Hi Ying,
> -----Original Message-----
> From: Huang, Ying <ying.huang@xxxxxxxxx>
> Sent: Sunday, August 18, 2024 10:52 PM
> To: Sridhar, Kanchana P <kanchana.p.sridhar@xxxxxxxxx>
> Cc: linux-kernel@xxxxxxxxxxxxxxx; linux-mm@xxxxxxxxx;
> hannes@xxxxxxxxxxx; yosryahmed@xxxxxxxxxx; nphamcs@xxxxxxxxx;
> ryan.roberts@xxxxxxx; 21cnbao@xxxxxxxxx; akpm@xxxxxxxxxxxxxxxxxxxx;
> Zou, Nanhai <nanhai.zou@xxxxxxxxx>; Feghali, Wajdi K
> <wajdi.k.feghali@xxxxxxxxx>; Gopal, Vinodh <vinodh.gopal@xxxxxxxxx>
> Subject: Re: [PATCH v4 0/4] mm: ZSWAP swap-out of mTHP folios
>
> "Sridhar, Kanchana P" <kanchana.p.sridhar@xxxxxxxxx> writes:
>
> > Hi Ying,
> >
> >> -----Original Message-----
> >> From: Huang, Ying <ying.huang@xxxxxxxxx>
> >> Sent: Sunday, August 18, 2024 8:17 PM
> >> To: Sridhar, Kanchana P <kanchana.p.sridhar@xxxxxxxxx>
> >> Cc: linux-kernel@xxxxxxxxxxxxxxx; linux-mm@xxxxxxxxx;
> >> hannes@xxxxxxxxxxx; yosryahmed@xxxxxxxxxx; nphamcs@xxxxxxxxx;
> >> ryan.roberts@xxxxxxx; 21cnbao@xxxxxxxxx; akpm@linux-
> foundation.org;
> >> Zou, Nanhai <nanhai.zou@xxxxxxxxx>; Feghali, Wajdi K
> >> <wajdi.k.feghali@xxxxxxxxx>; Gopal, Vinodh <vinodh.gopal@xxxxxxxxx>
> >> Subject: Re: [PATCH v4 0/4] mm: ZSWAP swap-out of mTHP folios
> >>
> >> Kanchana P Sridhar <kanchana.p.sridhar@xxxxxxxxx> writes:
> >>
> >> [snip]
> >>
> >> >
> >> > Performance Testing:
> >> > ====================
> >> > Testing of this patch-series was done with the v6.11-rc3 mainline,
> without
> >> > and with this patch-series, on an Intel Sapphire Rapids server,
> >> > dual-socket 56 cores per socket, 4 IAA devices per socket.
> >> >
> >> > The system has 503 GiB RAM, with a 4G SSD as the backing swap device
> for
> >> > ZSWAP. Core frequency was fixed at 2500MHz.
> >> >
> >> > The vm-scalability "usemem" test was run in a cgroup whose
> memory.high
> >> > was fixed. Following a similar methodology as in Ryan Roberts'
> >> > "Swap-out mTHP without splitting" series [2], 70 usemem processes
> were
> >> > run, each allocating and writing 1G of memory:
> >> >
> >> > usemem --init-time -w -O -n 70 1g
> >> >
> >> > Since I was constrained to get the 70 usemem processes to generate
> >> > swapout activity with the 4G SSD, I ended up using different cgroup
> >> > memory.high fixed limits for the experiments with 64K mTHP and 2M
> THP:
> >> >
> >> > 64K mTHP experiments: cgroup memory fixed at 60G
> >> > 2M THP experiments : cgroup memory fixed at 55G
> >> >
> >> > The vm/sysfs stats included after the performance data provide details
> >> > on the swapout activity to SSD/ZSWAP.
> >> >
> >> > Other kernel configuration parameters:
> >> >
> >> > ZSWAP Compressor : LZ4, DEFLATE-IAA
> >> > ZSWAP Allocator : ZSMALLOC
> >> > SWAP page-cluster : 2
> >> >
> >> > In the experiments where "deflate-iaa" is used as the ZSWAP
> compressor,
> >> > IAA "compression verification" is enabled. Hence each IAA compression
> >> > will be decompressed internally by the "iaa_crypto" driver, the crc-s
> >> > returned by the hardware will be compared and errors reported in case
> of
> >> > mismatches. Thus "deflate-iaa" helps ensure better data integrity as
> >> > compared to the software compressors.
> >> >
> >> > Throughput reported by usemem and perf sys time for running the test
> >> > are as follows, averaged across 3 runs:
> >> >
> >> > 64KB mTHP (cgroup memory.high set to 60G):
> >> > ==========================================
> >> > ------------------------------------------------------------------
> >> > | | | | |
> >> > |Kernel | mTHP SWAP-OUT | Throughput | Improvement|
> >> > | | | KB/s | |
> >> > |--------------------|-------------------|------------|------------|
> >> > |v6.11-rc3 mainline | SSD | 335,346 | Baseline |
> >> > |zswap-mTHP-Store | ZSWAP lz4 | 271,558 | -19% |
> >>
> >> zswap throughput is worse than ssd swap? This doesn't look right.
> >
> > I realize it might look that way, however, this is not an apples-to-apples
> comparison,
> > as explained in the latter part of my analysis (after the 2M THP data tables).
> > The primary reason for this is because of running the test under a fixed
> > cgroup memory limit.
> >
> > In the "Before" scenario, mTHP get swapped out to SSD. However, the disk
> swap
> > usage is not accounted towards checking if the cgroup's memory limit has
> been
> > exceeded. Hence there are relatively fewer swap-outs, resulting mainly
> from the
> > 1G allocations from each of the 70 usemem processes working with a 60G
> memory
> > limit on the parent cgroup.
> >
> > However, the picture changes in the "After" scenario. mTHPs will now get
> stored in
> > zswap, which is accounted for in the cgroup's memory.current and counts
> > towards the fixed memory limit in effect for the parent cgroup. As a result,
> when
> > mTHP get stored in zswap, the mTHP compressed data in the zswap zpool
> now
> > count towards the cgroup's active memory and memory limit. This is in
> addition
> > to the 1G allocations from each of the 70 processes.
> >
> > As you can see, this creates more memory pressure on the cgroup, resulting
> in
> > more swap-outs. With lz4 as the zswap compressor, this results in lesser
> throughput
> > wrt "Before".
> >
> > However, with IAA as the zswap compressor, the throughout with zswap
> mTHP is
> > better than "Before" because of better hardware compress latencies, which
> handle
> > the higher swap-out activity without compromising on throughput.
> >
> >>
> >> > |zswap-mTHP-Store | ZSWAP deflate-iaa | 388,154 | 16% |
> >> > |------------------------------------------------------------------|
> >> > | | | | |
> >> > |Kernel | mTHP SWAP-OUT | Sys time | Improvement|
> >> > | | | sec | |
> >> > |--------------------|-------------------|------------|------------|
> >> > |v6.11-rc3 mainline | SSD | 91.37 | Baseline |
> >> > |zswap-mTHP=Store | ZSWAP lz4 | 265.43 | -191% |
> >> > |zswap-mTHP-Store | ZSWAP deflate-iaa | 235.60 | -158% |
> >> > ------------------------------------------------------------------
> >> >
> >> > -----------------------------------------------------------------------
> >> > | VMSTATS, mTHP ZSWAP/SSD stats| v6.11-rc3 | zswap-mTHP |
> zswap-
> >> mTHP |
> >> > | | mainline | Store | Store |
> >> > | | | lz4 | deflate-iaa |
> >> > |-----------------------------------------------------------------------|
> >> > | pswpin | 0 | 0 | 0 |
> >> > | pswpout | 174,432 | 0 | 0 |
> >> > | zswpin | 703 | 534 | 721 |
> >> > | zswpout | 1,501 | 1,491,654 | 1,398,805 |
> >>
> >> It appears that the number of swapped pages for zswap is much larger
> >> than that of SSD swap. Why? I guess this is why zswap throughput is
> >> worse.
> >
> > Your observation is correct. I hope the above explanation helps as to the
> > reasoning behind this.
>
> Before:
> (174432 + 1501) * 4 / 1024 = 687.2 MB
>
> After:
> 1491654 * 4.0 / 1024 = 5826.8 MB
>
> From your previous words, 10GB memory should be swapped out.
>
> Even if the average compression ratio is 0, the swap-out count of zswap
> should be about 100% more than that of SSD. However, the ratio here
> appears unreasonable.
Excellent point! In order to understand this better myself, I ran usemem with
1 process that tries to allocate 58G:
cgroup memory.high = 60,000,000,000
usemem --init-time -w -O -n 1 58g
usemem -n 1 58g Before After
----------------------------------------------
pswpout 586,352 0
zswpout 1,005 1,042,963
----------------------------------------------
Total swapout 587,357 1,042,963
----------------------------------------------
In the case where the cgroup has only 1 process, your rationale above applies
(more or less). This shows the stats collected every 100 micro-seconds from the critical
section of the workload right before the memory limit is reached (Before and After):
===========================================================================
BEFORE zswap_store mTHP:
===========================================================================
cgroup_memory cgroup_memory zswap_pool zram_compr
w/o zswap _total_size _data_size
---------------------------------------------------------------------------
59,999,600,640 59,999,600,640 0 74
59,999,911,936 59,999,911,936 0 14,139,441
60,000,083,968 59,997,634,560 2,449,408 53,448,205
59,999,952,896 59,997,503,488 2,449,408 93,477,490
60,000,083,968 59,997,634,560 2,449,408 133,152,754
60,000,083,968 59,997,634,560 2,449,408 172,628,328
59,999,952,896 59,997,503,488 2,449,408 212,760,840
60,000,083,968 59,997,634,560 2,449,408 251,999,675
60,000,083,968 59,997,634,560 2,449,408 291,058,130
60,000,083,968 59,997,634,560 2,449,408 329,655,206
59,999,793,152 59,997,343,744 2,449,408 368,938,904
59,999,924,224 59,997,474,816 2,449,408 408,652,723
59,999,924,224 59,997,474,816 2,449,408 447,830,071
60,000,055,296 59,997,605,888 2,449,408 487,776,082
59,999,924,224 59,997,474,816 2,449,408 526,826,360
60,000,055,296 59,997,605,888 2,449,408 566,193,520
60,000,055,296 59,997,605,888 2,449,408 604,625,879
60,000,055,296 59,997,605,888 2,449,408 642,545,706
59,999,924,224 59,997,474,816 2,449,408 681,958,173
59,999,924,224 59,997,474,816 2,449,408 721,908,162
59,999,924,224 59,997,474,816 2,449,408 761,935,307
59,999,924,224 59,997,474,816 2,449,408 802,014,594
59,999,924,224 59,997,474,816 2,449,408 842,087,656
59,999,924,224 59,997,474,816 2,449,408 883,889,588
59,999,924,224 59,997,474,816 2,449,408 804,458,184
59,999,793,152 59,997,343,744 2,449,408 94,150,548
54,938,513,408 54,936,064,000 2,449,408 172,644
29,492,523,008 29,490,073,600 2,449,408 172,644
3,465,621,504 3,463,172,096 2,449,408 131,457
---------------------------------------------------------------------------
===========================================================================
AFTER zswap_store mTHP:
===========================================================================
cgroup_memory cgroup_memory zswap_pool
w/o zswap _total_size
---------------------------------------------------------------------------
55,578,234,880 55,578,234,880 0
56,104,095,744 56,104,095,744 0
56,644,898,816 56,644,898,816 0
57,184,653,312 57,184,653,312 0
57,706,057,728 57,706,057,728 0
58,226,937,856 58,226,937,856 0
58,747,293,696 58,747,293,696 0
59,275,776,000 59,275,776,000 0
59,793,772,544 59,793,772,544 0
60,000,141,312 60,000,141,312 0
59,999,956,992 59,999,956,992 0
60,000,169,984 60,000,169,984 0
59,999,907,840 59,951,226,880 48,680,960
60,000,169,984 59,900,010,496 100,159,488
60,000,169,984 59,848,007,680 152,162,304
60,000,169,984 59,795,513,344 204,656,640
59,999,907,840 59,743,477,760 256,430,080
60,000,038,912 59,692,097,536 307,941,376
60,000,169,984 59,641,208,832 358,961,152
60,000,038,912 59,589,992,448 410,046,464
60,000,169,984 59,539,005,440 461,164,544
60,000,169,984 59,487,657,984 512,512,000
60,000,038,912 59,434,868,736 565,170,176
60,000,038,912 59,383,259,136 616,779,776
60,000,169,984 59,331,518,464 668,651,520
60,000,169,984 59,279,843,328 720,326,656
60,000,169,984 59,228,626,944 771,543,040
59,999,907,840 59,176,984,576 822,923,264
60,000,038,912 59,124,326,400 875,712,512
60,000,169,984 59,072,454,656 927,715,328
60,000,169,984 59,020,156,928 980,013,056
60,000,038,912 58,966,974,464 1,033,064,448
60,000,038,912 58,913,628,160 1,086,410,752
60,000,038,912 58,858,840,064 1,141,198,848
60,000,169,984 58,804,314,112 1,195,855,872
59,999,907,840 58,748,936,192 1,250,971,648
60,000,169,984 58,695,131,136 1,305,038,848
60,000,169,984 58,642,800,640 1,357,369,344
60,000,169,984 58,589,782,016 1,410,387,968
60,000,038,912 58,535,124,992 1,464,913,920
60,000,169,984 58,482,925,568 1,517,244,416
60,000,169,984 58,429,775,872 1,570,394,112
60,000,038,912 58,376,658,944 1,623,379,968
60,000,169,984 58,323,247,104 1,676,922,880
60,000,038,912 58,271,113,216 1,728,925,696
60,000,038,912 58,216,292,352 1,783,746,560
60,000,038,912 58,164,289,536 1,835,749,376
60,000,038,912 58,112,090,112 1,887,948,800
60,000,038,912 58,058,350,592 1,941,688,320
59,999,907,840 58,004,971,520 1,994,936,320
60,000,169,984 57,953,165,312 2,047,004,672
59,999,907,840 57,900,277,760 2,099,630,080
60,000,038,912 57,847,586,816 2,152,452,096
60,000,169,984 57,793,421,312 2,206,748,672
59,999,907,840 57,741,582,336 2,258,325,504
60,012,826,624 57,734,840,320 2,277,986,304
60,098,793,472 57,820,348,416 2,278,445,056
60,176,334,848 57,897,889,792 2,278,445,056
60,269,826,048 57,991,380,992 2,278,445,056
59,687,481,344 57,851,977,728 1,835,503,616
59,049,836,544 57,888,108,544 1,161,728,000
58,406,068,224 57,929,551,872 476,516,352
43,837,923,328 43,837,919,232 4,096
18,124,546,048 18,124,541,952 4,096
2,846,720 2,842,624 4,096
---------------------------------------------------------------------------
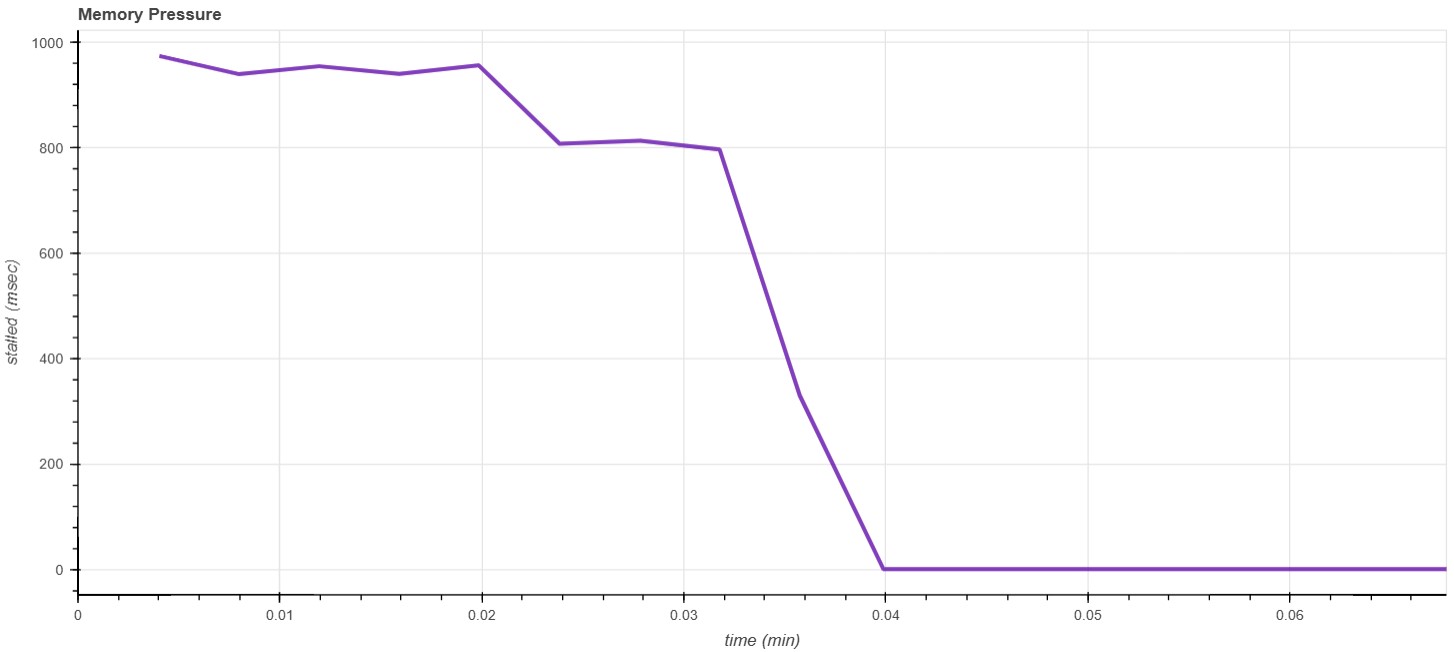
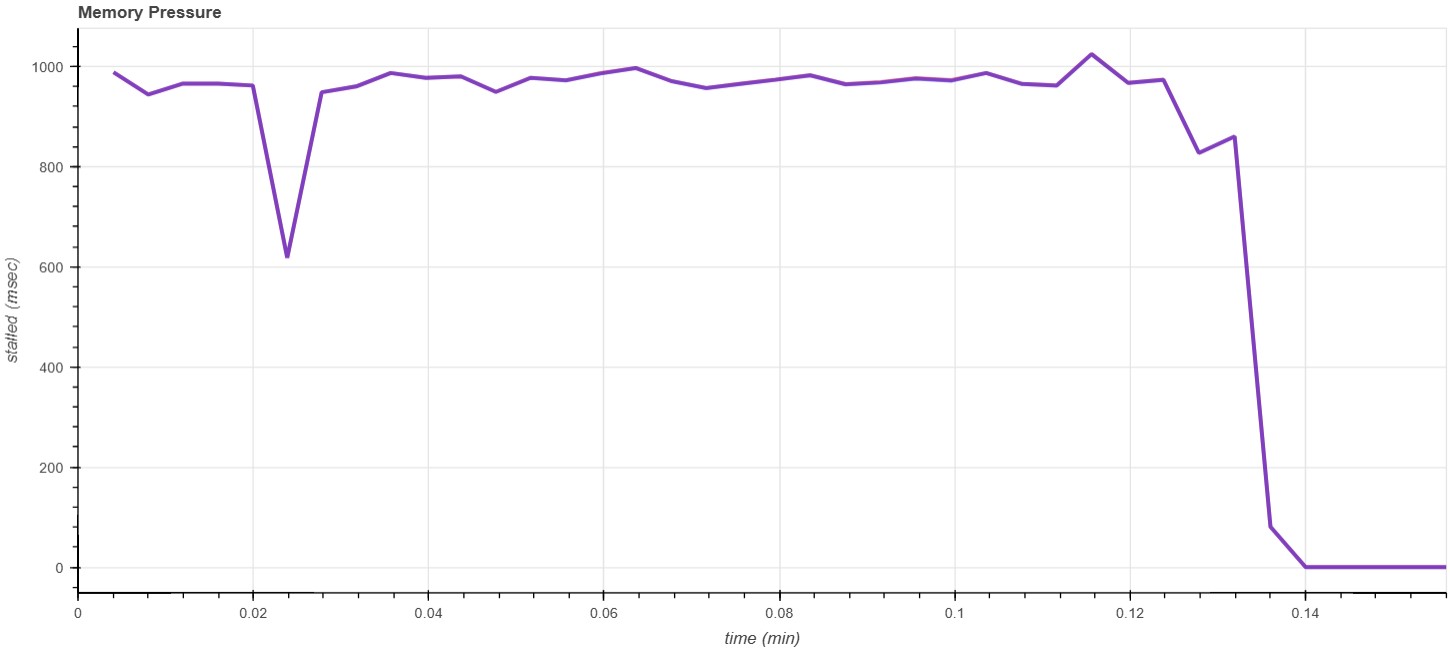
I have also attached plots of the memory pressure reported by PSI. Both these sets
of data should give a sense of the added memory pressure on the cgroup because of
zswap mTHP stores. The data shows that the cgroup is over the limit much more
frequently in the "After" than in "Before". However, the rationale that you suggested
seems more reasonable and apparent in the 1 process case.
However, with 70 processes trying to allocate 1G, things get more complicated.
These are the functions that should provide more clarity:
[1] mm/memcontrol.c: mem_cgroup_handle_over_high().
[2] mm/memcontrol.c: try_charge_memcg().
[3] include/linux/resume_user_mode.h: resume_user_mode_work().
At a high level, when zswap mTHP compressed pool usage starts counting towards
cgroup.memory.current, there are two inter-related effects occurring that ultimately
cause more reclaim to happen:
1) When each process reclaims a folio and zswap_store() writes out each page in
the folio, it charges the compressed size to the memcg
"obj_cgroup_charge_zswap(objcg, entry->length);". This calls [2] and sets
current->memcg_nr_pages_over_high if the limit is exceeded. The comments
towards the end of [2] are relevant.
2) When each of the processes returns from a page-fault, it checks if the
cgroup memory usage is over the limit in [3], and if so, it will trigger
reclaim.
I confirmed that in the case of usemem, all calls to [1] occur from the code path in [3].
However, my takeaway from this is that the more reclaim that results in zswap_store(),
for e.g., from mTHP folios, there is higher likelihood of overage recorded per-process in
current->memcg_nr_pages_over_high, which could potentially be causing each
process to reclaim memory, even if it is possible that the swapout from a few of
the 70 processes could have brought the parent cgroup under the limit.
Please do let me know if you have any other questions. Appreciate your feedback
and comments.
Thanks,
Kanchana
>
> --
> Best Regards,
> Huang, Ying
>
> > Thanks,
> > Kanchana
> >
> >>
> >> > |-----------------------------------------------------------------------|
> >> > | thp_swpout | 0 | 0 | 0 |
> >> > | thp_swpout_fallback | 0 | 0 | 0 |
> >> > | pgmajfault | 3,364 | 3,650 | 3,431 |
> >> > |-----------------------------------------------------------------------|
> >> > | hugepages-64kB/stats/zswpout | | 63,200 | 63,244 |
> >> > |-----------------------------------------------------------------------|
> >> > | hugepages-64kB/stats/swpout | 10,902 | 0 | 0 |
> >> > -----------------------------------------------------------------------
> >> >
> >>
> >> [snip]
> >>
> >> --
> >> Best Regards,
> >> Huang, Ying
Attachment:
usemem_n1_Before.jpg
Description: usemem_n1_Before.jpg
Attachment:
usemem_n1_After.jpg
Description: usemem_n1_After.jpg

{kind=link}
{kind=link}