This is a patch to improve swap readahead algorithm. It's from Hugh and I
slightly changed it.
Hugh's original changelog:
swapin readahead does a blind readahead, whether or not the swapin
is sequential. This may be ok on harddisk, because large reads have
relatively small costs, and if the readahead pages are unneeded they
can be reclaimed easily - though, what if their allocation forced
reclaim of useful pages? But on SSD devices large reads are more
expensive than small ones: if the readahead pages are unneeded,
reading them in caused significant overhead.
This patch adds very simplistic random read detection. Stealing
the PageReadahead technique from Konstantin Khlebnikov's patch,
avoiding the vma/anon_vma sophistications of Shaohua Li's patch,
swapin_nr_pages() simply looks at readahead's current success
rate, and narrows or widens its readahead window accordingly.
There is little science to its heuristic: it's about as stupid
as can be whilst remaining effective.
The table below shows elapsed times (in centiseconds) when running
a single repetitive swapping load across a 1000MB mapping in 900MB
ram with 1GB swap (the harddisk tests had taken painfully too long
when I used mem=500M, but SSD shows similar results for that).
Vanilla is the 3.6-rc7 kernel on which I started; Shaohua denotes
his Sep 3 patch in mmotm and linux-next; HughOld denotes my Oct 1
patch which Shaohua showed to be defective; HughNew this Nov 14
patch, with page_cluster as usual at default of 3 (8-page reads);
HughPC4 this same patch with page_cluster 4 (16-page reads);
HughPC0 with page_cluster 0 (1-page reads: no readahead).
HDD for swapping to harddisk, SSD for swapping to VertexII SSD.
Seq for sequential access to the mapping, cycling five times around;
Rand for the same number of random touches. Anon for a MAP_PRIVATE
anon mapping; Shmem for a MAP_SHARED anon mapping, equivalent to tmpfs.
One weakness of Shaohua's vma/anon_vma approach was that it did
not optimize Shmem: seen below. Konstantin's approach was perhaps
mistuned, 50% slower on Seq: did not compete and is not shown below.
HDD Vanilla Shaohua HughOld HughNew HughPC4 HughPC0
Seq Anon 73921 76210 75611 76904 78191 121542
Seq Shmem 73601 73176 73855 72947 74543 118322
Rand Anon 895392 831243 871569 845197 846496 841680
Rand Shmem 1058375 1053486 827935 764955 764376 756489
SSD Vanilla Shaohua HughOld HughNew HughPC4 HughPC0
Seq Anon 24634 24198 24673 25107 21614 70018
Seq Shmem 24959 24932 25052 25703 22030 69678
Rand Anon 43014 26146 28075 25989 26935 25901
Rand Shmem 45349 45215 28249 24268 24138 24332
These tests are, of course, two extremes of a very simple case:
under heavier mixed loads I've not yet observed any consistent
improvement or degradation, and wider testing would be welcome.
Shaohua Li:
Test shows Vanilla is slightly better in sequential workload than Hugh's patch.
I observed with Hugh's patch sometimes the readahead size is shrinked too fast
(from 8 to 1 immediately) in sequential workload if there is no hit. And in
such case, continuing doing readahead is good actually.
I don't prepare a sophisticated algorithm for the sequential workload because
so far we can't guarantee sequential accessed pages are swap out sequentially.
So I slightly change Hugh's heuristic - don't shrink readahead size too fast.
Here is my test result (unit second, 3 runs average):
Vanilla Hugh New
Seq 356 370 360
Random 4525 2447 2444
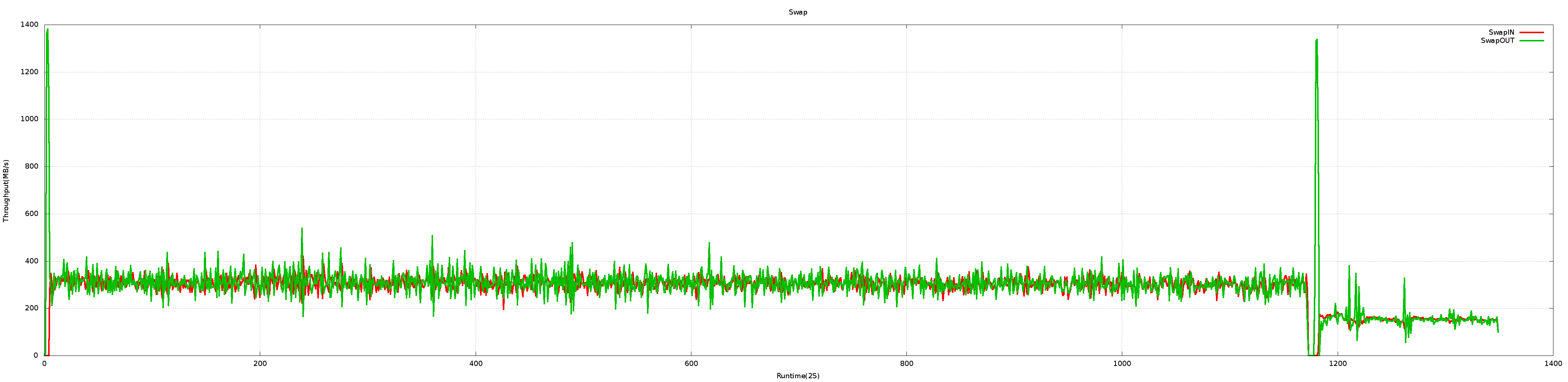
Attached graph is the swapin/swapout throughput I collected with 'vmstat 2'.
The first part is running a random workload (till around 1200 of the x-axis)
and the second part is running a sequential workload. swapin and swapout
throughput are almost identical in steady state in both workloads. These are
expected behavior. while in Vanilla, swapin is much bigger than swapout
especially in random workload (because wrong readahead).
Original-patch-by: Shaohua Li <shli@xxxxxxxxxxxx>
Original-patch-by: Konstantin Khlebnikov <khlebnikov@xxxxxxxxxx>
Signed-off-by: Hugh Dickins <hughd@xxxxxxxxxx>
Signed-off-by: Shaohua Li <shli@xxxxxxxxxxxx>
Cc: Rik van Riel <riel@xxxxxxxxxx>
Cc: Wu Fengguang <fengguang.wu@xxxxxxxxx>
Cc: Minchan Kim <minchan@xxxxxxxxxx>
---
include/linux/page-flags.h | 4 +-
mm/swap_state.c | 63 ++++++++++++++++++++++++++++++++++++++++++---
2 files changed, 62 insertions(+), 5 deletions(-)
Index: linux/include/linux/page-flags.h
===================================================================
--- linux.orig/include/linux/page-flags.h 2013-04-12 15:07:05.011112763 +0800
+++ linux/include/linux/page-flags.h 2013-04-15 11:48:12.161080804 +0800
@@ -228,9 +228,9 @@ PAGEFLAG(OwnerPriv1, owner_priv_1) TESTC
TESTPAGEFLAG(Writeback, writeback) TESTSCFLAG(Writeback, writeback)
PAGEFLAG(MappedToDisk, mappedtodisk)
-/* PG_readahead is only used for file reads; PG_reclaim is only for writes */
+/* PG_readahead is only used for reads; PG_reclaim is only for writes */
PAGEFLAG(Reclaim, reclaim) TESTCLEARFLAG(Reclaim, reclaim)
-PAGEFLAG(Readahead, reclaim) /* Reminder to do async read-ahead */
+PAGEFLAG(Readahead, reclaim) TESTCLEARFLAG(Readahead, reclaim)
#ifdef CONFIG_HIGHMEM
/*
Index: linux/mm/swap_state.c
===================================================================
--- linux.orig/mm/swap_state.c 2013-04-12 15:07:05.003112912 +0800
+++ linux/mm/swap_state.c 2013-04-15 11:48:12.165078764 +0800
@@ -63,6 +63,8 @@ unsigned long total_swapcache_pages(void
return ret;
}
+static atomic_t swapin_readahead_hits = ATOMIC_INIT(4);
+
void show_swap_cache_info(void)
{
printk("%lu pages in swap cache\n", total_swapcache_pages());
@@ -286,8 +288,11 @@ struct page * lookup_swap_cache(swp_entr
page = find_get_page(swap_address_space(entry), entry.val);
- if (page)
+ if (page) {
INC_CACHE_INFO(find_success);
+ if (TestClearPageReadahead(page))
+ atomic_inc(&swapin_readahead_hits);
+ }
INC_CACHE_INFO(find_total);
return page;
@@ -373,6 +378,50 @@ struct page *read_swap_cache_async(swp_e
return found_page;
}
+unsigned long swapin_nr_pages(unsigned long offset)
+{
+ static unsigned long prev_offset;
+ unsigned int pages, max_pages, last_ra;
+ static atomic_t last_readahead_pages;
+
+ max_pages = 1 << ACCESS_ONCE(page_cluster);
+ if (max_pages <= 1)
+ return 1;
+
+ /*
+ * This heuristic has been found to work well on both sequential and
+ * random loads, swapping to hard disk or to SSD: please don't ask
+ * what the "+ 2" means, it just happens to work well, that's all.
+ */
+ pages = atomic_xchg(&swapin_readahead_hits, 0) + 2;
+ if (pages == 2) {
+ /*
+ * We can have no readahead hits to judge by: but must not get
+ * stuck here forever, so check for an adjacent offset instead
+ * (and don't even bother to check whether swap type is same).
+ */
+ if (offset != prev_offset + 1 && offset != prev_offset - 1)
+ pages = 1;
+ prev_offset = offset;
+ } else {
+ unsigned int roundup = 4;
+ while (roundup < pages)
+ roundup <<= 1;
+ pages = roundup;
+ }
+
+ if (pages > max_pages)
+ pages = max_pages;
+
+ /* Don't shrink readahead too fast */
+ last_ra = atomic_read(&last_readahead_pages) / 2;
+ if (pages < last_ra)
+ pages = last_ra;
+ atomic_set(&last_readahead_pages, pages);
+
+ return pages;
+}
+
/**
* swapin_readahead - swap in pages in hope we need them soon
* @entry: swap entry of this memory
@@ -396,11 +445,16 @@ struct page *swapin_readahead(swp_entry_
struct vm_area_struct *vma, unsigned long addr)
{
struct page *page;
- unsigned long offset = swp_offset(entry);
+ unsigned long entry_offset = swp_offset(entry);
+ unsigned long offset = entry_offset;
unsigned long start_offset, end_offset;
- unsigned long mask = (1UL << page_cluster) - 1;
+ unsigned long mask;
struct blk_plug plug;
+ mask = swapin_nr_pages(offset) - 1;
+ if (!mask)
+ goto skip;
+
/* Read a page_cluster sized and aligned cluster around offset. */
start_offset = offset & ~mask;
end_offset = offset | mask;
@@ -414,10 +468,13 @@ struct page *swapin_readahead(swp_entry_
gfp_mask, vma, addr);
if (!page)
continue;
+ if (offset != entry_offset)
+ SetPageReadahead(page);
page_cache_release(page);
}
blk_finish_plug(&plug);
lru_add_drain(); /* Push any new pages onto the LRU now */
+skip:
return read_swap_cache_async(entry, gfp_mask, vma, addr);
}
Attachment:
swapra.png
Description: PNG image
{kind=link}