On 04.05.2013 15:01, Konstantin Khlebnikov wrote:
Konstantin Khlebnikov wrote:Zlatko Calusic wrote:On 30.04.2013 13:02, Konstantin Khlebnikov wrote:This patch adds engine for estimating rotation time for pages in lru lists. This adds bunch of 'milestones' into each struct lruvec and inserts them into lru lists periodically. Milestone flows in lru together with pages and brings timestamp to the end of lru. Because milestones are embedded into lruvec they can be easily distinguished from pages by comparing pointers. Only few functions should care about that. This machinery provides discrete-time estimation for age of pages from the end of each lru and average age of each kind of evictable lrus in each zone.Great stuff!Thanks!Believe it or not, I had an idea of writing something similar to this, but of course having an idea and actually implementing it are two very different things. Thank you for your work! I will use this to prove (or not) that file pages in the normal zone on a 4GB RAM machine are reused waaaay too soon. Actually, I already have the patch applied and running on the desktop, but it should be much more useful on server workloads. Desktops have erratic load and can go for a long time with very little I/O activity. But, here are the current numbers anyway: Node 0, zone DMA32 pages free 5371 nr_inactive_anon 4257 nr_active_anon 139719 nr_inactive_file 617537 nr_active_file 51671 inactive_ratio: 5 avg_age_inactive_anon: 2514752 avg_age_active_anon: 2514752 avg_age_inactive_file: 876416 avg_age_active_file: 2514752 Node 0, zone Normal pages free 424 nr_inactive_anon 253 nr_active_anon 54480 nr_inactive_file 63274 nr_active_file 44116 inactive_ratio: 1 avg_age_inactive_anon: 2531712 avg_age_active_anon: 2531712 avg_age_inactive_file: 901120 avg_age_active_file: 2531712In our kernel we use similar engine as source of statistics for scheduler in memory reclaimer. This is O(1) scheduler which shifts vmscan priorities for lru vectors depending on their sizes, limits and ages. It tries to balance memory pressure among containers. I'll try to rework it for the mainline kernel soon. Seems like these ages also can be used for optimal memory pressure distribution between file and anon pages, and probably for balancing pressure among zones.This all sounds very promising. Especially because I currently observe quite some imbalance among zones.As I see, most likely reason of such imbalances is 'break' condition inside of shrink_lruvec(). So can try to disable it see what will happen. But these numbers from your desktop actually doesn't proves this problem. Seems like difference between zones is within the precision of this method. I don't know how to describe this precisely. Probably irregularity between milestones also should be taken into the account to describe current situation and quality of measurement. Here current numbers from my 8Gb node. Main workload is a torrent client. Node 0, zone DMA32 nr_inactive_anon 1 nr_active_anon 1494 nr_inactive_file 404028 nr_active_file 365525 nr_dirtied 855068 nr_written 854991 avg_age_inactive_anon: 64942528 avg_age_active_anon: 64942528 avg_age_inactive_file: 1281317 avg_age_active_file: 15813376 Node 0, zone Normal nr_inactive_anon 376 nr_active_anon 13793 nr_inactive_file 542605 nr_active_file 542247 nr_dirtied 2746747 nr_written 2746266 avg_age_inactive_anon: 65064192 avg_age_active_anon: 65064192 avg_age_inactive_file: 1260611 avg_age_active_file: 8765240 So, here noticeable imbalance in ages of active file lru and nr_dirtied/nr_written. I have no idea why, but torrent client uses syscall fadvise() which messes whole picture.Hey! I can reproduce this: Node 0, zone DMA32 nr_inactive_anon 1 nr_active_anon 2368 nr_inactive_file 373642 nr_active_file 375462 nr_dirtied 2887369 nr_written 2887291 inactive_ratio: 5 avg_age_inactive_anon: 64942528 avg_age_active_anon: 64942528 avg_age_inactive_file: 389824 avg_age_active_file: 1330368 Node 0, zone Normal nr_inactive_anon 376 nr_active_anon 17768 nr_inactive_file 534695 nr_active_file 533685 nr_dirtied 12071397 nr_written 11940007 inactive_ratio: 6 avg_age_inactive_anon: 65064192 avg_age_active_anon: 65064192 avg_age_inactive_file: 28074 avg_age_active_file: 1304800 I'm just copying huge files from one disk to another by rsync. In /proc/vmstat pgsteal_kswapd_normal and pgscan_kswapd_normal are rising rapidly, other pgscan_* pgsteal_* are standing still. So, bug is somewhere in the kswapd.
Not necessarily, because processes also do a direct reclaim. Also, if you continued the copying, I bet you would see that DMA32 zone also gets to play. Just a bit later.
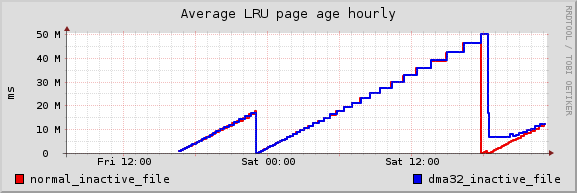
I can now see that effect nicely on the graphs I prepared. Attached is one from the desktop. Where the red line suddenly drops, I copied 2GB file from the network to the machine. Half an hour later I copied another 1.6GB file. That's when the blue line dropped. Though, it all makes sense, about 3GB of I/O was needed to expunge all old inactive pages from both zones, the first 2GB wasn't enough to push old pages from the DMA32 zone.
I'm of the opinion that your instrumentation will be of use only when there's a constant reclaim goin' on. Otherwise pages stay in memory for a long long time, and then it doesn't matter much if it's one hour or two hours before some of them are reclaimed. For the same reason I will limit graphs like these to some useful value, so to get precision for the important time periods when the reclaim is really active.
-- Zlatko
Attachment:
memage-hourly.png
Description: PNG image
{kind=link}