of savings! It also helps performance, presumably because it touches 14% fewer struct page cachelines. A 30GB dd to a ramfs file: dd if=/dev/zero of=bigfile bs=$((1<<30)) count=30 is sped up by about 4.4% in my testing. I've run this through its paces and have not had stability issues with it. It definitely needs some more testing, but it's definitely ready for a wider audience. I also wrote up a document describing 'struct page's layout: http://tinyurl.com/n6kmedz -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxx. For more info on Linux MM, see: http://www.linux-mm.org/ . Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}